@ -0,0 +1,255 @@ |
|||||
|
import os |
||||
|
import sys |
||||
|
import re |
||||
|
import json |
||||
|
from openai import OpenAI |
||||
|
|
||||
|
client = OpenAI(api_key=os.environ['OPENAI_API_KEY']) |
||||
|
|
||||
|
# Regex patterns as constants |
||||
|
SEO_BLOCK_PATTERN = r'```+json\s*//\[doc-seo\]\s*(\{.*?\})\s*```+' |
||||
|
SEO_BLOCK_WITH_BACKTICKS_PATTERN = r'(```+)json\s*//\[doc-seo\]\s*(\{.*?\})\s*\1' |
||||
|
|
||||
|
def has_seo_description(content): |
||||
|
"""Check if content already has SEO description with Description field""" |
||||
|
match = re.search(SEO_BLOCK_PATTERN, content, flags=re.DOTALL) |
||||
|
|
||||
|
if not match: |
||||
|
return False |
||||
|
|
||||
|
try: |
||||
|
json_str = match.group(1) |
||||
|
seo_data = json.loads(json_str) |
||||
|
return 'Description' in seo_data and seo_data['Description'] |
||||
|
except json.JSONDecodeError: |
||||
|
return False |
||||
|
|
||||
|
def has_seo_block(content): |
||||
|
"""Check if content has any SEO block (with or without Description)""" |
||||
|
return bool(re.search(SEO_BLOCK_PATTERN, content, flags=re.DOTALL)) |
||||
|
|
||||
|
def remove_seo_blocks(content): |
||||
|
"""Remove all SEO description blocks from content""" |
||||
|
return re.sub(SEO_BLOCK_PATTERN + r'\s*', '', content, flags=re.DOTALL) |
||||
|
|
||||
|
def is_content_too_short(content, min_length=200): |
||||
|
"""Check if content is less than minimum length (excluding SEO blocks)""" |
||||
|
clean_content = remove_seo_blocks(content) |
||||
|
return len(clean_content.strip()) < min_length |
||||
|
|
||||
|
def get_content_preview(content, max_length=1000): |
||||
|
"""Get preview of content for OpenAI (excluding SEO blocks)""" |
||||
|
clean_content = remove_seo_blocks(content) |
||||
|
return clean_content[:max_length].strip() |
||||
|
|
||||
|
def escape_json_string(text): |
||||
|
"""Escape special characters for JSON""" |
||||
|
return text.replace('\\', '\\\\').replace('"', '\\"').replace('\n', '\\n') |
||||
|
|
||||
|
def create_seo_block(description): |
||||
|
"""Create a new SEO block with the given description""" |
||||
|
escaped_desc = escape_json_string(description) |
||||
|
return f'''```json |
||||
|
//[doc-seo] |
||||
|
{{ |
||||
|
"Description": "{escaped_desc}" |
||||
|
}} |
||||
|
``` |
||||
|
|
||||
|
''' |
||||
|
|
||||
|
def generate_description(content, filename): |
||||
|
"""Generate SEO description using OpenAI""" |
||||
|
try: |
||||
|
preview = get_content_preview(content) |
||||
|
|
||||
|
response = client.chat.completions.create( |
||||
|
model="gpt-4o-mini", |
||||
|
messages=[ |
||||
|
{"role": "system", "content": """Create a short and engaging summary (1–2 sentences) for sharing this documentation link on Discord, LinkedIn, Reddit, Twitter and Facebook. Clearly describe what the page explains or teaches. |
||||
|
Highlight the value for developers using ABP Framework. |
||||
|
Be written in a friendly and professional tone. |
||||
|
Stay under 150 characters. |
||||
|
--> https://abp.io/docs/latest <--"""}, |
||||
|
{"role": "user", "content": f"""Generate a concise, informative meta description for this documentation page. |
||||
|
|
||||
|
File: {filename} |
||||
|
Content Preview: |
||||
|
{preview} |
||||
|
|
||||
|
Requirements: |
||||
|
- Maximum 150 characters |
||||
|
|
||||
|
Generate only the description text, nothing else:"""} |
||||
|
], |
||||
|
max_tokens=150, |
||||
|
temperature=0.7 |
||||
|
) |
||||
|
|
||||
|
description = response.choices[0].message.content.strip() |
||||
|
return description |
||||
|
except Exception as e: |
||||
|
print(f"❌ Error generating description: {e}") |
||||
|
return f"Learn about {os.path.splitext(filename)[0]} in ABP Framework documentation." |
||||
|
|
||||
|
def update_seo_description(content, description): |
||||
|
"""Update existing SEO block with new description""" |
||||
|
match = re.search(SEO_BLOCK_WITH_BACKTICKS_PATTERN, content, flags=re.DOTALL) |
||||
|
|
||||
|
if not match: |
||||
|
return None |
||||
|
|
||||
|
backticks = match.group(1) |
||||
|
json_str = match.group(2) |
||||
|
|
||||
|
try: |
||||
|
seo_data = json.loads(json_str) |
||||
|
seo_data['Description'] = description |
||||
|
updated_json = json.dumps(seo_data, indent=4, ensure_ascii=False) |
||||
|
|
||||
|
new_block = f'''{backticks}json |
||||
|
//[doc-seo] |
||||
|
{updated_json} |
||||
|
{backticks}''' |
||||
|
|
||||
|
return re.sub(SEO_BLOCK_WITH_BACKTICKS_PATTERN, new_block, content, count=1, flags=re.DOTALL) |
||||
|
except json.JSONDecodeError: |
||||
|
return None |
||||
|
|
||||
|
def add_seo_description(content, description): |
||||
|
"""Add or update SEO description in content""" |
||||
|
# Try to update existing block first |
||||
|
updated_content = update_seo_description(content, description) |
||||
|
if updated_content: |
||||
|
return updated_content |
||||
|
|
||||
|
# No existing block or update failed, add new block at the beginning |
||||
|
return create_seo_block(description) + content |
||||
|
|
||||
|
def is_file_ignored(filepath, ignored_folders): |
||||
|
"""Check if file is in an ignored folder""" |
||||
|
path_parts = filepath.split('/') |
||||
|
return any(ignored in path_parts for ignored in ignored_folders) |
||||
|
|
||||
|
def get_changed_files(): |
||||
|
"""Get changed files from command line or environment variable""" |
||||
|
if len(sys.argv) > 1: |
||||
|
return sys.argv[1:] |
||||
|
|
||||
|
changed_files_str = os.environ.get('CHANGED_FILES', '') |
||||
|
return [f.strip() for f in changed_files_str.strip().split('\n') if f.strip()] |
||||
|
|
||||
|
def process_file(filepath, ignored_folders): |
||||
|
"""Process a single markdown file. Returns (processed, skipped, skip_reason)""" |
||||
|
if not filepath.endswith('.md'): |
||||
|
return False, False, None |
||||
|
|
||||
|
# Check if file is in ignored folder |
||||
|
if is_file_ignored(filepath, ignored_folders): |
||||
|
print(f"📄 Processing: {filepath}") |
||||
|
print(f" 🚫 Skipped (ignored folder)\n") |
||||
|
return False, True, 'ignored' |
||||
|
|
||||
|
print(f"📄 Processing: {filepath}") |
||||
|
|
||||
|
try: |
||||
|
# Read file with original line endings |
||||
|
with open(filepath, 'r', encoding='utf-8', newline='') as f: |
||||
|
content = f.read() |
||||
|
|
||||
|
# Check if content is too short |
||||
|
if is_content_too_short(content): |
||||
|
print(f" ⏭️ Skipped (content less than 200 characters)\n") |
||||
|
return False, True, 'too_short' |
||||
|
|
||||
|
# Check if already has SEO description |
||||
|
if has_seo_description(content): |
||||
|
print(f" ⏭️ Skipped (already has SEO description)\n") |
||||
|
return False, True, 'has_description' |
||||
|
|
||||
|
# Generate description |
||||
|
filename = os.path.basename(filepath) |
||||
|
print(f" 🤖 Generating description...") |
||||
|
description = generate_description(content, filename) |
||||
|
print(f" 💡 Generated: {description}") |
||||
|
|
||||
|
# Add or update SEO description |
||||
|
if has_seo_block(content): |
||||
|
print(f" 🔄 Updating existing SEO block...") |
||||
|
else: |
||||
|
print(f" ➕ Adding new SEO block...") |
||||
|
|
||||
|
updated_content = add_seo_description(content, description) |
||||
|
|
||||
|
# Write back (preserving line endings) |
||||
|
with open(filepath, 'w', encoding='utf-8', newline='') as f: |
||||
|
f.write(updated_content) |
||||
|
|
||||
|
print(f" ✅ Updated successfully\n") |
||||
|
return True, False, None |
||||
|
|
||||
|
except Exception as e: |
||||
|
print(f" ❌ Error: {e}\n") |
||||
|
return False, False, None |
||||
|
|
||||
|
def save_statistics(processed_count, skipped_count, skipped_too_short, skipped_ignored): |
||||
|
"""Save processing statistics to file""" |
||||
|
try: |
||||
|
with open('/tmp/seo_stats.txt', 'w') as f: |
||||
|
f.write(f"{processed_count}\n{skipped_count}\n{skipped_too_short}\n{skipped_ignored}") |
||||
|
except Exception as e: |
||||
|
print(f"⚠️ Warning: Could not save statistics: {e}") |
||||
|
|
||||
|
def save_updated_files(updated_files): |
||||
|
"""Save list of updated files""" |
||||
|
try: |
||||
|
with open('/tmp/seo_updated_files.txt', 'w') as f: |
||||
|
f.write('\n'.join(updated_files)) |
||||
|
except Exception as e: |
||||
|
print(f"⚠️ Warning: Could not save updated files list: {e}") |
||||
|
|
||||
|
def main(): |
||||
|
# Get ignored folders from environment |
||||
|
IGNORED_FOLDERS_STR = os.environ.get('IGNORED_FOLDERS', 'Blog-Posts,Community-Articles,_deleted,_resources') |
||||
|
IGNORED_FOLDERS = [folder.strip() for folder in IGNORED_FOLDERS_STR.split(',') if folder.strip()] |
||||
|
|
||||
|
# Get changed files |
||||
|
changed_files = get_changed_files() |
||||
|
|
||||
|
# Statistics |
||||
|
processed_count = 0 |
||||
|
skipped_count = 0 |
||||
|
skipped_too_short = 0 |
||||
|
skipped_ignored = 0 |
||||
|
updated_files = [] |
||||
|
|
||||
|
print("🤖 Processing changed markdown files...\n") |
||||
|
print(f"� Ignored folders: {', '.join(IGNORED_FOLDERS)}\n") |
||||
|
|
||||
|
# Process each file |
||||
|
for filepath in changed_files: |
||||
|
processed, skipped, skip_reason = process_file(filepath, IGNORED_FOLDERS) |
||||
|
|
||||
|
if processed: |
||||
|
processed_count += 1 |
||||
|
updated_files.append(filepath) |
||||
|
elif skipped: |
||||
|
skipped_count += 1 |
||||
|
if skip_reason == 'too_short': |
||||
|
skipped_too_short += 1 |
||||
|
elif skip_reason == 'ignored': |
||||
|
skipped_ignored += 1 |
||||
|
|
||||
|
# Print summary |
||||
|
print(f"\n📊 Summary:") |
||||
|
print(f" ✅ Updated: {processed_count}") |
||||
|
print(f" ⏭️ Skipped (total): {skipped_count}") |
||||
|
print(f" ⏭️ Skipped (too short): {skipped_too_short}") |
||||
|
print(f" 🚫 Skipped (ignored folder): {skipped_ignored}") |
||||
|
|
||||
|
# Save statistics |
||||
|
save_statistics(processed_count, skipped_count, skipped_too_short, skipped_ignored) |
||||
|
save_updated_files(updated_files) |
||||
|
|
||||
|
if __name__ == '__main__': |
||||
|
main() |
||||
@ -0,0 +1,210 @@ |
|||||
|
name: Auto Add SEO Descriptions |
||||
|
|
||||
|
on: |
||||
|
pull_request: |
||||
|
paths: |
||||
|
- 'docs/en/**/*.md' |
||||
|
branches: |
||||
|
- 'rel-*' |
||||
|
- 'dev' |
||||
|
types: [closed] |
||||
|
|
||||
|
jobs: |
||||
|
add-seo-descriptions: |
||||
|
if: | |
||||
|
github.event.pull_request.merged == true && |
||||
|
!startsWith(github.event.pull_request.head.ref, 'auto-docs-seo/') |
||||
|
runs-on: ubuntu-latest |
||||
|
permissions: |
||||
|
contents: write |
||||
|
pull-requests: write |
||||
|
|
||||
|
steps: |
||||
|
- name: Checkout code |
||||
|
uses: actions/checkout@v4 |
||||
|
with: |
||||
|
ref: ${{ github.event.pull_request.base.ref }} |
||||
|
fetch-depth: 0 |
||||
|
token: ${{ secrets.GITHUB_TOKEN }} |
||||
|
|
||||
|
- name: Setup Python |
||||
|
uses: actions/setup-python@v5 |
||||
|
with: |
||||
|
python-version: '3.11' |
||||
|
|
||||
|
- name: Install dependencies |
||||
|
run: | |
||||
|
pip install openai |
||||
|
|
||||
|
- name: Get changed markdown files from merged PR using GitHub API |
||||
|
id: changed-files |
||||
|
uses: actions/github-script@v7 |
||||
|
with: |
||||
|
script: | |
||||
|
const prNumber = ${{ github.event.pull_request.number }}; |
||||
|
|
||||
|
// Get all files changed in the PR with pagination |
||||
|
const allFiles = []; |
||||
|
let page = 1; |
||||
|
let hasMore = true; |
||||
|
|
||||
|
while (hasMore) { |
||||
|
const { data: files } = await github.rest.pulls.listFiles({ |
||||
|
owner: context.repo.owner, |
||||
|
repo: context.repo.repo, |
||||
|
pull_number: prNumber, |
||||
|
per_page: 100, |
||||
|
page: page |
||||
|
}); |
||||
|
|
||||
|
allFiles.push(...files); |
||||
|
hasMore = files.length === 100; |
||||
|
page++; |
||||
|
} |
||||
|
|
||||
|
console.log(`Total files changed in PR: ${allFiles.length}`); |
||||
|
|
||||
|
// Filter for only added/modified markdown files in docs/en/ |
||||
|
const changedMdFiles = allFiles |
||||
|
.filter(file => |
||||
|
(file.status === 'added' || file.status === 'modified') && |
||||
|
file.filename.startsWith('docs/en/') && |
||||
|
file.filename.endsWith('.md') |
||||
|
) |
||||
|
.map(file => file.filename); |
||||
|
|
||||
|
console.log(`\nFound ${changedMdFiles.length} added/modified markdown files in docs/en/:`); |
||||
|
changedMdFiles.forEach(file => console.log(` - ${file}`)); |
||||
|
|
||||
|
// Write to environment file for next steps |
||||
|
const fs = require('fs'); |
||||
|
fs.writeFileSync(process.env.GITHUB_OUTPUT, |
||||
|
`any_changed=${changedMdFiles.length > 0 ? 'true' : 'false'}\n` + |
||||
|
`all_changed_files=${changedMdFiles.join(' ')}\n`, |
||||
|
{ flag: 'a' } |
||||
|
); |
||||
|
|
||||
|
return changedMdFiles; |
||||
|
|
||||
|
- name: Create new branch for SEO updates |
||||
|
if: steps.changed-files.outputs.any_changed == 'true' |
||||
|
run: | |
||||
|
git config --local user.email "github-actions[bot]@users.noreply.github.com" |
||||
|
git config --local user.name "github-actions[bot]" |
||||
|
|
||||
|
# Create new branch from current base branch (which already has merged files) |
||||
|
BRANCH_NAME="auto-docs-seo/${{ github.event.pull_request.number }}" |
||||
|
git checkout -b $BRANCH_NAME |
||||
|
echo "BRANCH_NAME=$BRANCH_NAME" >> $GITHUB_ENV |
||||
|
|
||||
|
echo "✅ Created branch: $BRANCH_NAME" |
||||
|
echo "" |
||||
|
echo "📝 Files to process for SEO descriptions:" |
||||
|
for file in ${{ steps.changed-files.outputs.all_changed_files }}; do |
||||
|
if [ -f "$file" ]; then |
||||
|
echo " ✓ $file" |
||||
|
else |
||||
|
echo " ✗ $file (not found)" |
||||
|
fi |
||||
|
done |
||||
|
|
||||
|
- name: Process changed files and add SEO descriptions |
||||
|
if: steps.changed-files.outputs.any_changed == 'true' |
||||
|
env: |
||||
|
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }} |
||||
|
IGNORED_FOLDERS: ${{ vars.DOCS_SEO_IGNORED_FOLDERS }} |
||||
|
CHANGED_FILES: ${{ steps.changed-files.outputs.all_changed_files }} |
||||
|
run: | |
||||
|
python3 .github/scripts/add_seo_descriptions.py |
||||
|
|
||||
|
|
||||
|
- name: Commit and push changes |
||||
|
if: steps.changed-files.outputs.any_changed == 'true' |
||||
|
run: | |
||||
|
git add -A docs/en/ |
||||
|
|
||||
|
if git diff --staged --quiet; then |
||||
|
echo "No changes to commit" |
||||
|
echo "has_commits=false" >> $GITHUB_ENV |
||||
|
else |
||||
|
BRANCH_NAME="auto-docs-seo/${{ github.event.pull_request.number }}" |
||||
|
git commit -m "docs: Add SEO descriptions to modified documentation files" -m "Related to PR #${{ github.event.pull_request.number }}" |
||||
|
git push origin $BRANCH_NAME |
||||
|
echo "has_commits=true" >> $GITHUB_ENV |
||||
|
echo "BRANCH_NAME=$BRANCH_NAME" >> $GITHUB_ENV |
||||
|
fi |
||||
|
|
||||
|
- name: Create Pull Request |
||||
|
if: env.has_commits == 'true' |
||||
|
uses: actions/github-script@v7 |
||||
|
with: |
||||
|
script: | |
||||
|
const fs = require('fs'); |
||||
|
const stats = fs.readFileSync('/tmp/seo_stats.txt', 'utf8').split('\n'); |
||||
|
const processedCount = parseInt(stats[0]) || 0; |
||||
|
const skippedCount = parseInt(stats[1]) || 0; |
||||
|
const skippedTooShort = parseInt(stats[2]) || 0; |
||||
|
const skippedIgnored = parseInt(stats[3]) || 0; |
||||
|
const prNumber = ${{ github.event.pull_request.number }}; |
||||
|
const baseRef = '${{ github.event.pull_request.base.ref }}'; |
||||
|
const branchName = `auto-docs-seo/${prNumber}`; |
||||
|
|
||||
|
if (processedCount > 0) { |
||||
|
// Read the actually updated files list (not all changed files) |
||||
|
const updatedFilesStr = fs.readFileSync('/tmp/seo_updated_files.txt', 'utf8'); |
||||
|
const updatedFiles = updatedFilesStr.trim().split('\n').filter(f => f.trim()); |
||||
|
|
||||
|
let prBody = '🤖 **Automated SEO Descriptions**\n\n'; |
||||
|
prBody += `This PR automatically adds SEO descriptions to documentation files that were modified in PR #${prNumber}.\n\n`; |
||||
|
prBody += '## 📊 Summary\n'; |
||||
|
prBody += `- ✅ **Updated:** ${processedCount} file(s)\n`; |
||||
|
prBody += `- ⏭️ **Skipped (total):** ${skippedCount} file(s)\n`; |
||||
|
if (skippedTooShort > 0) { |
||||
|
prBody += ` - ⏭️ Content < 200 chars: ${skippedTooShort} file(s)\n`; |
||||
|
} |
||||
|
if (skippedIgnored > 0) { |
||||
|
prBody += ` - 🚫 Ignored folders: ${skippedIgnored} file(s)\n`; |
||||
|
} |
||||
|
prBody += '\n## 📝 Modified Files\n'; |
||||
|
prBody += updatedFiles.slice(0, 20).map(f => `- \`${f}\``).join('\n'); |
||||
|
if (updatedFiles.length > 20) { |
||||
|
prBody += `\n- ... and ${updatedFiles.length - 20} more`; |
||||
|
} |
||||
|
prBody += '\n\n## 🔧 Details\n'; |
||||
|
prBody += `- **Related PR:** #${prNumber}\n\n`; |
||||
|
prBody += 'These descriptions were automatically generated to improve SEO and search engine visibility. 🚀'; |
||||
|
|
||||
|
const { data: pr } = await github.rest.pulls.create({ |
||||
|
owner: context.repo.owner, |
||||
|
repo: context.repo.repo, |
||||
|
title: `docs: Add SEO descriptions (from PR ${prNumber})`, |
||||
|
head: branchName, |
||||
|
base: baseRef, |
||||
|
body: prBody |
||||
|
}); |
||||
|
|
||||
|
console.log(`✅ Created PR: ${pr.html_url}`); |
||||
|
|
||||
|
// Add reviewers to the PR (from GitHub variable) |
||||
|
const reviewersStr = '${{ vars.DOCS_SEO_REVIEWERS || '' }}'; |
||||
|
const reviewers = reviewersStr.split(',').map(r => r.trim()).filter(r => r); |
||||
|
|
||||
|
if (reviewers.length === 0) { |
||||
|
console.log('⚠️ No reviewers specified in DOCS_SEO_REVIEWERS variable.'); |
||||
|
return; |
||||
|
} |
||||
|
|
||||
|
try { |
||||
|
await github.rest.pulls.requestReviewers({ |
||||
|
owner: context.repo.owner, |
||||
|
repo: context.repo.repo, |
||||
|
pull_number: pr.number, |
||||
|
reviewers: reviewers, |
||||
|
team_reviewers: [] |
||||
|
}); |
||||
|
console.log(`✅ Added reviewers (${reviewers.join(', ')}) to PR ${pr.number}`); |
||||
|
} catch (error) { |
||||
|
console.log(`⚠️ Could not add reviewers: ${error.message}`); |
||||
|
} |
||||
|
} |
||||
|
|
||||
@ -0,0 +1,20 @@ |
|||||
|
### ABP is Sponsoring .NET Conf 2025\! |
||||
|
|
||||
|
We are very excited to announce that **ABP is a proud sponsor of .NET Conf 2025\!** This year marks the 15th online conference, celebrating the launch of .NET 10 and bringing together the global .NET community for three days\! |
||||
|
|
||||
|
Mark your calendar for **November 11th-13th** because you do not want to miss the biggest .NET virtual event of the year\! |
||||
|
|
||||
|
### About .NET Conf |
||||
|
|
||||
|
.NET Conference has always been **a free, virtual event, creating a world-class, engaging experience for developers** across the globe. This year, the conference is bigger than ever, drawing over 100 thousand live viewers and sponsoring hundreds of local community events worldwide\! |
||||
|
|
||||
|
### What to Expect |
||||
|
|
||||
|
**The .NET 10 Launch:** The event kicks off with the official release and deep-dive into the newest features of .NET 10\. |
||||
|
|
||||
|
**Three Days of Live Content:** Over the course of the event you'll get a wide selection of live sessions featuring speakers from the community and members of the .NET team. |
||||
|
|
||||
|
### Chance to Win a License\! |
||||
|
|
||||
|
As a proud sponsor, ABP is giving back to the community\! We are giving away one **ABP Personal License for a full year** to a lucky attendee of .NET Conf 2025\! To enter for a chance to win, simply register for the event [**here.**](https://www.dotnetconf.net/) |
||||
|
|
||||
@ -0,0 +1,277 @@ |
|||||
|
# Repository Pattern in the ASP.NET Core |
||||
|
|
||||
|
If you’ve built a .NET app with a database, you’ve likely used Entity Framework, Dapper, or ADO.NET. They’re useful tools; still, when they live inside your business logic or controllers, the code can become harder to keep tidy and to test. |
||||
|
|
||||
|
That’s where the **Repository Pattern** comes in. |
||||
|
|
||||
|
At its core, the Repository Pattern acts as a **middle layer between your domain and data access logic**. It abstracts the way you store and retrieve data, giving your application a clean separation of concerns: |
||||
|
|
||||
|
* **Separation of Concerns:** Business logic doesn’t depend on the database. |
||||
|
* **Easier Testing:** You can replace the repository with a fake or mock during unit tests. |
||||
|
* **Flexibility:** You can switch data sources (e.g., from SQL to MongoDB) without touching business logic. |
||||
|
|
||||
|
Let’s see how this works with a simple example. |
||||
|
|
||||
|
## A Simple Example with Product Repository |
||||
|
|
||||
|
Imagine we’re building a small e-commerce app. We’ll start by defining a repository interface for managing products. |
||||
|
|
||||
|
You can find the complete sample code in this GitHub repository: |
||||
|
|
||||
|
https://github.com/m-aliozkaya/RepositoryPattern |
||||
|
|
||||
|
### Domain model and context |
||||
|
|
||||
|
We start with a single entity and a matching `DbContext`. |
||||
|
|
||||
|
`Product.cs` |
||||
|
|
||||
|
```csharp |
||||
|
using System.ComponentModel.DataAnnotations; |
||||
|
|
||||
|
namespace RepositoryPattern.Web.Models; |
||||
|
|
||||
|
public class Product |
||||
|
{ |
||||
|
public int Id { get; set; } |
||||
|
|
||||
|
[Required, StringLength(64)] |
||||
|
public string Name { get; set; } = string.Empty; |
||||
|
|
||||
|
[Range(0, double.MaxValue)] |
||||
|
public decimal Price { get; set; } |
||||
|
|
||||
|
[StringLength(256)] |
||||
|
public string? Description { get; set; } |
||||
|
|
||||
|
public int Stock { get; set; } |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
`"AppDbContext.cs` |
||||
|
|
||||
|
```csharp |
||||
|
using Microsoft.EntityFrameworkCore; |
||||
|
using RepositoryPattern.Web.Models; |
||||
|
|
||||
|
namespace RepositoryPattern.Web.Data; |
||||
|
|
||||
|
public class AppDbContext(DbContextOptions<AppDbContext> options) : DbContext(options) |
||||
|
{ |
||||
|
public DbSet<Product> Products => Set<Product>(); |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
### Generic repository contract and base class |
||||
|
|
||||
|
All entities share the same CRUD needs, so we define a generic interface and an EF Core implementation. |
||||
|
|
||||
|
`Repositories/IRepository.cs` |
||||
|
|
||||
|
```csharp |
||||
|
using System.Linq.Expressions; |
||||
|
|
||||
|
namespace RepositoryPattern.Web.Repositories; |
||||
|
|
||||
|
public interface IRepository<TEntity> where TEntity : class |
||||
|
{ |
||||
|
Task<TEntity?> GetByIdAsync(int id, CancellationToken cancellationToken = default); |
||||
|
Task<List<TEntity>> GetAllAsync(CancellationToken cancellationToken = default); |
||||
|
Task<List<TEntity>> GetListAsync(Expression<Func<TEntity, bool>> predicate, CancellationToken cancellationToken = default); |
||||
|
Task AddAsync(TEntity entity, CancellationToken cancellationToken = default); |
||||
|
Task UpdateAsync(TEntity entity, CancellationToken cancellationToken = default); |
||||
|
Task DeleteAsync(int id, CancellationToken cancellationToken = default); |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
`Repositories/EfRepository.cs` |
||||
|
|
||||
|
```csharp |
||||
|
using Microsoft.EntityFrameworkCore; |
||||
|
using RepositoryPattern.Web.Data; |
||||
|
|
||||
|
namespace RepositoryPattern.Web.Repositories; |
||||
|
|
||||
|
public class EfRepository<TEntity>(AppDbContext context) : IRepository<TEntity> |
||||
|
where TEntity : class |
||||
|
{ |
||||
|
protected readonly AppDbContext Context = context; |
||||
|
|
||||
|
public virtual async Task<TEntity?> GetByIdAsync(int id, CancellationToken cancellationToken = default) |
||||
|
=> await Context.Set<TEntity>().FindAsync([id], cancellationToken); |
||||
|
|
||||
|
public virtual async Task<List<TEntity>> GetAllAsync(CancellationToken cancellationToken = default) |
||||
|
=> await Context.Set<TEntity>().AsNoTracking().ToListAsync(cancellationToken); |
||||
|
|
||||
|
public virtual async Task<List<TEntity>> GetListAsync( |
||||
|
System.Linq.Expressions.Expression<Func<TEntity, bool>> predicate, |
||||
|
CancellationToken cancellationToken = default) |
||||
|
=> await Context.Set<TEntity>() |
||||
|
.AsNoTracking() |
||||
|
.Where(predicate) |
||||
|
.ToListAsync(cancellationToken); |
||||
|
|
||||
|
public virtual async Task AddAsync(TEntity entity, CancellationToken cancellationToken = default) |
||||
|
{ |
||||
|
await Context.Set<TEntity>().AddAsync(entity, cancellationToken); |
||||
|
await Context.SaveChangesAsync(cancellationToken); |
||||
|
} |
||||
|
|
||||
|
public virtual async Task UpdateAsync(TEntity entity, CancellationToken cancellationToken = default) |
||||
|
{ |
||||
|
Context.Set<TEntity>().Update(entity); |
||||
|
await Context.SaveChangesAsync(cancellationToken); |
||||
|
} |
||||
|
|
||||
|
public virtual async Task DeleteAsync(int id, CancellationToken cancellationToken = default) |
||||
|
{ |
||||
|
var entity = await GetByIdAsync(id, cancellationToken); |
||||
|
if (entity is null) |
||||
|
{ |
||||
|
return; |
||||
|
} |
||||
|
|
||||
|
Context.Set<TEntity>().Remove(entity); |
||||
|
await Context.SaveChangesAsync(cancellationToken); |
||||
|
} |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
Reads use `AsNoTracking()` to avoid tracking overhead, while write methods call `SaveChangesAsync` to keep the sample straightforward. |
||||
|
|
||||
|
### Product-specific repository |
||||
|
|
||||
|
Products need one extra query: list the items that are almost out of stock. We extend the generic repository with a dedicated interface and implementation. |
||||
|
|
||||
|
`Repositories/IProductRepository.cs` |
||||
|
|
||||
|
```csharp |
||||
|
using RepositoryPattern.Web.Models; |
||||
|
|
||||
|
namespace RepositoryPattern.Web.Repositories; |
||||
|
|
||||
|
public interface IProductRepository : IRepository<Product> |
||||
|
{ |
||||
|
Task<List<Product>> GetLowStockProductsAsync(int threshold, CancellationToken cancellationToken = default); |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
`Repositories/ProductRepository.cs` |
||||
|
|
||||
|
```csharp |
||||
|
using Microsoft.EntityFrameworkCore; |
||||
|
using RepositoryPattern.Web.Data; |
||||
|
using RepositoryPattern.Web.Models; |
||||
|
|
||||
|
namespace RepositoryPattern.Web.Repositories; |
||||
|
|
||||
|
public class ProductRepository(AppDbContext context) : EfRepository<Product>(context), IProductRepository |
||||
|
{ |
||||
|
public Task<List<Product>> GetLowStockProductsAsync(int threshold, CancellationToken cancellationToken = default) => |
||||
|
Context.Products |
||||
|
.AsNoTracking() |
||||
|
.Where(product => product.Stock <= threshold) |
||||
|
.OrderBy(product => product.Stock) |
||||
|
.ToListAsync(cancellationToken); |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
### 🧩 A Note on Unit of Work |
||||
|
|
||||
|
The Repository Pattern is often used together with the **Unit of Work** pattern to manage transactions efficiently. |
||||
|
|
||||
|
> 💡 *If you want to dive deeper into the Unit of Work pattern, check out our separate blog post dedicated to that topic. https://abp.io/community/articles/lv4v2tyf |
||||
|
|
||||
|
### Service layer and controller |
||||
|
|
||||
|
Controllers depend on a service, and the service depends on the repository. That keeps HTTP logic and data logic separate. |
||||
|
|
||||
|
`Services/ProductService.cs` |
||||
|
|
||||
|
```csharp |
||||
|
using RepositoryPattern.Web.Models; |
||||
|
using RepositoryPattern.Web.Repositories; |
||||
|
|
||||
|
namespace RepositoryPattern.Web.Services; |
||||
|
|
||||
|
public class ProductService(IProductRepository productRepository) |
||||
|
{ |
||||
|
private readonly IProductRepository _productRepository = productRepository; |
||||
|
|
||||
|
public Task<List<Product>> GetProductsAsync(CancellationToken cancellationToken = default) => |
||||
|
_productRepository.GetAllAsync(cancellationToken); |
||||
|
|
||||
|
public Task<List<Product>> GetLowStockAsync(int threshold, CancellationToken cancellationToken = default) => |
||||
|
_productRepository.GetLowStockProductsAsync(threshold, cancellationToken); |
||||
|
|
||||
|
public Task<Product?> GetByIdAsync(int id, CancellationToken cancellationToken = default) => |
||||
|
_productRepository.GetByIdAsync(id, cancellationToken); |
||||
|
|
||||
|
public Task CreateAsync(Product product, CancellationToken cancellationToken = default) => |
||||
|
_productRepository.AddAsync(product, cancellationToken); |
||||
|
|
||||
|
public Task UpdateAsync(Product product, CancellationToken cancellationToken = default) => |
||||
|
_productRepository.UpdateAsync(product, cancellationToken); |
||||
|
|
||||
|
public Task DeleteAsync(int id, CancellationToken cancellationToken = default) => |
||||
|
_productRepository.DeleteAsync(id, cancellationToken); |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
`Controllers/ProductsController.cs` |
||||
|
|
||||
|
```csharp |
||||
|
using Microsoft.AspNetCore.Mvc; |
||||
|
using RepositoryPattern.Web.Models; |
||||
|
using RepositoryPattern.Web.Services; |
||||
|
|
||||
|
namespace RepositoryPattern.Web.Controllers; |
||||
|
|
||||
|
public class ProductsController(ProductService productService) : Controller |
||||
|
{ |
||||
|
private readonly ProductService _productService = productService; |
||||
|
|
||||
|
public async Task<IActionResult> Index(CancellationToken cancellationToken) |
||||
|
{ |
||||
|
const int lowStockThreshold = 5; |
||||
|
var products = await _productService.GetProductsAsync(cancellationToken); |
||||
|
var lowStock = await _productService.GetLowStockAsync(lowStockThreshold, cancellationToken); |
||||
|
|
||||
|
return View(new ProductListViewModel(products, lowStock, lowStockThreshold)); |
||||
|
} |
||||
|
|
||||
|
// remaining CRUD actions call through ProductService in the same way |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
The controller never reaches for `AppDbContext`. Every operation travels through the service, which keeps tests simple and makes future refactors easier. |
||||
|
|
||||
|
### Dependency registration and seeding |
||||
|
|
||||
|
The last step is wiring everything up in `Program.cs`. |
||||
|
|
||||
|
```csharp |
||||
|
builder.Services.AddDbContext<AppDbContext>(options => |
||||
|
options.UseInMemoryDatabase("ProductsDb")); |
||||
|
builder.Services.AddScoped(typeof(IRepository<>), typeof(EfRepository<>)); |
||||
|
builder.Services.AddScoped<IProductRepository, ProductRepository>(); |
||||
|
builder.Services.AddScoped<ProductService>(); |
||||
|
``` |
||||
|
|
||||
|
The sample also seeds three products so the list page shows data on first run. |
||||
|
|
||||
|
Run the site with: |
||||
|
|
||||
|
```powershell |
||||
|
dotnet run --project RepositoryPattern.Web |
||||
|
``` |
||||
|
|
||||
|
## How ABP approaches the same idea |
||||
|
|
||||
|
ABP includes generic repositories by default (`IRepository<TEntity, TKey>`), so you often skip writing the implementation layer shown above. You inject the interface into an application service, call methods like `InsertAsync` or `CountAsync`, and ABP’s Unit of Work handles the transaction. When you need custom queries, you can still derive from `EfCoreRepository<TEntity, TKey>` and add them. |
||||
|
|
||||
|
For more details, check out the official ABP documentation on repositories: https://abp.io/docs/latest/framework/architecture/domain-driven-design/repositories |
||||
|
|
||||
|
### Closing note |
||||
|
|
||||
|
This setup keeps data access tidy without being heavy. Start with the generic repository, add small extensions per entity, pass everything through services, and register the dependencies once. Whether you hand-code it or let ABP supply the repository, the structure stays the same and your controllers remain clean. |
||||
@ -0,0 +1,302 @@ |
|||||
|
# Where and How to Store Your BLOB Objects in .NET? |
||||
|
|
||||
|
When building modern web applications, managing [BLOBs (Binary Large Objects)](https://cloud.google.com/discover/what-is-binary-large-object-storage) such as images, videos, documents, or any other file types is a common requirement. Whether you're developing a CMS, an e-commerce platform, or almost any other kind of application, you'll eventually ask yourself: **"Where should I store these files?"** |
||||
|
|
||||
|
In this article, we'll explore different approaches to storing BLOBs in .NET applications and demonstrate how the ABP Framework simplifies this process with its flexible [BLOB Storing infrastructure](https://abp.io/docs/latest/framework/infrastructure/blob-storing). |
||||
|
|
||||
|
ABP Provides [multiple storage providers](https://abp.io/docs/latest/framework/infrastructure/blob-storing#blob-storage-providers) such as Azure, AWS, Google, Minio, Bunny etc. But for the simplicity of this article, we will only focus on the **Database Provider**, showing you how to store BLOBs in database tables step-by-step. |
||||
|
|
||||
|
## Understanding BLOB Storage Options |
||||
|
|
||||
|
Before diving into implementation details, let's understand the common approaches for storing BLOBs in .NET applications. Mainly, there are three main approaches: |
||||
|
|
||||
|
1. Database Storage |
||||
|
2. File System Storage |
||||
|
3. Cloud Storage |
||||
|
|
||||
|
### 1. Database Storage |
||||
|
|
||||
|
The first approach is to store BLOBs directly in the database alongside your relational data (_you can also store them separately_). This approach uses columns with types like `VARBINARY(MAX)` in SQL Server or `BYTEA` in PostgreSQL. |
||||
|
|
||||
|
**Pros:** |
||||
|
- ✅ Transactional consistency between files and related data |
||||
|
- ✅ Simplified backup and restore operations (everything in one place) |
||||
|
- ✅ No additional file system permissions or management needed |
||||
|
|
||||
|
**Cons:** |
||||
|
- ❌ Database size can grow significantly with large files |
||||
|
- ❌ Potential performance impact on database operations |
||||
|
- ❌ May require additional database tuning and optimization |
||||
|
- ❌ Increased backup size and duration |
||||
|
|
||||
|
### 2. File System Storage |
||||
|
|
||||
|
The second obvious approach is to store BLOBs as physical files in the server's file system. This approach is simple and easy to implement. Also, it's possible to use these two approaches together and keep the metadata and file references in the database. |
||||
|
|
||||
|
**Pros:** |
||||
|
- ✅ Better performance for large files |
||||
|
- ✅ Reduced database size and improved database performance |
||||
|
- ✅ Easier to leverage CDNs and file servers |
||||
|
- ✅ Simple to implement file system-level operations (compression, deduplication) |
||||
|
|
||||
|
**Cons:** |
||||
|
- ❌ Requires separate backup strategy for files |
||||
|
- ❌ Need to manage file system permissions |
||||
|
- ❌ Potential synchronization issues in distributed environments |
||||
|
- ❌ More complex cleanup operations for orphaned files |
||||
|
|
||||
|
### 3. Cloud Storage (Azure, AWS S3, etc.) |
||||
|
|
||||
|
The third approach can be using cloud storage services for scalability and global distribution. This approach is powerful and scalable. But it's also more complex to implement and manage. |
||||
|
|
||||
|
**Best for:** |
||||
|
- Large-scale applications |
||||
|
- Multi-region deployments |
||||
|
- Content delivery requirements |
||||
|
|
||||
|
## ABP Framework's BLOB Storage Infrastructure |
||||
|
|
||||
|
The ABP Framework provides an abstraction layer over different storage providers, allowing you to switch between them with minimal code changes. This is achieved through the **IBlobContainer** (and `IBlobContainer<TContainerType>`) service and various provider implementations. |
||||
|
|
||||
|
> ABP provides several built-in providers, which you can see the full list [here](https://abp.io/docs/latest/framework/infrastructure/blob-storing#blob-storage-providers). |
||||
|
|
||||
|
Let's see how to use the Database provider in your application step by step. |
||||
|
|
||||
|
### Demo: Storing BLOBs in Database in an ABP-Based Application |
||||
|
|
||||
|
In this demo, we'll walk through a practical example of storing BLOBs in a database using ABP's BLOB Storing infrastructure. We'll focus on the backend implementation using the `IBlobContainer` service and examine the database structure that ABP creates automatically. The UI framework choice doesn't matter for this demonstration, as we're concentrating on the core BLOB storage functionality. |
||||
|
|
||||
|
If you don't have an ABP application yet, create one using the ABP CLI: |
||||
|
|
||||
|
```bash |
||||
|
abp new BlobStoringDemo |
||||
|
``` |
||||
|
|
||||
|
This command generates a new ABP layered application named `BlobStoringDemo` with **MVC** as the default UI and **SQL Server** as the default database provider. |
||||
|
|
||||
|
#### Understanding the Database Provider Setup |
||||
|
|
||||
|
When you create a layered ABP application, it automatically includes the BLOB Storing infrastructure with the Database Provider pre-configured. You can verify this by examining the module dependencies in your `*Domain`, `*DomainShared`, and `*EntityFrameworkCore` modules: |
||||
|
|
||||
|
```csharp |
||||
|
[DependsOn( |
||||
|
//... |
||||
|
typeof(BlobStoringDatabaseDomainModule) // <-- This is the Database Provider |
||||
|
)] |
||||
|
public class BlobStoringDemoDomainModule : AbpModule |
||||
|
{ |
||||
|
//... |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
Since the Database Provider is already included through module dependencies, no additional configuration is required to start using it. The provider is ready to use out of the box. |
||||
|
|
||||
|
However, if you're working with multiple BLOB storage providers or want to explicitly configure the Database Provider, you can add the following configuration to your `*EntityFrameworkCore` module's `ConfigureServices` method: |
||||
|
|
||||
|
```csharp |
||||
|
Configure<AbpBlobStoringOptions>(options => |
||||
|
{ |
||||
|
options.Containers.ConfigureDefault(container => |
||||
|
{ |
||||
|
container.UseDatabase(); |
||||
|
}); |
||||
|
}); |
||||
|
``` |
||||
|
|
||||
|
> **Note:** This explicit configuration is optional when using only one BLOB provider (Database Provider in this case), but becomes necessary when managing multiple providers or custom container configurations. |
||||
|
|
||||
|
#### Running Database Migrations |
||||
|
|
||||
|
Now, let's apply the database migrations to create the necessary BLOB storage tables. Run the `DbMigrator` project: |
||||
|
|
||||
|
```bash |
||||
|
cd src/BlobStoringDemo.DbMigrator |
||||
|
dotnet run |
||||
|
``` |
||||
|
|
||||
|
Once the migration completes successfully, open your database management tool and you'll see two new tables: |
||||
|
|
||||
|
 |
||||
|
|
||||
|
**Understanding the BLOB Storage Tables:** |
||||
|
|
||||
|
- **`AbpBlobContainers`**: Stores metadata about BLOB containers, including container names, tenant information, and any custom properties. |
||||
|
|
||||
|
- **`AbpBlobs`**: Stores the actual BLOB content (the binary data) along with references to their parent containers. Each BLOB is associated with a container through a foreign key relationship. |
||||
|
|
||||
|
When you save a BLOB, ABP automatically handles the database operations: the binary content goes into `AbpBlobs`, while the container configuration and metadata are managed in `AbpBlobContainers`. |
||||
|
|
||||
|
#### Creating a File Management Service |
||||
|
|
||||
|
Let's implement a practical application service that demonstrates common BLOB operations. Create a new application service class: |
||||
|
|
||||
|
```csharp |
||||
|
using System.Threading.Tasks; |
||||
|
using Volo.Abp.Application.Services; |
||||
|
using Volo.Abp.BlobStoring; |
||||
|
|
||||
|
namespace BlobStoringDemo |
||||
|
{ |
||||
|
public class FileAppService : ApplicationService, IFileAppService |
||||
|
{ |
||||
|
private readonly IBlobContainer _blobContainer; |
||||
|
|
||||
|
public FileAppService(IBlobContainer blobContainer) |
||||
|
{ |
||||
|
_blobContainer = blobContainer; |
||||
|
} |
||||
|
|
||||
|
public async Task SaveFileAsync(string fileName, byte[] fileContent) |
||||
|
{ |
||||
|
// Save the file |
||||
|
await _blobContainer.SaveAsync(fileName, fileContent); |
||||
|
} |
||||
|
|
||||
|
public async Task<byte[]> GetFileAsync(string fileName) |
||||
|
{ |
||||
|
// Get the file |
||||
|
return await _blobContainer.GetAllBytesAsync(fileName); |
||||
|
} |
||||
|
|
||||
|
public async Task<bool> FileExistsAsync(string fileName) |
||||
|
{ |
||||
|
// Check if file exists |
||||
|
return await _blobContainer.ExistsAsync(fileName); |
||||
|
} |
||||
|
|
||||
|
public async Task DeleteFileAsync(string fileName) |
||||
|
{ |
||||
|
// Delete the file |
||||
|
await _blobContainer.DeleteAsync(fileName); |
||||
|
} |
||||
|
} |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
Here, we are doing the followings: |
||||
|
|
||||
|
- Injecting the `IBlobContainer` service. |
||||
|
- Saving the BLOB data to the database with the `SaveAsync` method. (_it allows you to use byte arrays or streams_) |
||||
|
- Retrieving the BLOB data from the database with the `GetAllBytesAsync` method. |
||||
|
- Checking if the BLOB exists with the `ExistsAsync` method. |
||||
|
- Deleting the BLOB data from the database with the `DeleteAsync` method. |
||||
|
|
||||
|
With this service in place, you can now manage BLOBs throughout your application without worrying about the underlying storage implementation. Simply inject `IFileAppService` wherever you need file operations, and ABP handles all the provider-specific details behind the scenes. |
||||
|
|
||||
|
> Also, it's good to highlight that, the beauty of this approach is **provider independence**: you can start with database storage and later switch to Azure Blob Storage, AWS S3, or any other provider without modifying a single line of your application code. We'll explore this powerful feature in the next section. |
||||
|
|
||||
|
### Switching Between Providers |
||||
|
|
||||
|
One of the biggest advantages of using ABP's BLOB Storage system is the ability to switch providers without changing your application code. |
||||
|
|
||||
|
For example, you might start with the [File System provider](https://abp.io/docs/latest/framework/infrastructure/blob-storing/file-system) during development and switch to [Azure Blob Storage](https://abp.io/docs/latest/framework/infrastructure/blob-storing/azure) for production: |
||||
|
|
||||
|
**Development:** |
||||
|
```csharp |
||||
|
Configure<AbpBlobStoringOptions>(options => |
||||
|
{ |
||||
|
options.Containers.ConfigureDefault(container => |
||||
|
{ |
||||
|
container.UseFileSystem(fileSystem => |
||||
|
{ |
||||
|
fileSystem.BasePath = Path.Combine( |
||||
|
hostingEnvironment.ContentRootPath, |
||||
|
"Documents" |
||||
|
); |
||||
|
}); |
||||
|
}); |
||||
|
}); |
||||
|
``` |
||||
|
|
||||
|
**Production:** |
||||
|
```csharp |
||||
|
Configure<AbpBlobStoringOptions>(options => |
||||
|
{ |
||||
|
options.Containers.ConfigureDefault(container => |
||||
|
{ |
||||
|
container.UseAzure(azure => |
||||
|
{ |
||||
|
azure.ConnectionString = "your azure connection string"; |
||||
|
azure.ContainerName = "your azure container name"; |
||||
|
azure.CreateContainerIfNotExists = true; |
||||
|
}); |
||||
|
}); |
||||
|
}); |
||||
|
``` |
||||
|
|
||||
|
**Your application code remains unchanged!** You just need to install the appropriate package and update the configuration. You can even use pragmas (for example: `#if !DEBUG`) to switch the provider at runtime (or use similar techniques). |
||||
|
|
||||
|
### Using Named BLOB Containers |
||||
|
|
||||
|
ABP allows you to define multiple BLOB containers with different configurations. This is useful when you need to store different types of files using different providers. Here are the steps to implement it: |
||||
|
|
||||
|
#### Step 1: Define a BLOB Container |
||||
|
|
||||
|
```csharp |
||||
|
[BlobContainerName("profile-pictures")] |
||||
|
public class ProfilePictureContainer |
||||
|
{ |
||||
|
} |
||||
|
|
||||
|
[BlobContainerName("documents")] |
||||
|
public class DocumentContainer |
||||
|
{ |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
#### Step 2: Configure Different Providers for Each Container |
||||
|
|
||||
|
```csharp |
||||
|
Configure<AbpBlobStoringOptions>(options => |
||||
|
{ |
||||
|
// Profile pictures stored in database |
||||
|
options.Containers.Configure<ProfilePictureContainer>(container => |
||||
|
{ |
||||
|
container.UseDatabase(); |
||||
|
}); |
||||
|
|
||||
|
// Documents stored in file system |
||||
|
options.Containers.Configure<DocumentContainer>(container => |
||||
|
{ |
||||
|
container.UseFileSystem(fileSystem => |
||||
|
{ |
||||
|
fileSystem.BasePath = Path.Combine( |
||||
|
hostingEnvironment.ContentRootPath, |
||||
|
"Documents" |
||||
|
); |
||||
|
}); |
||||
|
}); |
||||
|
}); |
||||
|
``` |
||||
|
|
||||
|
#### Step 3: Use the Named Containers |
||||
|
|
||||
|
Once you have defined the BLOB Containers, you can use the `IBlobContainer<TContainerType>` service to access the BLOB containers: |
||||
|
|
||||
|
```csharp |
||||
|
public class ProfileService : ApplicationService |
||||
|
{ |
||||
|
private readonly IBlobContainer<ProfilePictureContainer> _profilePictureContainer; |
||||
|
|
||||
|
public ProfileService(IBlobContainer<ProfilePictureContainer> profilePictureContainer) |
||||
|
{ |
||||
|
_profilePictureContainer = profilePictureContainer; |
||||
|
} |
||||
|
|
||||
|
public async Task UpdateProfilePictureAsync(Guid userId, byte[] picture) |
||||
|
{ |
||||
|
var blobName = $"{userId}.jpg"; |
||||
|
await _profilePictureContainer.SaveAsync(blobName, picture); |
||||
|
} |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
With this approach, your documents and profile pictures are stored in different containers and different providers. This is useful when you need to store different types of files using different providers and need scalability and performance. |
||||
|
|
||||
|
## Conclusion |
||||
|
|
||||
|
Managing BLOBs effectively is crucial for modern applications, and choosing the right storage approach depends on your specific needs. |
||||
|
|
||||
|
ABP's BLOB Storing infrastructure provides a powerful abstraction that lets you start with one provider and switch to another as your requirements evolve, all without changing your application code. |
||||
|
|
||||
|
Whether you're storing files in a database, file system, or cloud storage, ABP's BLOB Storing system provides a flexible and powerful way to manage your files. |
||||
{kind=link}
|
After Width: | Height: | Size: 7.5 KiB |
{kind=link}
|
After Width: | Height: | Size: 152 KiB |
@ -0,0 +1,371 @@ |
|||||
|
# Why Do You Need Distributed Locking in ASP.NET Core |
||||
|
|
||||
|
## Introduction |
||||
|
|
||||
|
In modern distributed systems, synchronizing access to common resources among numerous instances is a critical problem. Whenever lots of servers or processes concurrently attempt to update the same resource simultaneously, race conditions can lead to data corruption, redundant work, and inconsistent state. Throughout the implementation of the ABP framework, we encountered and overcame this exact same problem with assistance from a stable distributed locking mechanism. In this post, we will present our experience and learnings when implementing this solution, so you can understand when and why you would need distributed locking in your ASP.NET Core applications. |
||||
|
|
||||
|
## Problem |
||||
|
|
||||
|
Suppose you are running an e-commerce application deployed on multiple servers for high availability. A customer places an order, which kicks off a background job that reserves inventory and charges payment. If not properly synchronized, the following is what can happen: |
||||
|
|
||||
|
### Race Conditions in Multi-Instance Deployments |
||||
|
|
||||
|
When your ASP.NET Core application is scaled horizontally with multiple instances, each instance works independently. If two instances simultaneously perform the same operation—like deducting inventory, generating invoice numbers, or processing a refund—you can end up with: |
||||
|
|
||||
|
- **Duplicate operations**: The same payment processed twice |
||||
|
- **Data inconsistency**: Inventory count becomes negative or incorrect |
||||
|
- **Lost updates**: One instance's changes overwrite another's |
||||
|
- **Sequential ID conflicts**: Two instances generate the same invoice number |
||||
|
|
||||
|
### Background Job Processing |
||||
|
|
||||
|
Background work libraries like Quartz.NET or Hangfire usually run on multiple workers. Without distributed locking: |
||||
|
|
||||
|
- Multiple workers can choose the same task |
||||
|
- Long-running processes can be executed parallel when they should be executed in a sequence |
||||
|
- Jobs that depend on exclusive resource access can corrupt shared data |
||||
|
|
||||
|
### Cache Invalidation and Refresh |
||||
|
|
||||
|
When distributed caching is employed, there can be multiple instances that simultaneously identify a cache miss and attempt to rebuild the cache, leading to: |
||||
|
|
||||
|
- High database load owing to concurrent rebuild cache requests |
||||
|
- Race conditions under which older data overrides newer data |
||||
|
- wasted computational resources |
||||
|
|
||||
|
### Rate Limiting and Throttling |
||||
|
|
||||
|
Enforcing rate limits across multiple instances of the application requires coordination. If there is no distributed locking, each instance has its own limits, and global rate limits cannot be enforced properly. |
||||
|
|
||||
|
The root issue is simple: **the default C# locking APIs (lock, SemaphoreSlim, Monitor) work within a process in isolation**. They will not assist with distributed cases where coordination must take place across servers, containers, or cloud instances. |
||||
|
|
||||
|
## Solutions |
||||
|
|
||||
|
Several approaches exist for implementing distributed locking in ASP.NET Core applications. Let's explore the most common solutions, their trade-offs, and why we chose our approach for ABP. |
||||
|
|
||||
|
### 1. Database-Based Locking |
||||
|
|
||||
|
Using your existing database to place locks by inserting or updating rows with distinctive values. |
||||
|
|
||||
|
**Pros:** |
||||
|
- No additional infrastructure required |
||||
|
- Works with any relational database |
||||
|
- Transactions provide ACID guarantees |
||||
|
|
||||
|
**Cons:** |
||||
|
- Database round-trip performance overhead |
||||
|
- Can lead to database contention under high load |
||||
|
- Must be controlled to prevent orphaned locks |
||||
|
- Not suited for high-frequency locking scenarios |
||||
|
|
||||
|
**When to use:** Small-scale applications where you do not wish to add additional infrastructure, and lock operations are low frequency. |
||||
|
|
||||
|
### 2. Redis-Based Locking |
||||
|
|
||||
|
Redis has atomic operations that make it excellent at distributed locking, using commands such as `SET NX` (set if not exists) with expiration. |
||||
|
**Pros:** |
||||
|
|
||||
|
- Low latency and high performance |
||||
|
- Expiration prevents lost locks built-in |
||||
|
- Well-established with tested patterns (Redlock algorithm) |
||||
|
- Works well for high-throughput use cases |
||||
|
**Cons:** |
||||
|
|
||||
|
- Requires Redis infrastructure |
||||
|
- Network partitions might be an issue |
||||
|
- One Redis instance is a single point of failure (although Redis Cluster reduces it) |
||||
|
**Resources:** |
||||
|
|
||||
|
- [Redis Distributed Locks Documentation](https://redis.io/docs/manual/patterns/distributed-locks/) |
||||
|
- [Redlock Algorithm](https://redis.io/topics/distlock) |
||||
|
**When to use:** Production applications with multiple instances where performance is critical, especially if you are already using Redis as a caching layer. |
||||
|
|
||||
|
### 3. Azure Blob Storage Leases |
||||
|
|
||||
|
Azure Blob Storage offers lease functionality which can be utilized for distributed locks. |
||||
|
|
||||
|
**Pros:** |
||||
|
- Part of Azure, no extra infrastructure |
||||
|
- Lease expiration automatically |
||||
|
- Low-frequency locks are economically viable |
||||
|
|
||||
|
**Cons:** |
||||
|
- Azure-specific, not portable |
||||
|
- Latency greater than Redis |
||||
|
- Azure cloud-only projects |
||||
|
|
||||
|
**When to use:** Azure-native applications with low-locking frequency where you need to minimize moving parts. |
||||
|
|
||||
|
### 4. etcd or ZooKeeper |
||||
|
|
||||
|
Distributed coordination services designed from scratch to accommodate consensus and locking. |
||||
|
|
||||
|
**Pros:** |
||||
|
- Designed for distributed coordination |
||||
|
- Strong consistency guaranteed |
||||
|
- Robust against network partitions |
||||
|
|
||||
|
**Cons:** |
||||
|
- Difficulty in setting up the infrastructure |
||||
|
- Excess baggage for most applications |
||||
|
- Steep learning curve |
||||
|
|
||||
|
**Use when:** Large distributed systems with complex coordination require more than basic locking. |
||||
|
|
||||
|
|
||||
|
### Our Choice: Abstraction with Multiple Implementations |
||||
|
|
||||
|
For ABP, we chose to use an **abstraction layer** with support for multibackend. This provides flexibility to the developers so that they can choose the best implementation depending on their infrastructure. Our default implementations include support for: |
||||
|
|
||||
|
- **Redis** (recommended for most scenarios) |
||||
|
- **Database-based locking** (for less complicated configurations) |
||||
|
- In-memory single-instance and development locks |
||||
|
|
||||
|
We started with Redis because it offers the best tradeoff between ease of operation, reliability, and performance for distributed cases. But abstraction prevents applications from becoming technology-dependent, and it's easier to start simple and expand as needed. |
||||
|
|
||||
|
## Implementation |
||||
|
|
||||
|
Let's implement a simplified distributed locking mechanism using Redis and StackExchange.Redis. This example shows the core concepts without ABP's framework complexity. |
||||
|
|
||||
|
First, install the required package: |
||||
|
|
||||
|
```bash |
||||
|
dotnet add package StackExchange.Redis |
||||
|
``` |
||||
|
|
||||
|
Here's a basic distributed lock implementation: |
||||
|
|
||||
|
```csharp |
||||
|
public interface IDistributedLock |
||||
|
{ |
||||
|
Task<IDisposable?> TryAcquireAsync( |
||||
|
string resource, |
||||
|
TimeSpan expirationTime, |
||||
|
CancellationToken cancellationToken = default); |
||||
|
} |
||||
|
|
||||
|
public class RedisDistributedLock : IDistributedLock |
||||
|
{ |
||||
|
private readonly IConnectionMultiplexer _redis; |
||||
|
private readonly ILogger<RedisDistributedLock> _logger; |
||||
|
|
||||
|
public RedisDistributedLock( |
||||
|
IConnectionMultiplexer redis, |
||||
|
ILogger<RedisDistributedLock> logger) |
||||
|
{ |
||||
|
_redis = redis; |
||||
|
_logger = logger; |
||||
|
} |
||||
|
|
||||
|
public async Task<IDisposable?> TryAcquireAsync( |
||||
|
string resource, |
||||
|
TimeSpan expirationTime, |
||||
|
CancellationToken cancellationToken = default) |
||||
|
{ |
||||
|
var db = _redis.GetDatabase(); |
||||
|
var lockKey = $"lock:{resource}"; |
||||
|
var lockValue = Guid.NewGuid().ToString(); |
||||
|
|
||||
|
// Try to acquire the lock using SET NX with expiration |
||||
|
var acquired = await db.StringSetAsync( |
||||
|
lockKey, |
||||
|
lockValue, |
||||
|
expirationTime, |
||||
|
When.NotExists); |
||||
|
|
||||
|
if (!acquired) |
||||
|
{ |
||||
|
_logger.LogDebug( |
||||
|
"Failed to acquire lock for resource: {Resource}", |
||||
|
resource); |
||||
|
return null; |
||||
|
} |
||||
|
|
||||
|
_logger.LogDebug( |
||||
|
"Lock acquired for resource: {Resource}", |
||||
|
resource); |
||||
|
|
||||
|
return new RedisLockHandle(db, lockKey, lockValue, _logger); |
||||
|
} |
||||
|
|
||||
|
private class RedisLockHandle : IDisposable |
||||
|
{ |
||||
|
private readonly IDatabase _db; |
||||
|
private readonly string _lockKey; |
||||
|
private readonly string _lockValue; |
||||
|
private readonly ILogger _logger; |
||||
|
private bool _disposed; |
||||
|
|
||||
|
public RedisLockHandle( |
||||
|
IDatabase db, |
||||
|
string lockKey, |
||||
|
string lockValue, |
||||
|
ILogger logger) |
||||
|
{ |
||||
|
_db = db; |
||||
|
_lockKey = lockKey; |
||||
|
_lockValue = lockValue; |
||||
|
_logger = logger; |
||||
|
} |
||||
|
|
||||
|
public void Dispose() |
||||
|
{ |
||||
|
if (_disposed) return; |
||||
|
|
||||
|
try |
||||
|
{ |
||||
|
// Only delete if we still own the lock |
||||
|
var script = @" |
||||
|
if redis.call('get', KEYS[1]) == ARGV[1] then |
||||
|
return redis.call('del', KEYS[1]) |
||||
|
else |
||||
|
return 0 |
||||
|
end"; |
||||
|
|
||||
|
_db.ScriptEvaluate( |
||||
|
script, |
||||
|
new RedisKey[] { _lockKey }, |
||||
|
new RedisValue[] { _lockValue }); |
||||
|
|
||||
|
_logger.LogDebug("Lock released for key: {LockKey}", _lockKey); |
||||
|
} |
||||
|
catch (Exception ex) |
||||
|
{ |
||||
|
_logger.LogError( |
||||
|
ex, |
||||
|
"Error releasing lock for key: {LockKey}", |
||||
|
_lockKey); |
||||
|
} |
||||
|
finally |
||||
|
{ |
||||
|
_disposed = true; |
||||
|
} |
||||
|
} |
||||
|
} |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
Register the service in your `Program.cs`: |
||||
|
|
||||
|
```csharp |
||||
|
builder.Services.AddSingleton<IConnectionMultiplexer>(sp => |
||||
|
{ |
||||
|
var configuration = ConfigurationOptions.Parse("localhost:6379"); |
||||
|
return ConnectionMultiplexer.Connect(configuration); |
||||
|
}); |
||||
|
|
||||
|
builder.Services.AddSingleton<IDistributedLock, RedisDistributedLock>(); |
||||
|
``` |
||||
|
|
||||
|
Now you can use distributed locking in your services: |
||||
|
|
||||
|
```csharp |
||||
|
public class OrderService |
||||
|
{ |
||||
|
private readonly IDistributedLock _distributedLock; |
||||
|
private readonly ILogger<OrderService> _logger; |
||||
|
|
||||
|
public OrderService( |
||||
|
IDistributedLock distributedLock, |
||||
|
ILogger<OrderService> logger) |
||||
|
{ |
||||
|
_distributedLock = distributedLock; |
||||
|
_logger = logger; |
||||
|
} |
||||
|
|
||||
|
public async Task ProcessOrderAsync(string orderId) |
||||
|
{ |
||||
|
var lockResource = $"order:{orderId}"; |
||||
|
|
||||
|
// Try to acquire the lock with 30-second expiration |
||||
|
await using var lockHandle = await _distributedLock.TryAcquireAsync( |
||||
|
lockResource, |
||||
|
TimeSpan.FromSeconds(30)); |
||||
|
|
||||
|
if (lockHandle == null) |
||||
|
{ |
||||
|
_logger.LogWarning( |
||||
|
"Could not acquire lock for order {OrderId}. " + |
||||
|
"Another process might be processing it.", |
||||
|
orderId); |
||||
|
return; |
||||
|
} |
||||
|
|
||||
|
// Critical section - only one instance will execute this |
||||
|
_logger.LogInformation("Processing order {OrderId}", orderId); |
||||
|
|
||||
|
// Your order processing logic here |
||||
|
await Task.Delay(1000); // Simulating work |
||||
|
|
||||
|
_logger.LogInformation( |
||||
|
"Order {OrderId} processed successfully", |
||||
|
orderId); |
||||
|
|
||||
|
// Lock is automatically released when lockHandle is disposed |
||||
|
} |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
### Key Implementation Details |
||||
|
|
||||
|
**Lock Key Uniqueness**: Use hierarchical, descriptive keys (`order:12345`, `inventory:product-456`) to avoid collisions. |
||||
|
|
||||
|
**Lock Value**: We use a single distinct GUID as the lock value. This ensures only the lock owner can release it, excluding unintentional deletion by expired locks or other operations. |
||||
|
|
||||
|
**Automatic Expiration**: Always provide an expiration time to prevent deadlocks when a process halts with an outstanding lock. |
||||
|
|
||||
|
**Lua Script for Release**: Releasing uses a Lua script to atomically check ownership and delete the key. This prevents releasing a lock that has already timed out and is reacquired by another process. |
||||
|
|
||||
|
**Disposal Pattern**: With `IDisposable` and `await using`, one ensures that the lock is released regardless of the exception that occurs. |
||||
|
|
||||
|
### Handling Lock Acquisition Failures |
||||
|
|
||||
|
Depending on your use case, you have several options when lock acquisition fails: |
||||
|
|
||||
|
```csharp |
||||
|
// Option 1: Return early (shown above) |
||||
|
if (lockHandle == null) |
||||
|
{ |
||||
|
return; |
||||
|
} |
||||
|
|
||||
|
// Option 2: Retry with timeout |
||||
|
var retryCount = 0; |
||||
|
var maxRetries = 3; |
||||
|
IDisposable? lockHandle = null; |
||||
|
|
||||
|
while (lockHandle == null && retryCount < maxRetries) |
||||
|
{ |
||||
|
lockHandle = await _distributedLock.TryAcquireAsync( |
||||
|
lockResource, |
||||
|
TimeSpan.FromSeconds(30)); |
||||
|
|
||||
|
if (lockHandle == null) |
||||
|
{ |
||||
|
retryCount++; |
||||
|
await Task.Delay(TimeSpan.FromMilliseconds(100 * retryCount)); |
||||
|
} |
||||
|
} |
||||
|
|
||||
|
if (lockHandle == null) |
||||
|
{ |
||||
|
throw new InvalidOperationException("Could not acquire lock after retries"); |
||||
|
} |
||||
|
|
||||
|
// Option 3: Queue for later processing |
||||
|
if (lockHandle == null) |
||||
|
{ |
||||
|
await _queueService.EnqueueForLaterAsync(orderId); |
||||
|
return; |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
This is a good foundation for distributed locking in ASP.NET Core applications. It addresses the most common scenarios and edge cases, but production can call for more sophisticated features like lock re-renewal for long-running operations or more sophisticated retry logic. |
||||
|
|
||||
|
## Conclusion |
||||
|
|
||||
|
Distributed locking is a necessity for data consistency and prevention of race conditions in new, scalable ASP.NET Core applications. As we've discussed, the problem becomes unavoidable as soon as you move beyond single-instance deployments to horizontally scaled multi-server, container, or background job worker deployments. |
||||
|
|
||||
|
We examined several of them, from database-level locks to Redis, Azure Blob Storage leases, and coordination services. Each has its place, but Redis-based locking offers the best balance of performance, reliability, and ease in most situations. The example implementation we provided shows how to implement a well-crafted distributed locking mechanism with minimal dependence on other libraries. |
||||
|
|
||||
|
Whether you implement your own solution or utilize a framework like ABP, familiarity with the concepts of distributed locking will help you build more stable and scalable applications. We hope by sharing our experience, we can keep you from falling into typical pitfalls and have distributed locking properly implemented on your own projects. |
||||
{kind=link}
|
After Width: | Height: | Size: 382 KiB |
@ -0,0 +1,108 @@ |
|||||
|
# You May Have Trouble with GUIDs: Generating Sequential GUIDs in .NET |
||||
|
|
||||
|
|
||||
|
If you’ve ever shoved a bunch of `Guid.NewGuid()` values into a SQL Server table with a clustered index on the PK, you’ve probably felt the pain: **Index fragmentation so bad you could use it as modern art.** Inserts slow down, page splits go wild, and your DBA starts sending you passive-aggressive Slack messages. |
||||
|
|
||||
|
And yet… we keep doing it. Why? Because GUIDs are _easy_. They’re globally unique, they don’t need a round trip to the DB, and they make distributed systems happy. But here’s the catch: **random GUIDs are absolute chaos for ordered indexes**. |
||||
|
|
||||
|
## The Problem with Vanilla GUIDs |
||||
|
|
||||
|
* **Randomness kills order** — clustered indexes thrive on sequential inserts; random GUIDs force constant reordering. |
||||
|
|
||||
|
* **Performance hit** — every insert can trigger page splits and index reshuffling. |
||||
|
|
||||
|
* **Storage bloat** — fragmentation means wasted space and slower reads. |
||||
|
|
||||
|
Sure, you could switch to int or long identity columns, but then you lose the distributed generation magic and security benefits (predictable IDs are guessable). |
||||
|
|
||||
|
## Sequential GUIDs to the Rescue |
||||
|
|
||||
|
Sequential GUIDs keep the uniqueness but add a predictable ordering component, usually by embedding a timestamp in part of the GUID. This means: |
||||
|
|
||||
|
* Inserts happen at the “end” of the index, not all over the place. |
||||
|
|
||||
|
* Fragmentation drops dramatically. |
||||
|
|
||||
|
* You still get globally unique IDs without DB trips. |
||||
|
|
||||
|
Think of it as **GUIDs with manners**. |
||||
|
|
||||
|
## ABP Framework’s Secret Sauce |
||||
|
|
||||
|
|
||||
|
Here’s where ABP Framework flexes: it **uses sequential GUIDs by default** for entity IDs. No ceremony, no “remember to call this helper method”, it’s baked in. |
||||
|
|
||||
|
Under the hood: |
||||
|
|
||||
|
* ABP ships with IGuidGenerator (default: SequentialGuidGenerator). |
||||
|
|
||||
|
* It picks the right sequential strategy for your DB provider: |
||||
|
|
||||
|
* **SequentialAtEnd** → SQL Server |
||||
|
|
||||
|
* **SequentialAsString** → MySQL/PostgreSQL |
||||
|
|
||||
|
* **SequentialAsBinary** → Oracle |
||||
|
|
||||
|
* EF Core integration packages auto-configure this, so you rarely need to touch it. |
||||
|
|
||||
|
Example in ABP: |
||||
|
|
||||
|
```csharp |
||||
|
public class MyProductService : ITransientDependency |
||||
|
{ |
||||
|
private readonly IRepository<Product, Guid> _productRepository; |
||||
|
private readonly IGuidGenerator _guidGenerator; |
||||
|
|
||||
|
|
||||
|
public MyProductService( |
||||
|
IRepository<Product, Guid> productRepository, |
||||
|
IGuidGenerator guidGenerator) |
||||
|
{ |
||||
|
_productRepository = productRepository; |
||||
|
_guidGenerator = guidGenerator; |
||||
|
} |
||||
|
|
||||
|
|
||||
|
public async Task CreateAsync(string productName) |
||||
|
{ |
||||
|
var product = new Product(_guidGenerator.Create(), productName); |
||||
|
await _productRepository.InsertAsync(product); |
||||
|
} |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
No `Guid.NewGuid()` here, `_guidGenerator.Create()` gives you a sequential GUID every time. |
||||
|
|
||||
|
## Benefits of Sequential GUIDs |
||||
|
|
||||
|
Let’s say you’re inserting 1M rows into a table with a clustered primary key: |
||||
|
|
||||
|
* **Random GUIDs** → fragmentation ~99%, insert throughput tanks. |
||||
|
|
||||
|
* **Sequential GUIDs** → fragmentation stays low, inserts fly. |
||||
|
|
||||
|
In high-volume systems, this difference is **not** academic, it’s the difference between smooth scaling and spending weekends rebuilding indexes. |
||||
|
|
||||
|
## When to Use Sequential GUIDs |
||||
|
|
||||
|
* **Distributed systems** that still want DB-friendly inserts. |
||||
|
|
||||
|
* **High-write workloads** with clustered indexes on GUID PKs. |
||||
|
|
||||
|
* **Multi-tenant apps** where IDs need to be unique across tenants. |
||||
|
|
||||
|
## When Random GUIDs Still Make Sense |
||||
|
|
||||
|
* Security through obscurity, if you don’t want IDs to hint at creation order. |
||||
|
|
||||
|
* Non-indexed identifiers, fragmentation isn’t a concern. |
||||
|
|
||||
|
## The Final Take |
||||
|
|
||||
|
ABP’s default sequential GUID generation is one of those “**small but huge**” features. It’s the kind of thing you don’t notice until you benchmark, and then you wonder why you ever lived without it. |
||||
|
|
||||
|
## Links |
||||
|
You may want to check the following references to learn more about sequential GUIDs: |
||||
|
|
||||
|
- [ABP Framework Documentation: Sequential GUIDs](https://docs.abp.io/en/abp/latest/Guid-Generation) |
||||
{kind=link}
|
After Width: | Height: | Size: 205 KiB |
{kind=link}
|
After Width: | Height: | Size: 531 KiB |
@ -0,0 +1,72 @@ |
|||||
|
# Native AOT: How to Fasten Startup Time and Memory Footprint |
||||
|
|
||||
|
So since .NET 8 there's been one feature that’s quietly a game-changer for performance nerds is **Native AOT** (Ahead-of-Time compilation). If you’ve ever fought with sluggish cold starts (especially in containerized or serverless environments), or dealt with memory pressure from bloated apps, Native AOT might just be your new best friend. |
||||
|
|
||||
|
------ |
||||
|
|
||||
|
## What is Native AOT? |
||||
|
|
||||
|
Normally, .NET apps ship as IL (*Intermediate Language*) and JIT-compile at runtime. That’s flexible, but it takes longer startup time and memory. |
||||
|
Native AOT flips the script: your app gets compiled straight into a platform-specific binary *before it ever runs*. |
||||
|
|
||||
|
As a result; |
||||
|
|
||||
|
- No JIT overhead at startup. |
||||
|
- Smaller memory footprint (no JIT engine or IL sitting around). |
||||
|
- Faster startup (especially noticeable in microservices, functions, or CLI tools). |
||||
|
|
||||
|
------ |
||||
|
|
||||
|
## Advantages of AOT |
||||
|
|
||||
|
- **Broader support** → More workloads and libraries now play nice witt.h AOT. |
||||
|
- **Smaller output sizes** → Trimmed down runtime dependencies. |
||||
|
- **Better diagnostics** → Easier to figure out why your build blew up (because yes, AOT can be picky). |
||||
|
- **ASP.NET Core AOT** → Minimal APIs and gRPC services actually *benefit massively* here. Cold starts are crazy fast. |
||||
|
|
||||
|
------ |
||||
|
|
||||
|
## Why you should care |
||||
|
|
||||
|
If you’re building: |
||||
|
|
||||
|
- **Serverless apps (AWS Lambda, Azure Functions, GCP Cloud Run)** → Startup time matters a LOT. |
||||
|
- **Microservices** → Lightweight services scale better when they use less memory per pod. |
||||
|
- **CLI tools** → No one likes waiting half a second for a tool to boot. AOT makes them feel “native” (because they literally are). |
||||
|
|
||||
|
And yeah, you *can* get Go-like startup performance in .NET now. |
||||
|
|
||||
|
------ |
||||
|
|
||||
|
## The trade-offs (because nothing’s free) |
||||
|
|
||||
|
Native AOT isn’t a silver bullet: |
||||
|
|
||||
|
- Build times are longer (the compiler does all the heavy lifting upfront). |
||||
|
- Less runtime flexibility (no reflection-based magic, dynamic codegen, or IL rewriting). |
||||
|
- Debugging can be trickier. |
||||
|
|
||||
|
Basically: if you rely heavily on reflection-heavy libs or dynamic runtime stuff, expect pain. |
||||
|
|
||||
|
------ |
||||
|
|
||||
|
## Quick demo (conceptual) |
||||
|
|
||||
|
```bash |
||||
|
# Regular publish |
||||
|
dotnet publish -c Release |
||||
|
|
||||
|
# Native AOT publish |
||||
|
dotnet publish -c Release -r win-x64 -p:PublishAot=true |
||||
|
``` |
||||
|
|
||||
|
Boom. You get a native executable. On Linux, drop it into a container and watch that startup time drop like a rock. |
||||
|
|
||||
|
------ |
||||
|
|
||||
|
### Conclusion |
||||
|
|
||||
|
- Native AOT in .NET 8 = faster cold starts + lower memory usage. |
||||
|
- Perfect for microservices, serverless, and CLI apps. |
||||
|
- Comes with trade-offs (longer builds, less dynamic flexibility). |
||||
|
- If performance is critical, it’s absolutely worth testing. |
||||
{kind=link}
|
After Width: | Height: | Size: 39 KiB |
@ -0,0 +1,561 @@ |
|||||
|
# Building Dynamic Forms in Angular for Enterprise Applications |
||||
|
|
||||
|
## Introduction |
||||
|
|
||||
|
Dynamic forms are useful for enterprise applications where form structures need to be flexible, configurable, and generated at runtime based on business requirements. This approach allows developers to create forms from configuration objects rather than hardcoding them, enabling greater flexibility and maintainability. |
||||
|
|
||||
|
## Benefits |
||||
|
|
||||
|
1. **Flexibility**: Forms can be easily modified without changing the code. |
||||
|
2. **Reusability**: Form components can be shared across components. |
||||
|
3. **Maintainability**: Changes to form structures can be managed through configuration files or databases. |
||||
|
4. **Scalability**: New form fields and types can be added without significant code changes. |
||||
|
4. **User Experience**: Dynamic forms can adapt to user roles and permissions, providing a tailored experience. |
||||
|
|
||||
|
## Architecture |
||||
|
|
||||
|
### 1. Defining Form Configuration Models |
||||
|
|
||||
|
We will define form configuration model as a first step. This models stores field types, labels, validation rules, and other metadata. |
||||
|
|
||||
|
#### 1.1. Form Field Configuration |
||||
|
Form field configuration interface represents individual form fields and contains properties like type, label, validation rules and conditional logic. |
||||
|
```typescript |
||||
|
export interface FormFieldConfig { |
||||
|
key: string; |
||||
|
value?: any; |
||||
|
type: 'text' | 'email' | 'number' | 'select' | 'checkbox' | 'date' | 'textarea'; |
||||
|
label: string; |
||||
|
placeholder?: string; |
||||
|
required?: boolean; |
||||
|
disabled?: boolean; |
||||
|
options?: { key: string; value: any }[]; |
||||
|
validators?: ValidatorConfig[]; // Custom validators |
||||
|
conditionalLogic?: ConditionalRule[]; // For showing/hiding fields based on other field values |
||||
|
order?: number; // For ordering fields in the form |
||||
|
gridSize?: number; // For layout purposes, e.g., Bootstrap grid size (1-12) |
||||
|
} |
||||
|
``` |
||||
|
#### 1.2. Validator Configuration |
||||
|
|
||||
|
Validator configuration interface defines validation rules for form fields. |
||||
|
```typescript |
||||
|
export interface ValidatorConfig { |
||||
|
type: 'required' | 'email' | 'minLength' | 'maxLength' | 'pattern' | 'custom'; |
||||
|
value?: any; |
||||
|
message: string; |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
#### 1.3. Conditional Logic |
||||
|
|
||||
|
Conditional logic interface defines rules for showing/hiding or enabling/disabling fields based on other field values. |
||||
|
```typescript |
||||
|
export interface ConditionalRule { |
||||
|
dependsOn: string; |
||||
|
condition: 'equals' | 'notEquals' | 'contains' | 'greaterThan' | 'lessThan'; |
||||
|
value: any; |
||||
|
action: 'show' | 'hide' | 'enable' | 'disable'; |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
### 2. Dynamic Form Service |
||||
|
|
||||
|
We will create dynamic form service to handle form creation and validation processes. |
||||
|
|
||||
|
```typescript |
||||
|
@Injectable({ |
||||
|
providedIn: 'root' |
||||
|
}) |
||||
|
export class DynamicFormService { |
||||
|
|
||||
|
// Create form group based on fields |
||||
|
createFormGroup(fields: FormFieldConfig[]): FormGroup { |
||||
|
const group: any = {}; |
||||
|
|
||||
|
fields.forEach(field => { |
||||
|
const validators = this.buildValidators(field.validators || []); |
||||
|
const initialValue = this.getInitialValue(field); |
||||
|
|
||||
|
group[field.key] = new FormControl({ |
||||
|
value: initialValue, |
||||
|
disabled: field.disabled || false |
||||
|
}, validators); |
||||
|
}); |
||||
|
|
||||
|
return new FormGroup(group); |
||||
|
} |
||||
|
|
||||
|
// Returns an array of form field validators based on the validator configurations |
||||
|
private buildValidators(validatorConfigs: ValidatorConfig[]): ValidatorFn[] { |
||||
|
return validatorConfigs.map(config => { |
||||
|
switch (config.type) { |
||||
|
case 'required': |
||||
|
return Validators.required; |
||||
|
case 'email': |
||||
|
return Validators.email; |
||||
|
case 'minLength': |
||||
|
return Validators.minLength(config.value); |
||||
|
case 'maxLength': |
||||
|
return Validators.maxLength(config.value); |
||||
|
case 'pattern': |
||||
|
return Validators.pattern(config.value); |
||||
|
default: |
||||
|
return Validators.nullValidator; |
||||
|
} |
||||
|
}); |
||||
|
} |
||||
|
|
||||
|
private getInitialValue(field: FormFieldConfig): any { |
||||
|
switch (field.type) { |
||||
|
case 'checkbox': |
||||
|
return false; |
||||
|
case 'number': |
||||
|
return 0; |
||||
|
default: |
||||
|
return ''; |
||||
|
} |
||||
|
} |
||||
|
} |
||||
|
|
||||
|
``` |
||||
|
|
||||
|
### 3. Dynamic Form Component |
||||
|
|
||||
|
The main component that renders the form based on the configuration it receives as input. |
||||
|
```typescript |
||||
|
@Component({ |
||||
|
selector: 'app-dynamic-form', |
||||
|
template: ` |
||||
|
<form [formGroup]="dynamicForm" (ngSubmit)="onSubmit()" class="dynamic-form"> |
||||
|
@for (field of sortedFields; track field.key) { |
||||
|
<div class="row"> |
||||
|
<div [ngClass]="'col-md-' + (field.gridSize || 12)"> |
||||
|
<app-dynamic-form-field |
||||
|
[field]="field" |
||||
|
[form]="dynamicForm" |
||||
|
[isVisible]="isFieldVisible(field)" |
||||
|
(fieldChange)="onFieldChange($event)"> |
||||
|
</app-dynamic-form-field> |
||||
|
</div> |
||||
|
</div> |
||||
|
} |
||||
|
<div class="form-actions"> |
||||
|
<button |
||||
|
type="button" |
||||
|
class="btn btn-secondary" |
||||
|
(click)="onCancel()"> |
||||
|
Cancel |
||||
|
</button> |
||||
|
<button |
||||
|
type="submit" |
||||
|
class="btn btn-primary" |
||||
|
[disabled]="!dynamicForm.valid || isSubmitting"> |
||||
|
{{ submitButtonText() }} |
||||
|
</button> |
||||
|
</div> |
||||
|
</form> |
||||
|
`, |
||||
|
styles: [` |
||||
|
.dynamic-form { |
||||
|
display: flex; |
||||
|
gap: 0.5rem; |
||||
|
flex-direction: column; |
||||
|
} |
||||
|
.form-actions { |
||||
|
display: flex; |
||||
|
justify-content: flex-end; |
||||
|
gap: 0.5rem; |
||||
|
} |
||||
|
`], |
||||
|
imports: [ReactiveFormsModule, CommonModule, DynamicFormFieldComponent], |
||||
|
}) |
||||
|
export class DynamicFormComponent implements OnInit { |
||||
|
fields = input<FormFieldConfig[]>([]); |
||||
|
submitButtonText = input<string>('Submit'); |
||||
|
formSubmit = output<any>(); |
||||
|
formCancel = output<void>(); |
||||
|
private dynamicFormService = inject(DynamicFormService); |
||||
|
|
||||
|
dynamicForm!: FormGroup; |
||||
|
isSubmitting = false; |
||||
|
fieldVisibility: { [key: string]: boolean } = {}; |
||||
|
|
||||
|
ngOnInit() { |
||||
|
this.dynamicForm = this.dynamicFormService.createFormGroup(this.fields()); |
||||
|
this.initializeFieldVisibility(); |
||||
|
this.setupConditionalLogic(); |
||||
|
} |
||||
|
|
||||
|
get sortedFields(): FormFieldConfig[] { |
||||
|
return this.fields().sort((a, b) => (a.order || 0) - (b.order || 0)); |
||||
|
} |
||||
|
|
||||
|
onSubmit() { |
||||
|
if (this.dynamicForm.valid) { |
||||
|
this.isSubmitting = true; |
||||
|
this.formSubmit.emit(this.dynamicForm.value); |
||||
|
} else { |
||||
|
this.markAllFieldsAsTouched(); |
||||
|
} |
||||
|
} |
||||
|
|
||||
|
onCancel() { |
||||
|
this.formCancel.emit(); |
||||
|
} |
||||
|
|
||||
|
onFieldChange(event: { fieldKey: string; value: any }) { |
||||
|
this.evaluateConditionalLogic(event.fieldKey); |
||||
|
} |
||||
|
|
||||
|
isFieldVisible(field: FormFieldConfig): boolean { |
||||
|
return this.fieldVisibility[field.key] !== false; |
||||
|
} |
||||
|
|
||||
|
private initializeFieldVisibility() { |
||||
|
this.fields().forEach(field => { |
||||
|
this.fieldVisibility[field.key] = !field.conditionalLogic?.length; |
||||
|
}); |
||||
|
} |
||||
|
|
||||
|
private setupConditionalLogic() { |
||||
|
this.fields().forEach(field => { |
||||
|
if (field.conditionalLogic) { |
||||
|
field.conditionalLogic.forEach(rule => { |
||||
|
const dependentControl = this.dynamicForm.get(rule.dependsOn); |
||||
|
if (dependentControl) { |
||||
|
dependentControl.valueChanges.subscribe(() => { |
||||
|
this.evaluateConditionalLogic(field.key); |
||||
|
}); |
||||
|
} |
||||
|
}); |
||||
|
} |
||||
|
}); |
||||
|
} |
||||
|
|
||||
|
private evaluateConditionalLogic(fieldKey: string) { |
||||
|
const field = this.fields().find(f => f.key === fieldKey); |
||||
|
if (!field?.conditionalLogic) return; |
||||
|
|
||||
|
field.conditionalLogic.forEach(rule => { |
||||
|
const dependentValue = this.dynamicForm.get(rule.dependsOn)?.value; |
||||
|
const conditionMet = this.evaluateCondition(dependentValue, rule.condition, rule.value); |
||||
|
|
||||
|
this.applyConditionalAction(fieldKey, rule.action, conditionMet); |
||||
|
}); |
||||
|
} |
||||
|
|
||||
|
private evaluateCondition(fieldValue: any, condition: string, ruleValue: any): boolean { |
||||
|
switch (condition) { |
||||
|
case 'equals': |
||||
|
return fieldValue === ruleValue; |
||||
|
case 'notEquals': |
||||
|
return fieldValue !== ruleValue; |
||||
|
case 'contains': |
||||
|
return fieldValue && fieldValue.includes && fieldValue.includes(ruleValue); |
||||
|
case 'greaterThan': |
||||
|
return Number(fieldValue) > Number(ruleValue); |
||||
|
case 'lessThan': |
||||
|
return Number(fieldValue) < Number(ruleValue); |
||||
|
default: |
||||
|
return false; |
||||
|
} |
||||
|
} |
||||
|
|
||||
|
private applyConditionalAction(fieldKey: string, action: string, shouldApply: boolean) { |
||||
|
const control = this.dynamicForm.get(fieldKey); |
||||
|
|
||||
|
switch (action) { |
||||
|
case 'show': |
||||
|
this.fieldVisibility[fieldKey] = shouldApply; |
||||
|
break; |
||||
|
case 'hide': |
||||
|
this.fieldVisibility[fieldKey] = !shouldApply; |
||||
|
break; |
||||
|
case 'enable': |
||||
|
if (control) { |
||||
|
shouldApply ? control.enable() : control.disable(); |
||||
|
} |
||||
|
break; |
||||
|
case 'disable': |
||||
|
if (control) { |
||||
|
shouldApply ? control.disable() : control.enable(); |
||||
|
} |
||||
|
break; |
||||
|
} |
||||
|
} |
||||
|
|
||||
|
private markAllFieldsAsTouched() { |
||||
|
Object.keys(this.dynamicForm.controls).forEach(key => { |
||||
|
this.dynamicForm.get(key)?.markAsTouched(); |
||||
|
}); |
||||
|
} |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
### 4. Dynamic Form Field Component |
||||
|
|
||||
|
This component renders individual form fields, handling different types and validation messages based on the configuration. |
||||
|
```typescript |
||||
|
@Component({ |
||||
|
selector: 'app-dynamic-form-field', |
||||
|
template: ` |
||||
|
@if (isVisible) { |
||||
|
<div class="field-container" [formGroup]="form"> |
||||
|
|
||||
|
@if (field.type === 'text') { |
||||
|
<!-- Text Input --> |
||||
|
<div class="form-group"> |
||||
|
<label [for]="field.key">{{ field.label }}</label> |
||||
|
<input |
||||
|
[id]="field.key" |
||||
|
[formControlName]="field.key" |
||||
|
[placeholder]="field.placeholder || ''" |
||||
|
class="form-control" |
||||
|
[class.is-invalid]="isFieldInvalid()"> |
||||
|
@if (isFieldInvalid()) { |
||||
|
<div class="invalid-feedback"> |
||||
|
{{ getErrorMessage() }} |
||||
|
</div> |
||||
|
} |
||||
|
</div> |
||||
|
} @else if (field.type === 'select') { |
||||
|
<!-- Select Dropdown --> |
||||
|
<div class="form-group"> |
||||
|
<label [for]="field.key">{{ field.label }}</label> |
||||
|
<select |
||||
|
[id]="field.key" |
||||
|
[formControlName]="field.key" |
||||
|
class="form-control" |
||||
|
[class.is-invalid]="isFieldInvalid()"> |
||||
|
<option value="">Please select...</option> |
||||
|
@for (option of field.options; track option.key) { |
||||
|
<option |
||||
|
[value]="option.key"> |
||||
|
{{ option.value }} |
||||
|
</option> |
||||
|
} |
||||
|
</select> |
||||
|
@if (isFieldInvalid()) { |
||||
|
<div class="invalid-feedback"> |
||||
|
{{ getErrorMessage() }} |
||||
|
</div> |
||||
|
} |
||||
|
</div> |
||||
|
} @else if (field.type === 'checkbox') { |
||||
|
<!-- Checkbox --> |
||||
|
<div class="form-group form-check"> |
||||
|
<input |
||||
|
type="checkbox" |
||||
|
[id]="field.key" |
||||
|
[formControlName]="field.key" |
||||
|
class="form-check-input" |
||||
|
[class.is-invalid]="isFieldInvalid()"> |
||||
|
<label class="form-check-label" [for]="field.key"> |
||||
|
{{ field.label }} |
||||
|
</label> |
||||
|
@if (isFieldInvalid()) { |
||||
|
<div class="invalid-feedback"> |
||||
|
{{ getErrorMessage() }} |
||||
|
</div> |
||||
|
} |
||||
|
</div> |
||||
|
} @else if (field.type === 'email') { |
||||
|
<!-- Email Input --> |
||||
|
<div class="form-group"> |
||||
|
<label [for]="field.key">{{ field.label }}</label> |
||||
|
<input |
||||
|
type="email" |
||||
|
[id]="field.key" |
||||
|
[formControlName]="field.key" |
||||
|
[placeholder]="field.placeholder || ''" |
||||
|
class="form-control" |
||||
|
[class.is-invalid]="isFieldInvalid()"> |
||||
|
@if (isFieldInvalid()) { |
||||
|
<div class="invalid-feedback"> |
||||
|
{{ getErrorMessage() }} |
||||
|
</div> |
||||
|
} |
||||
|
</div> |
||||
|
} @else if (field.type === 'textarea') { |
||||
|
<!-- Textarea --> |
||||
|
<div class="form-group"> |
||||
|
<label [for]="field.key">{{ field.label }}</label> |
||||
|
<textarea |
||||
|
[id]="field.key" |
||||
|
[formControlName]="field.key" |
||||
|
[placeholder]="field.placeholder || ''" |
||||
|
rows="4" |
||||
|
class="form-control" |
||||
|
[class.is-invalid]="isFieldInvalid()"> |
||||
|
</textarea> |
||||
|
@if (isFieldInvalid()) { |
||||
|
<div class="invalid-feedback"> |
||||
|
{{ getErrorMessage() }} |
||||
|
</div> |
||||
|
} |
||||
|
</div> |
||||
|
} |
||||
|
</div> |
||||
|
<!-- Add more field types as needed--> |
||||
|
} |
||||
|
`, |
||||
|
imports: [ReactiveFormsModule], |
||||
|
}) |
||||
|
export class DynamicFormFieldComponent implements OnInit { |
||||
|
@Input() field!: FormFieldConfig; |
||||
|
@Input() form!: FormGroup; |
||||
|
@Input() isVisible: boolean = true; |
||||
|
@Output() fieldChange = new EventEmitter<{ fieldKey: string; value: any }>(); |
||||
|
|
||||
|
ngOnInit() { |
||||
|
const control = this.form.get(this.field.key); |
||||
|
if (control) { |
||||
|
control.valueChanges.subscribe(value => { |
||||
|
this.fieldChange.emit({ fieldKey: this.field.key, value }); |
||||
|
}); |
||||
|
} |
||||
|
} |
||||
|
|
||||
|
isFieldInvalid(): boolean { |
||||
|
const control = this.form.get(this.field.key); |
||||
|
return !!(control && control.invalid && (control.dirty || control.touched)); |
||||
|
} |
||||
|
|
||||
|
getErrorMessage(): string { |
||||
|
const control = this.form.get(this.field.key); |
||||
|
if (!control || !control.errors) return ''; |
||||
|
|
||||
|
const validators = this.field.validators || []; |
||||
|
|
||||
|
for (const validator of validators) { |
||||
|
if (control.errors[validator.type]) { |
||||
|
return validator.message; |
||||
|
} |
||||
|
} |
||||
|
|
||||
|
// Fallback error messages |
||||
|
if (control.errors['required']) return `${this.field.label} is required`; |
||||
|
if (control.errors['email']) return 'Please enter a valid email address'; |
||||
|
if (control.errors['minlength']) return `Minimum length is ${control.errors['minlength'].requiredLength}`; |
||||
|
if (control.errors['maxlength']) return `Maximum length is ${control.errors['maxlength'].requiredLength}`; |
||||
|
|
||||
|
return 'Invalid input'; |
||||
|
} |
||||
|
} |
||||
|
|
||||
|
``` |
||||
|
|
||||
|
### 5. Usage Example |
||||
|
|
||||
|
```typescript |
||||
|
|
||||
|
@Component({ |
||||
|
selector: 'app-home', |
||||
|
template: ` |
||||
|
<div class="row"> |
||||
|
<div class="col-4 offset-4"> |
||||
|
<app-dynamic-form |
||||
|
[fields]="formFields" |
||||
|
submitButtonText="Save User" |
||||
|
(formSubmit)="onSubmit($event)" |
||||
|
(formCancel)="onCancel()"> |
||||
|
</app-dynamic-form> |
||||
|
</div> |
||||
|
</div> |
||||
|
`, |
||||
|
imports: [DynamicFormComponent] |
||||
|
}) |
||||
|
export class HomeComponent { |
||||
|
@Input() title: string = 'Home Component'; |
||||
|
formFields: FormFieldConfig[] = [ |
||||
|
{ |
||||
|
key: 'firstName', |
||||
|
type: 'text', |
||||
|
label: 'First Name', |
||||
|
placeholder: 'Enter first name', |
||||
|
required: true, |
||||
|
validators: [ |
||||
|
{ type: 'required', message: 'First name is required' }, |
||||
|
{ type: 'minLength', value: 2, message: 'Minimum 2 characters required' } |
||||
|
], |
||||
|
gridSize: 12, |
||||
|
order: 1 |
||||
|
}, |
||||
|
{ |
||||
|
key: 'lastName', |
||||
|
type: 'text', |
||||
|
label: 'Last Name', |
||||
|
placeholder: 'Enter last name', |
||||
|
required: true, |
||||
|
validators: [ |
||||
|
{ type: 'required', message: 'Last name is required' } |
||||
|
], |
||||
|
gridSize: 12, |
||||
|
order: 2 |
||||
|
}, |
||||
|
{ |
||||
|
key: 'email', |
||||
|
type: 'email', |
||||
|
label: 'Email Address', |
||||
|
placeholder: 'Enter email', |
||||
|
required: true, |
||||
|
validators: [ |
||||
|
{ type: 'required', message: 'Email is required' }, |
||||
|
{ type: 'email', message: 'Please enter a valid email' } |
||||
|
], |
||||
|
order: 3 |
||||
|
}, |
||||
|
{ |
||||
|
key: 'userType', |
||||
|
type: 'select', |
||||
|
label: 'User Type', |
||||
|
required: true, |
||||
|
options: [ |
||||
|
{ key: 'admin', value: 'Administrator' }, |
||||
|
{ key: 'user', value: 'Regular User' }, |
||||
|
{ key: 'guest', value: 'Guest User' } |
||||
|
], |
||||
|
validators: [ |
||||
|
{ type: 'required', message: 'Please select user type' } |
||||
|
], |
||||
|
order: 4 |
||||
|
}, |
||||
|
{ |
||||
|
key: 'adminNotes', |
||||
|
type: 'textarea', |
||||
|
label: 'Admin Notes', |
||||
|
placeholder: 'Enter admin-specific notes', |
||||
|
conditionalLogic: [ |
||||
|
{ |
||||
|
dependsOn: 'userType', |
||||
|
condition: 'equals', |
||||
|
value: 'admin', |
||||
|
action: 'show' |
||||
|
} |
||||
|
], |
||||
|
order: 5 |
||||
|
} |
||||
|
]; |
||||
|
|
||||
|
onSubmit(formData: any) { |
||||
|
console.log('Form submitted:', formData); |
||||
|
// Handle form submission |
||||
|
} |
||||
|
|
||||
|
onCancel() { |
||||
|
console.log('Form cancelled'); |
||||
|
// Handle form cancellation |
||||
|
} |
||||
|
} |
||||
|
|
||||
|
|
||||
|
``` |
||||
|
|
||||
|
## Result |
||||
|
|
||||
|
 |
||||
|
|
||||
|
## Conclusion |
||||
|
|
||||
|
These kinds of components are essential for large applications because they allow for rapid development and easy maintenance. By defining forms through configuration, developers can quickly adapt to changing requirements without extensive code changes. This approach also promotes consistency across the application, as the same form components can be reused in different contexts. |
||||
@ -0,0 +1,660 @@ |
|||||
|
# Building Scalable Angular Apps with Reusable UI Components |
||||
|
|
||||
|
Frontend development keeps evolving at an incredible pace, and with every new update, our implementation standards improve as well. But even as tools and frameworks change, the core principles stay the same, and one of the most important is reusability. |
||||
|
|
||||
|
Reusability means building components and utilities that can be used in multiple places instead of using the same logic repeatedly. This approach not only saves time but also keeps your code clean, consistent, and easier to maintain as your project grows. |
||||
|
|
||||
|
Angular fully embraces this idea by offering modern features like **standalone components**, **signals**, **hybrid rendering**, and **component-level lazy loading**. |
||||
|
|
||||
|
In this article, we will explore how these features make it easier to build reusable UI components. We will also look at how to style them and organize them into shared libraries for scalable, long-term development. |
||||
|
|
||||
|
--- |
||||
|
|
||||
|
## 🧩 Breaking Down Components for True Reusability |
||||
|
|
||||
|
The first approach to make an Angular component reusable is to use standalone components. As this feature has been supported for a long time, it is now the default behavior for the latest Angular versions. Keeping that in mind, we can ensure reusability by separating a big component into smaller ones to make the small pieces usable across the application. |
||||
|
|
||||
|
Here is a quick example: |
||||
|
|
||||
|
Imagine you start with a single `UserProfileComponent` that does everything including displaying user info, recent posts, a list of friends, and even handling profile editing. |
||||
|
|
||||
|
```ts |
||||
|
// 📖 Compact user profile component |
||||
|
import { Component } from "@angular/core"; |
||||
|
|
||||
|
@Component({ |
||||
|
selector: "app-user-profile", |
||||
|
template: ` |
||||
|
<section class="profile"> |
||||
|
<div class="header"> |
||||
|
<img [src]="user.avatar" alt="User avatar" /> |
||||
|
<h2>{{ user.name }}</h2> |
||||
|
<button (click)="editProfile()">Edit</button> |
||||
|
</div> |
||||
|
|
||||
|
<div class="posts"> |
||||
|
<h3>Recent Posts</h3> |
||||
|
<ul> |
||||
|
@for (post of user.posts; track post) { |
||||
|
<li>{{ post }}</li> |
||||
|
} |
||||
|
</ul> |
||||
|
</div> |
||||
|
|
||||
|
<div class="friends"> |
||||
|
<h3>Friends</h3> |
||||
|
<ul> |
||||
|
@for (friend of user.friends; track friend) { |
||||
|
<li>{{ friend }}</li> |
||||
|
} |
||||
|
</ul> |
||||
|
</div> |
||||
|
</section> |
||||
|
`, |
||||
|
}) |
||||
|
export class UserProfileComponent { |
||||
|
user = { |
||||
|
name: "Jane Doe", |
||||
|
avatar: "/assets/avatar.png", |
||||
|
posts: ["Angular Tips", "Reusable Components FTW!"], |
||||
|
friends: ["John", "Mary", "Steve"], |
||||
|
}; |
||||
|
|
||||
|
editProfile() { |
||||
|
console.log("Editing profile..."); |
||||
|
} |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
Instead of this, you can create small components like these: |
||||
|
|
||||
|
- `user-avatar.component.ts` |
||||
|
- `user-posts.component.ts` |
||||
|
- `user-friends.component.ts` |
||||
|
|
||||
|
```ts |
||||
|
// 🧩 user-avatar.component.ts |
||||
|
import { Component, input } from "@angular/core"; |
||||
|
|
||||
|
@Component({ |
||||
|
selector: "app-user-avatar", |
||||
|
template: ` |
||||
|
<div class="user-avatar"> |
||||
|
<img [src]="avatar()" alt="User avatar" /> |
||||
|
<h2>{{ name() }}</h2> |
||||
|
</div> |
||||
|
`, |
||||
|
}) |
||||
|
export class UserAvatarComponent { |
||||
|
name = input.required<string>(); |
||||
|
avatar = input.required<string>(); |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
```ts |
||||
|
// 🧩 user-posts.component.ts |
||||
|
import { Component, input } from "@angular/core"; |
||||
|
|
||||
|
@Component({ |
||||
|
selector: "app-user-posts", |
||||
|
template: ` |
||||
|
<div class="user-posts"> |
||||
|
<h3>Recent Posts</h3> |
||||
|
<ul> |
||||
|
@for (post of posts(); track post) { |
||||
|
<li>{{ post }}</li> |
||||
|
} |
||||
|
</ul> |
||||
|
</div> |
||||
|
`, |
||||
|
}) |
||||
|
export class UserPostsComponent { |
||||
|
posts = input<string[]>([]); |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
```ts |
||||
|
// 🧩 user-friends.component.ts |
||||
|
import { Component, input, output } from "@angular/core"; |
||||
|
|
||||
|
@Component({ |
||||
|
selector: "app-user-friends", |
||||
|
template: ` |
||||
|
<div class="user-friends"> |
||||
|
<h3>Friends</h3> |
||||
|
<ul> |
||||
|
@for (friend of friends(); track friend) { |
||||
|
<li (click)="selectFriend(friend)">{{ friend }}</li> |
||||
|
} |
||||
|
</ul> |
||||
|
</div> |
||||
|
`, |
||||
|
}) |
||||
|
export class UserFriendsComponent { |
||||
|
friends = input<string[]>([]); |
||||
|
friendSelected = output<string>(); |
||||
|
|
||||
|
selectFriend(friend: string) { |
||||
|
this.friendSelected.emit(friend); |
||||
|
} |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
Then, you can use them in a container component like this |
||||
|
|
||||
|
```ts |
||||
|
// 🧩 new user profile components that uses other user components |
||||
|
import { Component } from "@angular/core"; |
||||
|
import { signal } from "@angular/core"; |
||||
|
import { UserAvatarComponent } from "./user-avatar.component"; |
||||
|
import { UserPostsComponent } from "./user-posts.component"; |
||||
|
import { UserFriendsComponent } from "./user-friends.component"; |
||||
|
|
||||
|
@Component({ |
||||
|
selector: "app-user-profile", |
||||
|
imports: [UserAvatarComponent, UserPostsComponent, UserFriendsComponent], |
||||
|
template: ` |
||||
|
<section class="profile"> |
||||
|
<app-user-avatar [name]="user().name" [avatar]="user().avatar" /> |
||||
|
<app-user-posts [posts]="user().posts" /> |
||||
|
<app-user-friends |
||||
|
[friends]="user().friends" |
||||
|
(friendSelected)="onFriendSelected($event)" |
||||
|
/> |
||||
|
</section> |
||||
|
`, |
||||
|
}) |
||||
|
export class UserProfileComponent { |
||||
|
user = signal({ |
||||
|
name: "Jane Doe", |
||||
|
avatar: "/assets/avatar.png", |
||||
|
posts: ["Angular Tips", "Reusable Components FTW!"], |
||||
|
friends: ["John", "Mary", "Steve"], |
||||
|
}); |
||||
|
|
||||
|
onFriendSelected(friend: string) { |
||||
|
console.log(`Selected friend: ${friend}`); |
||||
|
} |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
The most common problem of creating such components is over-creating new elements when you actually do not need them. So, it is a design decision that needs to be carefully taken while building the application. If misused, it can lead to: |
||||
|
|
||||
|
- a management nightmare |
||||
|
- unnecessary lifecycle hook complexity |
||||
|
- extra indirect data flow (makes debugging harder) |
||||
|
|
||||
|
Nevertheless, this makes the app more scalable and maintainable if correctly used. Such structure will provide: |
||||
|
|
||||
|
- a clear separation of concerns as each component will maintain decided tasks |
||||
|
- faster feature development |
||||
|
- shared libraries or elements across the application |
||||
|
|
||||
|
--- |
||||
|
|
||||
|
## 🚀 Why Standalone Components Matter |
||||
|
|
||||
|
As Angular has announced standalone components starting from version 17, they have been gradually developing features that support reusability. This important feature brings a great migration for components, directives, and pipes. |
||||
|
|
||||
|
Since it allows these elements to be used directly inside an `imports` array rather than through a module structure, it reinforces reusability patterns and simplifies management. |
||||
|
|
||||
|
Back in the module-based structure, we used to create these components and declare them in modules. This still offers some reusability, as we can import the modules where needed. However, standalone components can be consumed both by other standalone components and modules. For this reason, migrating from the module-based structure to a fully standalone architecture brings many benefits for this concern. |
||||
|
|
||||
|
--- |
||||
|
|
||||
|
## 🧠 Designing Components That Scale and Reuse Well |
||||
|
|
||||
|
The first point you need to consider here is to encapsulate and isolate logic. |
||||
|
|
||||
|
For example: |
||||
|
|
||||
|
1. This counter component isolates the concept of incrementing/decrementing so the parent component will not take care of this logic except showing the result. |
||||
|
|
||||
|
```ts |
||||
|
import { Component, signal } from "@angular/core"; |
||||
|
|
||||
|
@Component({ |
||||
|
selector: "app-counter", |
||||
|
template: ` |
||||
|
<button (click)="decrement()">-</button> |
||||
|
<span>{{ count() }}</span> |
||||
|
<button (click)="increment()">+</button> |
||||
|
`, |
||||
|
}) |
||||
|
export class CounterComponent { |
||||
|
private count = signal(0); // internal state |
||||
|
|
||||
|
increment() { |
||||
|
this.count.update((v) => v + 1); |
||||
|
} |
||||
|
decrement() { |
||||
|
this.count.update((v) => v - 1); |
||||
|
} |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
2. This component isolates the styles and makes the badge reusable. Styles in this component will not leak out to others, and global styles will not affect it. |
||||
|
|
||||
|
```ts |
||||
|
import { Component, ViewEncapsulation } from "@angular/core"; |
||||
|
|
||||
|
@Component({ |
||||
|
selector: "app-badge", |
||||
|
template: `<span class="badge">{{ label }}</span>`, |
||||
|
styles: [ |
||||
|
` |
||||
|
.badge { |
||||
|
background: #007bff; |
||||
|
color: white; |
||||
|
padding: 4px 8px; |
||||
|
border-radius: 4px; |
||||
|
} |
||||
|
`, |
||||
|
], |
||||
|
encapsulation: ViewEncapsulation.Emulated, // default; isolates CSS |
||||
|
}) |
||||
|
export class BadgeComponent { |
||||
|
label = "New"; |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
3. The search component below is a very common example since it handles a business logic exposing simple inputs/outputs |
||||
|
|
||||
|
```ts |
||||
|
import { Component, input, output } from "@angular/core"; |
||||
|
|
||||
|
@Component({ |
||||
|
selector: "app-search-box", |
||||
|
template: ` |
||||
|
<input |
||||
|
type="text" |
||||
|
[value]="query()" |
||||
|
(input)="onChange($event)" |
||||
|
placeholder="Search..." |
||||
|
/> |
||||
|
`, |
||||
|
}) |
||||
|
export class SearchBoxComponent { |
||||
|
query = input<string>(""); |
||||
|
changed = output<string>(); |
||||
|
|
||||
|
onChange(event: Event) { |
||||
|
const value = (event.target as HTMLInputElement).value; |
||||
|
this.changed.emit(value); |
||||
|
} |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
Encapsulation ensures that each component manages its own logic without leaking details to the outside. By keeping behavior self-contained, components become easier to understand, test, and reuse. This isolation prevents unexpected side effects, keeps your UI predictable, and allows each component to evolve independently as your application grows. |
||||
|
|
||||
|
At this point, we can also briefly mention smart and dumb components. Smart components handle business logic, while dumb components take care of displaying data and emitting user actions. |
||||
|
|
||||
|
This separation keeps your UI structure scalable. Smart components can change how data is loaded or handled without affecting presentation components, and dumb components can be reused anywhere since they just rely on inputs and outputs. |
||||
|
|
||||
|
```ts |
||||
|
// smart component (container) |
||||
|
@Component({ |
||||
|
selector: "app-user-profile", |
||||
|
imports: [UserCardComponent], |
||||
|
template: `<app-user-card [user]="user()" (select)="onSelect($event)" />`, |
||||
|
}) |
||||
|
export class UserProfileComponent { |
||||
|
user = signal({ name: "Jane", role: "Admin" }); |
||||
|
|
||||
|
onSelect(user: any) { |
||||
|
console.log("Selected user:", user); |
||||
|
} |
||||
|
} |
||||
|
|
||||
|
// dumb component (presentation) |
||||
|
@Component({ |
||||
|
selector: "app-user-card", |
||||
|
standalone: true, |
||||
|
template: ` |
||||
|
<div (click)="select.emit(user())" class="card"> |
||||
|
<h3>{{ user().name }}</h3> |
||||
|
<p>{{ user().role }}</p> |
||||
|
</div> |
||||
|
`, |
||||
|
}) |
||||
|
export class UserCardComponent { |
||||
|
user = input.required<{ name: string; role: string }>(); |
||||
|
select = output<{ name: string; role: string }>(); |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
--- |
||||
|
|
||||
|
## 🔁 Reusing Components Across the Application |
||||
|
|
||||
|
As there are many ways of reusing a component in the project, we will go over a real-life example. |
||||
|
|
||||
|
Here are two very common ABP components that can be reused anywhere in the app: |
||||
|
|
||||
|
```ts |
||||
|
//... |
||||
|
import { ABP } from "@abp/ng.core"; |
||||
|
|
||||
|
@Component({ |
||||
|
selector: "abp-button", |
||||
|
template: ` |
||||
|
<button |
||||
|
#button |
||||
|
[id]="buttonId" |
||||
|
[attr.type]="buttonType" |
||||
|
[attr.form]="formName" |
||||
|
[ngClass]="buttonClass" |
||||
|
[disabled]="loading || disabled" |
||||
|
(click.stop)="click.next($event); abpClick.next($event)" |
||||
|
(focus)="focus.next($event); abpFocus.next($event)" |
||||
|
(blur)="blur.next($event); abpBlur.next($event)" |
||||
|
> |
||||
|
<i [ngClass]="icon" class="me-1" aria-hidden="true"></i |
||||
|
><ng-content></ng-content> |
||||
|
</button> |
||||
|
`, |
||||
|
imports: [NgClass], |
||||
|
}) |
||||
|
export class ButtonComponent implements OnInit { |
||||
|
private renderer = inject(Renderer2); |
||||
|
|
||||
|
@Input() |
||||
|
buttonId = ""; |
||||
|
|
||||
|
@Input() |
||||
|
buttonClass = "btn btn-primary"; |
||||
|
|
||||
|
@Input() |
||||
|
buttonType = "button"; |
||||
|
|
||||
|
@Input() |
||||
|
formName?: string = undefined; |
||||
|
|
||||
|
@Input() |
||||
|
iconClass?: string; |
||||
|
|
||||
|
@Input() |
||||
|
loading = false; |
||||
|
|
||||
|
@Input() |
||||
|
disabled: boolean | undefined = false; |
||||
|
|
||||
|
@Input() |
||||
|
attributes?: ABP.Dictionary<string>; |
||||
|
|
||||
|
@Output() readonly click = new EventEmitter<MouseEvent>(); |
||||
|
|
||||
|
@Output() readonly focus = new EventEmitter<FocusEvent>(); |
||||
|
|
||||
|
@Output() readonly blur = new EventEmitter<FocusEvent>(); |
||||
|
|
||||
|
@Output() readonly abpClick = new EventEmitter<MouseEvent>(); |
||||
|
|
||||
|
@Output() readonly abpFocus = new EventEmitter<FocusEvent>(); |
||||
|
|
||||
|
@Output() readonly abpBlur = new EventEmitter<FocusEvent>(); |
||||
|
|
||||
|
@ViewChild("button", { static: true }) |
||||
|
buttonRef!: ElementRef<HTMLButtonElement>; |
||||
|
|
||||
|
get icon(): string { |
||||
|
return `${ |
||||
|
this.loading ? "fa fa-spinner fa-spin" : this.iconClass || "d-none" |
||||
|
}`; |
||||
|
} |
||||
|
|
||||
|
ngOnInit() { |
||||
|
if (this.attributes) { |
||||
|
Object.keys(this.attributes).forEach((key) => { |
||||
|
if (this.attributes?.[key]) { |
||||
|
this.renderer.setAttribute( |
||||
|
this.buttonRef.nativeElement, |
||||
|
key, |
||||
|
this.attributes[key] |
||||
|
); |
||||
|
} |
||||
|
}); |
||||
|
} |
||||
|
} |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
This button component can be used by simply importing the `ButtonComponent` and using the `<abp-button />` tag. |
||||
|
|
||||
|
You can reach the source code [here](https://github.com/abpframework/abp/blob/dev/npm/ng-packs/packages/theme-shared/src/lib/components/button/button.component.ts). |
||||
|
|
||||
|
This modal component is also commonly used. The source code is [here](https://github.com/abpframework/abp/blob/dev/npm/ng-packs/packages/theme-shared/src/lib/components/modal/modal.component.ts). |
||||
|
|
||||
|
```ts |
||||
|
//... |
||||
|
export type ModalSize = "sm" | "md" | "lg" | "xl"; |
||||
|
|
||||
|
@Component({ |
||||
|
selector: "abp-modal", |
||||
|
templateUrl: "./modal.component.html", |
||||
|
styleUrls: ["./modal.component.scss"], |
||||
|
providers: [SubscriptionService], |
||||
|
imports: [NgTemplateOutlet], |
||||
|
}) |
||||
|
export class ModalComponent implements OnInit, OnDestroy, DismissableModal { |
||||
|
protected readonly confirmationService = inject(ConfirmationService); |
||||
|
protected readonly modal = inject(NgbModal); |
||||
|
protected readonly modalRefService = inject(ModalRefService); |
||||
|
protected readonly suppressUnsavedChangesWarningToken = inject( |
||||
|
SUPPRESS_UNSAVED_CHANGES_WARNING, |
||||
|
{ |
||||
|
optional: true, |
||||
|
} |
||||
|
); |
||||
|
protected readonly destroyRef = inject(DestroyRef); |
||||
|
private document = inject(DOCUMENT); |
||||
|
|
||||
|
visible = model<boolean>(false); |
||||
|
|
||||
|
busy = input(false, { |
||||
|
transform: (value: boolean) => { |
||||
|
if (this.abpSubmit() && this.abpSubmit() instanceof ButtonComponent) { |
||||
|
this.abpSubmit().loading = value; |
||||
|
} |
||||
|
return value; |
||||
|
}, |
||||
|
}); |
||||
|
|
||||
|
options = input<NgbModalOptions>({ keyboard: true }); |
||||
|
|
||||
|
suppressUnsavedChangesWarning = input( |
||||
|
this.suppressUnsavedChangesWarningToken |
||||
|
); |
||||
|
|
||||
|
modalContent = viewChild<TemplateRef<any>>("modalContent"); |
||||
|
|
||||
|
abpHeader = contentChild<TemplateRef<any>>("abpHeader"); |
||||
|
|
||||
|
abpBody = contentChild<TemplateRef<any>>("abpBody"); |
||||
|
|
||||
|
abpFooter = contentChild<TemplateRef<any>>("abpFooter"); |
||||
|
|
||||
|
abpSubmit = contentChild(ButtonComponent, { read: ButtonComponent }); |
||||
|
|
||||
|
readonly init = output(); |
||||
|
|
||||
|
readonly appear = output(); |
||||
|
|
||||
|
readonly disappear = output(); |
||||
|
|
||||
|
modalRef!: NgbModalRef; |
||||
|
|
||||
|
isConfirmationOpen = false; |
||||
|
|
||||
|
modalIdentifier = `modal-${uuid()}`; |
||||
|
|
||||
|
get modalWindowRef() { |
||||
|
return this.document.querySelector( |
||||
|
`ngb-modal-window.${this.modalIdentifier}` |
||||
|
); |
||||
|
} |
||||
|
|
||||
|
get isFormDirty(): boolean { |
||||
|
return Boolean(this.modalWindowRef?.querySelector(".ng-dirty")); |
||||
|
} |
||||
|
|
||||
|
constructor() { |
||||
|
effect(() => { |
||||
|
this.toggle(this.visible()); |
||||
|
}); |
||||
|
} |
||||
|
|
||||
|
ngOnInit(): void { |
||||
|
this.modalRefService.register(this); |
||||
|
} |
||||
|
|
||||
|
dismiss(mode: ModalDismissMode) { |
||||
|
switch (mode) { |
||||
|
case "hard": |
||||
|
this.visible.set(false); |
||||
|
break; |
||||
|
case "soft": |
||||
|
this.close(); |
||||
|
break; |
||||
|
default: |
||||
|
break; |
||||
|
} |
||||
|
} |
||||
|
|
||||
|
protected toggle(value: boolean) { |
||||
|
this.visible.set(value); |
||||
|
|
||||
|
if (!value) { |
||||
|
this.modalRef?.dismiss(); |
||||
|
this.disappear.emit(); |
||||
|
return; |
||||
|
} |
||||
|
|
||||
|
setTimeout(() => this.listen(), 0); |
||||
|
this.modalRef = this.modal.open(this.modalContent(), { |
||||
|
size: "md", |
||||
|
centered: false, |
||||
|
keyboard: false, |
||||
|
scrollable: true, |
||||
|
beforeDismiss: () => { |
||||
|
if (!this.visible()) return true; |
||||
|
|
||||
|
this.close(); |
||||
|
return !this.visible(); |
||||
|
}, |
||||
|
...this.options(), |
||||
|
windowClass: `${this.options().windowClass || ""} ${ |
||||
|
this.modalIdentifier |
||||
|
}`, |
||||
|
}); |
||||
|
|
||||
|
this.appear.emit(); |
||||
|
} |
||||
|
|
||||
|
ngOnDestroy(): void { |
||||
|
this.modalRefService.unregister(this); |
||||
|
this.toggle(false); |
||||
|
} |
||||
|
|
||||
|
close() { |
||||
|
if (this.busy()) return; |
||||
|
|
||||
|
if (this.isFormDirty && !this.suppressUnsavedChangesWarning()) { |
||||
|
if (this.isConfirmationOpen) return; |
||||
|
|
||||
|
this.isConfirmationOpen = true; |
||||
|
this.confirmationService |
||||
|
.warn( |
||||
|
"AbpUi::AreYouSureYouWantToCancelEditingWarningMessage", |
||||
|
"AbpUi::AreYouSure", |
||||
|
{ |
||||
|
dismissible: false, |
||||
|
} |
||||
|
) |
||||
|
.subscribe((status: Confirmation.Status) => { |
||||
|
this.isConfirmationOpen = false; |
||||
|
if (status === Confirmation.Status.confirm) { |
||||
|
this.visible.set(false); |
||||
|
} |
||||
|
}); |
||||
|
} else { |
||||
|
this.visible.set(false); |
||||
|
} |
||||
|
} |
||||
|
|
||||
|
listen() { |
||||
|
if (this.modalWindowRef) { |
||||
|
fromEvent<KeyboardEvent>(this.modalWindowRef, "keyup") |
||||
|
.pipe( |
||||
|
takeUntilDestroyed(this.destroyRef), |
||||
|
debounceTime(150), |
||||
|
filter( |
||||
|
(key: KeyboardEvent) => |
||||
|
key && key.key === "Escape" && this.options().keyboard |
||||
|
) |
||||
|
) |
||||
|
.subscribe(() => this.close()); |
||||
|
} |
||||
|
|
||||
|
fromEvent(window, "beforeunload") |
||||
|
.pipe(takeUntilDestroyed(this.destroyRef)) |
||||
|
.subscribe((event) => { |
||||
|
if (this.isFormDirty && !this.suppressUnsavedChangesWarning()) { |
||||
|
event.preventDefault(); |
||||
|
} |
||||
|
}); |
||||
|
|
||||
|
this.init.emit(); |
||||
|
} |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
This concept differs slightly from the others mentioned above since these components are introduced within a library called `theme-shared`, which you can explore [here](https://github.com/abpframework/abp/tree/dev/npm/ng-packs/packages/theme-shared). |
||||
|
|
||||
|
Using **shared libraries** for such common components is one of the most effective ways to make your app modular and maintainable. By grouping frequently used elements into a dedicated library, you create a single source of truth for your UI and logic. |
||||
|
|
||||
|
However, over-creating or prematurely abstracting small pieces of logic into separate libraries can lead to unnecessary complexity and dependency management overhead. When every feature has its own “mini-library,” updates and debugging become scattered and difficult to coordinate. |
||||
|
|
||||
|
The key is to extract shared functionality only when it is proven to be reused across multiple contexts. Start small, let patterns emerge naturally, and then move them into a shared library when the benefits of reusability outweigh the maintenance cost. |
||||
|
|
||||
|
--- |
||||
|
|
||||
|
## ⚙️ Best Practices and Common Pitfalls |
||||
|
|
||||
|
### ✅ Best Practices |
||||
|
|
||||
|
1. **Start with real reuse:** Extract components only after the pattern appears in multiple places. |
||||
|
2. **Keep them focused:** One clear responsibility per component—avoid “do-it-all” designs. |
||||
|
3. **Use standalone components:** Simplify imports and improve independence. |
||||
|
4. **Promote through libraries:** Move proven, stable components into shared libraries for wider use. |
||||
|
|
||||
|
### ⚠️ Common Mistakes |
||||
|
|
||||
|
1. **Premature abstraction:** Don't create components before actual reuse. |
||||
|
2. **Too many input/output bindings:** Overly generic components are hard to configure and maintain. |
||||
|
3. **Neglecting performance:** Too many micro-components can hurt performance. |
||||
|
4. **Ignoring accessibility and semantics:** Reusable does not mean usable—always consider ARIA roles and HTML structure. |
||||
|
|
||||
|
--- |
||||
|
|
||||
|
## 📚 Further Reading and References |
||||
|
|
||||
|
As this article has mentioned some concepts and best practices, you can explore these resources for more details: |
||||
|
|
||||
|
- [Angular Components Guide](https://angular.dev/guide/components) |
||||
|
- [Standalone Migration Guides](https://angular.dev/reference/migrations/standalone), [ABP Angular Standalone Applications](https://abp.io/community/articles/abp-now-supports-angular-standalone-applications-zzi2rr2z#gsc.tab=0) |
||||
|
- [Smart vs. Dumb Components](https://blog.angular-university.io/angular-2-smart-components-vs-presentation-components-whats-the-difference-when-to-use-each-and-why/) |
||||
|
- [Angular Libraries Overview](https://angular.dev/tools/libraries) |
||||
|
|
||||
|
You can also check these open-source libraries for a better understanding of reusability and modularity: |
||||
|
|
||||
|
- [Angular Components on GitHub](https://github.com/angular/components) |
||||
|
- [ABP NPM Libraries](https://github.com/abpframework/abp/tree/dev/npm/ng-packs/packages) |
||||
|
|
||||
|
--- |
||||
|
|
||||
|
## 🏁 Conclusion |
||||
|
|
||||
|
Reusability is one of the strongest architectural foundations for scalable Angular applications. By combining **standalone components**, **signals**, **encapsulated logic**, and **shared libraries**, you can create a modular system that grows gracefully over time. |
||||
|
|
||||
|
The goal is not just to make components reusable. It is to make them meaningful, maintainable, and consistent across your app. Build only what truly adds value, reuse intentionally, and let Angular's evolving ecosystem handle the rest. |
||||
@ -0,0 +1,289 @@ |
|||||
|
# How to Change Logo in Angular ABP Applications |
||||
|
|
||||
|
## Introduction |
||||
|
|
||||
|
Logo application customization is one of the most common branding requirements in web applications. In ABP Framework's Angular applications, we found that developers were facing problems while they were trying to implement their application logos, especially on theme dependencies and flexibility. To overcome this, we moved the logo provider from `@volo/ngx-lepton-x.core` to `@abp/ng.theme.shared`, where it is more theme-independent and accessible. Here, we will describe our experience using this improvement and guide you on the new approach for logo configuration in ABP Angular applications. |
||||
|
|
||||
|
## Problem |
||||
|
|
||||
|
Previously, the logo configuration process in ABP Angular applications had several disadvantages: |
||||
|
|
||||
|
1. **Theme Dependency**: The `provideLogo` function was a part of the `@volo/ngx-lepton-x.core` package, so the developers had to depend on LeptonX theme packages even when they were using a different theme or wanted to extend the logo behavior. |
||||
|
|
||||
|
2. **Inflexibility**: The fact that the logo provider had to adhere to a specific theme package brought about an undesirable tight coupling of logo configuration and theme implementation. |
||||
|
|
||||
|
3. **Discoverability Issues**: Developers looking for logo configuration features would likely look in core ABP packages, but the provider was hidden in a theme-specific package, which made it harder to discover. |
||||
|
|
||||
|
4. **Migration Issues**: During theme changes or theme package updates, logo setting could get corrupted or require additional tuning. |
||||
|
|
||||
|
These made a basic operation like altering the application logo more challenging than it should be, especially for teams using custom themes or wanting to maintain theme independence. |
||||
|
|
||||
|
## Solution |
||||
|
|
||||
|
We moved the `provideLogo` function from `@volo/ngx-lepton-x.core` to `@abp/ng.theme.shared` package. This solution offers: |
||||
|
|
||||
|
- **Theme Independence**: Works with any ABP-compatible theme |
||||
|
- **Single Source of Truth**: Logo configuration is centralized in the environment file |
||||
|
- **Standard Approach**: Follows ABP's provider-based configuration pattern |
||||
|
- **Easy Migration**: Simple import path change for existing applications |
||||
|
- **Better Discoverability**: Located in a core ABP package where developers expect it |
||||
|
|
||||
|
This approach maintains ABP's philosophy of providing flexible, reusable solutions while reducing unnecessary dependencies. |
||||
|
|
||||
|
## Implementation |
||||
|
|
||||
|
Let's walk through how logo configuration works with the new approach. |
||||
|
|
||||
|
### Step 1: Configure Logo URL in Environment |
||||
|
|
||||
|
First, define your logo URL in the `environment.ts` file: |
||||
|
|
||||
|
```typescript |
||||
|
export const environment = { |
||||
|
production: false, |
||||
|
application: { |
||||
|
baseUrl: 'http://localhost:4200', |
||||
|
name: 'MyApplication', |
||||
|
logoUrl: 'https://your-domain.com/assets/logo.png', |
||||
|
}, |
||||
|
// ... other configurations |
||||
|
}; |
||||
|
``` |
||||
|
|
||||
|
The `logoUrl` property accepts any valid URL, allowing you to use: |
||||
|
- Absolute URLs (external images) |
||||
|
- Relative paths to assets folder (`/assets/logo.png`) |
||||
|
- Data URLs for embedded images |
||||
|
- CDN-hosted images |
||||
|
|
||||
|
### Step 2: Provide Logo Configuration |
||||
|
|
||||
|
In your `app.config.ts` (or `app.module.ts` for module-based apps), import and use the logo provider: |
||||
|
|
||||
|
```typescript |
||||
|
import { provideLogo, withEnvironmentOptions } from '@abp/ng.theme.shared'; |
||||
|
import { environment } from './environments/environment'; |
||||
|
|
||||
|
export const appConfig: ApplicationConfig = { |
||||
|
providers: [ |
||||
|
// ... other providers |
||||
|
provideLogo(withEnvironmentOptions(environment)), |
||||
|
], |
||||
|
}; |
||||
|
``` |
||||
|
|
||||
|
**Important Note**: If you're migrating from an older version where the logo provider was in `@volo/ngx-lepton-x.core`, simply update the import statement: |
||||
|
|
||||
|
```typescript |
||||
|
// Old (before migration) |
||||
|
import { provideLogo, withEnvironmentOptions } from '@volo/ngx-lepton-x.core'; |
||||
|
|
||||
|
// New (current approach) |
||||
|
import { provideLogo, withEnvironmentOptions } from '@abp/ng.theme.shared'; |
||||
|
``` |
||||
|
|
||||
|
### How It Works Under the Hood |
||||
|
|
||||
|
The `provideLogo` function registers a logo configuration service that: |
||||
|
1. Reads the `logoUrl` from environment configuration |
||||
|
2. Provides it to theme components through Angular's dependency injection |
||||
|
3. Allows themes to access and render the logo consistently |
||||
|
|
||||
|
The `withEnvironmentOptions` helper extracts the relevant configuration from your environment object, ensuring type safety and proper configuration structure. |
||||
|
|
||||
|
### Example: Complete Configuration |
||||
|
|
||||
|
Here's a complete example showing both environment and provider configuration: |
||||
|
|
||||
|
**environment.ts:** |
||||
|
```typescript |
||||
|
export const environment = { |
||||
|
production: false, |
||||
|
application: { |
||||
|
baseUrl: 'http://localhost:4200', |
||||
|
name: 'E-Commerce Platform', |
||||
|
logoUrl: 'https://cdn.example.com/brand/logo-primary.svg', |
||||
|
}, |
||||
|
oAuthConfig: { |
||||
|
issuer: 'https://localhost:44305', |
||||
|
clientId: 'MyApp_App', |
||||
|
// ... other OAuth settings |
||||
|
}, |
||||
|
// ... other settings |
||||
|
}; |
||||
|
``` |
||||
|
|
||||
|
**app.config.ts:** |
||||
|
```typescript |
||||
|
import { ApplicationConfig } from '@angular/core'; |
||||
|
import { provideRouter } from '@angular/router'; |
||||
|
import { provideLogo, withEnvironmentOptions } from '@abp/ng.theme.shared'; |
||||
|
import { environment } from './environments/environment'; |
||||
|
import { routes } from './app.routes'; |
||||
|
|
||||
|
export const appConfig: ApplicationConfig = { |
||||
|
providers: [ |
||||
|
provideRouter(routes), |
||||
|
provideLogo(withEnvironmentOptions(environment)), |
||||
|
// ... other providers |
||||
|
], |
||||
|
}; |
||||
|
``` |
||||
|
|
||||
|
## Advanced: Logo Component Replacement |
||||
|
|
||||
|
For more advanced customization scenarios where you need complete control over the logo component's structure, styling, or behavior, ABP provides a component replacement mechanism. This approach allows you to replace the entire logo component with your custom implementation. |
||||
|
|
||||
|
### When to Use Component Replacement |
||||
|
|
||||
|
Consider using component replacement when: |
||||
|
- You need custom HTML structure around the logo |
||||
|
- You want to add interactive elements (e.g., dropdown menu, animations) |
||||
|
- You need to implement complex responsive behavior |
||||
|
- The simple `logoUrl` configuration doesn't meet your requirements |
||||
|
|
||||
|
### How to Replace the Logo Component |
||||
|
|
||||
|
#### Step 1: Generate a New Logo Component |
||||
|
|
||||
|
Run the following command in your Angular folder to create a new component: |
||||
|
|
||||
|
```bash |
||||
|
ng generate component custom-logo --inline-template --inline-style |
||||
|
``` |
||||
|
|
||||
|
#### Step 2: Implement Your Custom Logo |
||||
|
|
||||
|
Open the generated `custom-logo.component.ts` and implement your custom logo: |
||||
|
|
||||
|
```typescript |
||||
|
import { Component } from '@angular/core'; |
||||
|
import { RouterModule } from '@angular/router'; |
||||
|
|
||||
|
@Component({ |
||||
|
selector: 'app-custom-logo', |
||||
|
standalone: true, |
||||
|
imports: [RouterModule], |
||||
|
template: ` |
||||
|
<a class="navbar-brand" routerLink="/"> |
||||
|
<img |
||||
|
src="https://via.placeholder.com/120x40/343a40/00D1B2?text=MyBrand" |
||||
|
alt="My Application Logo" |
||||
|
width="120" |
||||
|
height="40" |
||||
|
/> |
||||
|
</a> |
||||
|
`, |
||||
|
styles: [` |
||||
|
.navbar-brand { |
||||
|
padding: 0.5rem 1rem; |
||||
|
} |
||||
|
|
||||
|
.navbar-brand img { |
||||
|
transition: opacity 0.3s ease; |
||||
|
} |
||||
|
|
||||
|
.navbar-brand:hover img { |
||||
|
opacity: 0.8; |
||||
|
} |
||||
|
`] |
||||
|
}) |
||||
|
export class CustomLogoComponent {} |
||||
|
``` |
||||
|
|
||||
|
#### Step 3: Register the Component Replacement |
||||
|
|
||||
|
Open your `app.config.ts` and register the component replacement: |
||||
|
|
||||
|
```typescript |
||||
|
import { ApplicationConfig } from '@angular/core'; |
||||
|
import { provideRouter } from '@angular/router'; |
||||
|
import { ReplaceableComponentsService } from '@abp/ng.core'; |
||||
|
import { eThemeBasicComponents } from '@abp/ng.theme.basic'; |
||||
|
import { CustomLogoComponent } from './custom-logo/custom-logo.component'; |
||||
|
import { environment } from './environments/environment'; |
||||
|
import { routes } from './app.routes'; |
||||
|
|
||||
|
export const appConfig: ApplicationConfig = { |
||||
|
providers: [ |
||||
|
provideRouter(routes), |
||||
|
// ... other providers |
||||
|
{ |
||||
|
provide: 'APP_INITIALIZER', |
||||
|
useFactory: (replaceableComponents: ReplaceableComponentsService) => { |
||||
|
return () => { |
||||
|
replaceableComponents.add({ |
||||
|
component: CustomLogoComponent, |
||||
|
key: eThemeBasicComponents.Logo, |
||||
|
}); |
||||
|
}; |
||||
|
}, |
||||
|
deps: [ReplaceableComponentsService], |
||||
|
multi: true, |
||||
|
}, |
||||
|
], |
||||
|
}; |
||||
|
``` |
||||
|
|
||||
|
Alternatively, if you're using a module-based application, you can register it in `app.component.ts`: |
||||
|
|
||||
|
```typescript |
||||
|
import { Component, OnInit } from '@angular/core'; |
||||
|
import { ReplaceableComponentsService } from '@abp/ng.core'; |
||||
|
import { eThemeBasicComponents } from '@abp/ng.theme.basic'; |
||||
|
import { CustomLogoComponent } from './custom-logo/custom-logo.component'; |
||||
|
|
||||
|
@Component({ |
||||
|
selector: 'app-root', |
||||
|
template: '<router-outlet></router-outlet>', |
||||
|
}) |
||||
|
export class AppComponent implements OnInit { |
||||
|
constructor(private replaceableComponents: ReplaceableComponentsService) {} |
||||
|
|
||||
|
ngOnInit() { |
||||
|
this.replaceableComponents.add({ |
||||
|
component: CustomLogoComponent, |
||||
|
key: eThemeBasicComponents.Logo, |
||||
|
}); |
||||
|
} |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
### Component Replacement vs Logo URL Configuration |
||||
|
|
||||
|
Here's a comparison to help you choose the right approach: |
||||
|
|
||||
|
| Feature | Logo URL Configuration | Component Replacement | |
||||
|
|---------|------------------------|----------------------| |
||||
|
| **Simplicity** | Very simple, one-line configuration | Requires creating a new component | |
||||
|
| **Flexibility** | Limited to image URL | Full control over HTML/CSS/behavior | |
||||
|
| **Use Case** | Standard logo display | Complex customizations | |
||||
|
| **Maintenance** | Minimal | Requires component maintenance | |
||||
|
| **Migration** | Easy to change | Requires code changes | |
||||
|
| **Recommended For** | Most applications | Advanced customization needs | |
||||
|
|
||||
|
For most applications, the simple `logoUrl` configuration in the environment file is sufficient and recommended. Use component replacement only when you need advanced customization that goes beyond a simple image. |
||||
|
|
||||
|
### Benefits of This Approach |
||||
|
|
||||
|
1. **Separation of Concerns**: Logo configuration is separate from theme implementation |
||||
|
2. **Environment-Based**: Different logos for development, staging, and production |
||||
|
3. **Type Safety**: TypeScript ensures correct configuration structure |
||||
|
4. **Testing**: Easy to mock and test logo configuration |
||||
|
5. **Consistency**: Same logo appears across all theme components automatically |
||||
|
6. **Flexibility**: Choose between simple configuration or full component replacement based on your needs |
||||
|
|
||||
|
## Conclusion |
||||
|
|
||||
|
In this article, we explored how ABP Framework simplified logo configuration in Angular applications by moving the logo provider from `@volo/ngx-lepton-x.core` to `@abp/ng.theme.shared`. This change eliminates unnecessary theme dependencies and makes logo customization more straightforward and theme-agnostic. |
||||
|
|
||||
|
The solution we implemented allows developers to configure their application logo simply by setting a URL in the environment file and providing the logo configuration in their application setup. For advanced scenarios requiring complete control over the logo component, ABP's component replacement mechanism provides a powerful alternative. This approach maintains flexibility while reducing complexity and improving discoverability. |
||||
|
|
||||
|
We developed this improvement while working on ABP Framework to enhance developer experience and reduce common friction points. By sharing this solution, we hope to help teams implement consistent branding across their ABP Angular applications more easily, regardless of which theme they choose to use. |
||||
|
|
||||
|
If you're using an older version of ABP with logo configuration in LeptonX packages, migrating to this new approach requires only a simple import path change, making it a smooth upgrade path for existing applications. |
||||
|
|
||||
|
## See Also |
||||
|
|
||||
|
- [Component Replacement Documentation](https://abp.io/docs/latest/framework/ui/angular/component-replacement) |
||||
|
- [ABP Angular UI Customization Guide](https://abp.io/docs/latest/framework/ui/angular/customization) |
||||
{kind=link}
|
After Width: | Height: | Size: 294 KiB |
@ -0,0 +1,267 @@ |
|||||
|
# From Server to Browser — the Elegant Way: Angular TransferState Explained |
||||
|
|
||||
|
## Introduction |
||||
|
|
||||
|
When building Angular applications with Server‑Side Rendering (SSR), a common performance pitfall is duplicated data fetching: the server loads data to render HTML, then the browser bootstraps Angular and fetches the same data again. That’s wasteful, increases Time‑to‑Interactive, and can hammer your APIs. |
||||
|
|
||||
|
Angular’s built‑in **TransferState** lets you transfer the data fetched on the server to the browser during hydration so the client can reuse it instead of calling the API again. It’s simple, safe for serializable data, and makes SSR feel instant for users. |
||||
|
|
||||
|
This article explains what TransferState is, and how to implement it in your Angular SSR app. |
||||
|
|
||||
|
--- |
||||
|
|
||||
|
## What Is TransferState? |
||||
|
|
||||
|
TransferState is a key–value store that exists for a single SSR render. On the server, you put serializable data into the store. Angular serializes it into the HTML as a small script tag. When the browser hydrates, Angular reads that payload back and makes it available to your app. You can then consume it and skip duplicate HTTP calls. |
||||
|
|
||||
|
Key points: |
||||
|
|
||||
|
- Works only across the SSR → browser hydration boundary (not a general cache). |
||||
|
- Data is cleaned up after bootstrapping (no stale data). |
||||
|
- Stores JSON‑serializable data only (if you need to use Date/Functions/Map; serialize it). |
||||
|
- Data is set on the server and read on the client. |
||||
|
|
||||
|
--- |
||||
|
|
||||
|
## When Should You Use It? |
||||
|
|
||||
|
- Data fetched during SSR that is also be needed on the client. |
||||
|
- Data that doesn’t change between server render and immediate client hydration. |
||||
|
- Expensive or slow API endpoints where a second request is visibly costly. |
||||
|
|
||||
|
Avoid using it for: |
||||
|
|
||||
|
- Highly dynamic data that changes frequently. |
||||
|
- Sensitive data (never put secrets/tokens in TransferState). |
||||
|
- Large payloads (keep the serialized state small to avoid bloating HTML). |
||||
|
|
||||
|
--- |
||||
|
|
||||
|
## Prerequisites |
||||
|
|
||||
|
- An Angular app with SSR enabled (Angular ≥16: `ng add @angular/ssr`). |
||||
|
- `HttpClient` configured. The examples below show both manual TransferState use and the build in solutions. |
||||
|
|
||||
|
--- |
||||
|
|
||||
|
## Option A — Using TransferState Manually |
||||
|
|
||||
|
This approach gives you full control over what to cache and when. It's straightforward and works in both module‑based and standalone‑based apps. |
||||
|
|
||||
|
Service example that fetches books and uses TransferState: |
||||
|
|
||||
|
```ts |
||||
|
// books.service.ts |
||||
|
import { |
||||
|
Injectable, |
||||
|
PLATFORM_ID, |
||||
|
makeStateKey, |
||||
|
TransferState, |
||||
|
inject, |
||||
|
} from '@angular/core'; |
||||
|
import { isPlatformServer } from '@angular/common'; |
||||
|
import { HttpClient } from '@angular/common/http'; |
||||
|
import { Observable, of } from 'rxjs'; |
||||
|
import { tap } from 'rxjs/operators'; |
||||
|
|
||||
|
export interface Book { |
||||
|
id: number; |
||||
|
name: string; |
||||
|
price: number; |
||||
|
} |
||||
|
|
||||
|
@Injectable({ providedIn: 'root' }) |
||||
|
export class BooksService { |
||||
|
BOOKS_KEY = makeStateKey<Book[]>('books:list'); |
||||
|
readonly httpClient = inject(HttpClient); |
||||
|
readonly transferState = inject(TransferState); |
||||
|
readonly platformId = inject(PLATFORM_ID); |
||||
|
|
||||
|
getBooks(): Observable<Book[]> { |
||||
|
// If browser and we have the data that already fetched on the server, use it and remove from TransferState |
||||
|
if (this.transferState.hasKey(this.BOOKS_KEY)) { |
||||
|
const cached = this.transferState.get<Book[]>(this.BOOKS_KEY, []); |
||||
|
this.transferState.remove(this.BOOKS_KEY); // remove to avoid stale reads |
||||
|
return of(cached); |
||||
|
} |
||||
|
|
||||
|
// Otherwise fetch data. If running on the server, write into TransferState |
||||
|
return this.httpClient.get<Book[]>('/api/books').pipe( |
||||
|
tap(list => { |
||||
|
if (isPlatformServer(this.platformId)) { |
||||
|
this.transferState.set(this.BOOKS_KEY, list); |
||||
|
} |
||||
|
}) |
||||
|
); |
||||
|
} |
||||
|
} |
||||
|
|
||||
|
``` |
||||
|
|
||||
|
Use it in a component: |
||||
|
|
||||
|
```ts |
||||
|
// books.component.ts |
||||
|
import { Component, inject, OnInit } from '@angular/core'; |
||||
|
import { CommonModule } from '@angular/common'; |
||||
|
import { BooksService, Book } from './books.service'; |
||||
|
|
||||
|
@Component({ |
||||
|
selector: 'app-books', |
||||
|
imports: [CommonModule], |
||||
|
template: ` |
||||
|
<h1>Books</h1> |
||||
|
<ul> |
||||
|
@for (book of books; track book.id) { |
||||
|
<li>{{ book.name }} — {{ book.price | currency }}</li> |
||||
|
} |
||||
|
</ul> |
||||
|
`, |
||||
|
}) |
||||
|
export class BooksComponent implements OnInit { |
||||
|
private booksService = inject(BooksService); |
||||
|
books: Book[] = []; |
||||
|
|
||||
|
ngOnInit() { |
||||
|
this.booksService.getBooks().subscribe(data => (this.books = data)); |
||||
|
} |
||||
|
} |
||||
|
|
||||
|
``` |
||||
|
|
||||
|
Route resolver variant (keeps templates simple and aligns with SSR prefetching): |
||||
|
|
||||
|
```ts |
||||
|
// src/app/routes.ts |
||||
|
|
||||
|
export const routes: Routes = [ |
||||
|
{ |
||||
|
path: 'books', |
||||
|
component: BooksComponent, |
||||
|
resolve: { |
||||
|
books: () => inject(BooksService).getBooks(), |
||||
|
}, |
||||
|
}, |
||||
|
]; |
||||
|
``` |
||||
|
|
||||
|
Then read `books` from the `ActivatedRoute` data in your component. |
||||
|
|
||||
|
--- |
||||
|
|
||||
|
## Option B — Using HttpInterceptor to Automate TransferState |
||||
|
|
||||
|
Like Option A, but less boilerplate. This approach uses an **HttpInterceptor** to automatically cache HTTP GET (also POST/PUT request but not recommended) responses in TransferState. You can determine which requests to cache based on URL patterns. |
||||
|
|
||||
|
Example interceptor that caches GET requests: |
||||
|
|
||||
|
```ts |
||||
|
import { inject, makeStateKey, PLATFORM_ID, TransferState } from '@angular/core'; |
||||
|
import { |
||||
|
HttpEvent, |
||||
|
HttpHandlerFn, |
||||
|
HttpInterceptorFn, |
||||
|
HttpRequest, |
||||
|
HttpResponse, |
||||
|
} from '@angular/common/http'; |
||||
|
import { Observable, of } from 'rxjs'; |
||||
|
import { isPlatformBrowser, isPlatformServer } from '@angular/common'; |
||||
|
import { tap } from 'rxjs/operators'; |
||||
|
|
||||
|
export const transferStateInterceptor: HttpInterceptorFn = ( |
||||
|
req: HttpRequest<any>, |
||||
|
next: HttpHandlerFn, |
||||
|
): Observable<HttpEvent<any>> => { |
||||
|
const transferState = inject(TransferState); |
||||
|
const platformId = inject(PLATFORM_ID); |
||||
|
|
||||
|
// Only cache GET requests. You can customize this to match specific URLs if needed. |
||||
|
if (req.method !== 'GET') { |
||||
|
return next(req); |
||||
|
} |
||||
|
|
||||
|
// Create a unique key for this request |
||||
|
const stateKey = makeStateKey<HttpResponse<any>>(req.urlWithParams); |
||||
|
|
||||
|
// If browser, check if we have the response in TransferState |
||||
|
if (isPlatformBrowser(platformId)) { |
||||
|
const storedResponse = transferState.get<HttpResponse<any>>(stateKey, null); |
||||
|
if (storedResponse) { |
||||
|
transferState.remove(stateKey); // remove to avoid stale reads |
||||
|
return of(new HttpResponse<any>({ body: storedResponse, status: 200 })); |
||||
|
} |
||||
|
} |
||||
|
|
||||
|
return next(req).pipe( |
||||
|
tap(event => { |
||||
|
// If server, store the response in TransferState |
||||
|
if (isPlatformServer(platformId) && event instanceof HttpResponse) { |
||||
|
transferState.set(stateKey, event.body); |
||||
|
} |
||||
|
}), |
||||
|
); |
||||
|
}; |
||||
|
|
||||
|
``` |
||||
|
|
||||
|
Add the interceptor to your app module or bootstrap function: |
||||
|
|
||||
|
````ts |
||||
|
provideHttpClient(withFetch(), withInterceptors([transferStateInterceptor])) |
||||
|
```` |
||||
|
|
||||
|
|
||||
|
--- |
||||
|
|
||||
|
## Option C — Using Angular's Built-in HTTP Transfer Cache |
||||
|
|
||||
|
This is the simplest option if you want to HTTP requests that without custom logic. |
||||
|
|
||||
|
Angular docs: https://angular.dev/api/platform-browser/withHttpTransferCacheOptions |
||||
|
|
||||
|
|
||||
|
Usage examples: |
||||
|
|
||||
|
```ts |
||||
|
// Only cache GET requests that have no headers |
||||
|
provideClientHydration(withHttpTransferCacheOptions({})) |
||||
|
|
||||
|
// Also cache POST requests (not recommended for most cases) |
||||
|
provideClientHydration(withHttpTransferCacheOptions({ |
||||
|
includePostRequests: true |
||||
|
})) |
||||
|
|
||||
|
// Cache requests that have auth headers (e.g., JWT tokens) |
||||
|
provideClientHydration(withHttpTransferCacheOptions({ |
||||
|
includeRequestsWithAuthHeaders: true |
||||
|
})) |
||||
|
``` |
||||
|
|
||||
|
To see all options, check the Angular docs: https://angular.dev/api/common/http/HttpTransferCacheOptions |
||||
|
|
||||
|
## Best Practices and Pitfalls |
||||
|
|
||||
|
- Keep payloads small: only put what’s needed for initial paint. |
||||
|
- Serialize explicitly if needed: for Dates or complex types, convert to strings and reconstruct on the client. |
||||
|
- Don’t transfer secrets: never place tokens or sensitive user data in TransferState. |
||||
|
- Per‑request isolation: state is scoped to a single SSR request; it is not a global cache. |
||||
|
|
||||
|
--- |
||||
|
|
||||
|
## Debugging Tips |
||||
|
|
||||
|
- Log on server vs browser: use `isPlatformServer` and `isPlatformBrowser` checks to confirm where code runs. |
||||
|
- DevTools inspection: view the page source after SSR; you’ll see a small script tag that embeds the transfer state. |
||||
|
- Count requests: put a console log in your service to verify the second HTTP call is gone on the client. |
||||
|
|
||||
|
--- |
||||
|
|
||||
|
## Measurable Impact |
||||
|
|
||||
|
On content‑heavy pages, TransferState typically removes 1–3 duplicate API calls during hydration, shaving 100–500 ms from the critical path on average networks. It’s a low‑effort, high‑impact win for SSR apps. |
||||
|
|
||||
|
--- |
||||
|
|
||||
|
## Conclusion |
||||
|
|
||||
|
If you already have SSR, enabling TransferState is one of the easiest ways to make hydration feel instant. You can use it built‑in HTTP caching or manually control what to cache. Either way, it eliminates redundant data fetching, speeds up Time‑to‑Interactive, and improves user experience with minimal effort. |
||||
@ -0,0 +1,244 @@ |
|||||
|
# Angular Library Linking Made Easy: Paths, Workspaces, and Symlinks |
||||
|
|
||||
|
Managing local libraries and path references in Angular projects has evolved significantly with the introduction of the new Angular application builder. What once required manual path mappings, fragile symlinks, and `node_modules` references is now more structured, predictable, and aligned with modern TypeScript and workspace practices. This guide walks through how path mapping works, how it has changed, and the best ways to link and manage your local libraries in brand new Angular ecosystem. |
||||
|
|
||||
|
### Understanding TypeScript Path Mapping |
||||
|
|
||||
|
Path aliases is a powerful feature in TypeScript that helps developers simplify and organize their import statements. Instead of dealing with long and error-prone relative paths like `../../../components/button`, you can define a clear and descriptive alias that points directly to a specific directory or module. |
||||
|
|
||||
|
This configuration is managed through the `paths` property in the TypeScript configuration file (`tsconfig.json`), allowing you to map custom names to local folders or compiled outputs. For example: |
||||
|
|
||||
|
```json |
||||
|
// tsconfig.json |
||||
|
{ |
||||
|
"compilerOptions": { |
||||
|
"paths": { |
||||
|
"@my-package": ["./dist/my-package"], |
||||
|
"@my-second-package": ["./projects/my-second-package/src/public-api.ts"] |
||||
|
} |
||||
|
} |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
In this setup, `@my-package` serves as a shorthand reference to your locally built library. Once configured, you can import modules using `@my-package` instead of long relative paths, which greatly improves readability and maintainability across large projects. |
||||
|
|
||||
|
When working with multiple subdirectories or a more complex folder structure, you can also use wildcards to create flexible and dynamic mappings. This pattern is especially useful for modular libraries or mono-repos that contain multiple sub-packages: |
||||
|
|
||||
|
```json |
||||
|
// tsconfig.json |
||||
|
{ |
||||
|
"compilerOptions": { |
||||
|
"paths": { |
||||
|
"@my-package/*": ["./dist/my-package/*"] |
||||
|
} |
||||
|
} |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
With this approach, imports like `@my-package/utils` or `@my-package/components/button` will automatically resolve to the corresponding directories in your build output. This makes your codebase more maintainable, portable, and consistent. This is useful especially when collaborating across teams or working with multiple libraries in the same workspace. |
||||
|
|
||||
|
--- |
||||
|
|
||||
|
### Step-by-Step Examples of Path Configuration |
||||
|
|
||||
|
As this example provides a glimpse for the path mapping, this is not the only way for the aliases. Here are the other ways to utilize this feature. |
||||
|
|
||||
|
1. **Using `package.json` Exports for Library Mapping** |
||||
|
|
||||
|
When developing internal libraries within a mono-repo, another option is to use the `exports` field in each library’s `package.json` |
||||
|
|
||||
|
This allows Node and modern bundlers to resolve imports cleanly when consuming the library, without depending solely on TypeScript configuration. |
||||
|
|
||||
|
```json |
||||
|
// dist/my-lib/package.json |
||||
|
{ |
||||
|
"name": "@my-org/my-lib", |
||||
|
"version": "1.0.0", |
||||
|
"exports": { |
||||
|
".": "./index.js", |
||||
|
"./utils": "./utils/index.ts" |
||||
|
} |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
```tsx |
||||
|
import { formatDate } from "@my-org/my-lib/utils"; |
||||
|
``` |
||||
|
|
||||
|
This approach becomes especially powerful when publishing your libraries or integrating them into larger Angular mono-repos. Because, it aligns both runtime (Node) and compile-time (TypeScript) resolution. |
||||
|
|
||||
|
2. **Linking Local Libraries via Symlinks** |
||||
|
|
||||
|
If you want to use a local library that is not yet published to npm, you can create a symbolic link between your library’s `dist` output and your consuming app. |
||||
|
|
||||
|
This is useful when testing or developing multiple packages in parallel. |
||||
|
|
||||
|
You can create a symlink using npm or yarn: |
||||
|
|
||||
|
```bash |
||||
|
# Inside your library folder |
||||
|
npm link |
||||
|
|
||||
|
# Inside your consuming app |
||||
|
npm link @my-org/my-lib |
||||
|
``` |
||||
|
|
||||
|
This effectively tells Node to resolve `@my-org/my-lib` from your local file system instead of the npm registry. |
||||
|
|
||||
|
However, note that symlinks can sometimes lead to path resolution issues with certain Angular build configurations, especially before the new application builder. With the latest builder improvements, this approach is becoming more stable and predictable. |
||||
|
|
||||
|
3. **Combining Path Mapping with Workspace Configuration** |
||||
|
|
||||
|
In a structured Angular workspace, especially one created with **Nx** or **Angular CLI** using multiple projects, you can combine the approaches above. |
||||
|
|
||||
|
For instance, your `tsconfig.base.json` can define local references for in-repo libraries, while each library’s `package.json` provides external mappings for reuse outside the workspace. |
||||
|
|
||||
|
This hybrid setup ensures that: |
||||
|
|
||||
|
- The workspace remains easy to navigate and refactor locally. |
||||
|
- External consumers (or CI builds) can still resolve imports correctly once libraries are built. |
||||
|
|
||||
|
For larger Angular projects or mono-repos, **Workspaces** (supported by both **Yarn** and **npm**) offer a clean way to manage multiple local packages within the same repository. Workspaces automatically link internal libraries together, so you can reference them by name instead of using manual `file:` paths or complex TypeScript aliases. This approach keeps dependencies consistent, simplifies cross-project development, and scales well for enterprise or multi-package setups. |
||||
|
|
||||
|
Each of these methods has its strengths: |
||||
|
|
||||
|
- **TypeScript paths:** This is great for local development and quick imports. |
||||
|
- **`package.json` exports:** This is ideal for libraries meant to be distributed. |
||||
|
- **Symlinks:** These are convenient for local testing between projects. |
||||
|
|
||||
|
Choosing the right one, or even combining them depends on the scale of your project and whether you are building internal libraries, or a full mono-repo setup. |
||||
|
|
||||
|
--- |
||||
|
|
||||
|
### How Path References Worked Before the New Angular Application Builder |
||||
|
|
||||
|
Angular used to support path aliases to the locally installed packages by referencing to the `node_modules` folder like this: |
||||
|
|
||||
|
```json |
||||
|
// tsconfig.json |
||||
|
{ |
||||
|
"compilerOptions": { |
||||
|
"paths": { |
||||
|
"@angular/*": ["./node_modules/@angular/*"] |
||||
|
} |
||||
|
} |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
However, this approach is not recommended, hence not supported, by the TypeScript. You can find detailed guidance on this topic in the TypeScript documentation, which notes that paths should not reference mono-repo packages or those inside **node_modules**: [Paths should not point to monorepo packages or node_modules packages](https://www.typescriptlang.org/docs/handbook/modules/reference.html#paths-should-not-point-to-monorepo-packages-or-node_modules-packages). |
||||
|
|
||||
|
Giving a real life example would explain the situation better. Suppose that you have such structure: |
||||
|
|
||||
|
- Amain angular app that consumes several npm dependencies and holds registered local paths that reference to another library locally like this: |
||||
|
|
||||
|
```json |
||||
|
// angular/tsconfig.json |
||||
|
{ |
||||
|
"compileOnSave": false, |
||||
|
"compilerOptions": { |
||||
|
"paths": { |
||||
|
"@abp/ng.identity": [ |
||||
|
"../modules/Volo.Abp.Identity/angular/projects/identity/src/public-api.ts" |
||||
|
], |
||||
|
"@abp/ng.identity/config": [ |
||||
|
"../modules/Volo.Abp.Identity/angular/projects/identity/config/src/public-api.ts" |
||||
|
], |
||||
|
"@abp/ng.identity/proxy": [ |
||||
|
"../modules/Volo.Abp.Identity/angular/projects/identity/proxy/src/public-api.ts" |
||||
|
] |
||||
|
} |
||||
|
} |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
This simply references to this package physically https://github.com/abpframework/abp/tree/dev/npm/ng-packs/packages/identity |
||||
|
|
||||
|
- This library is also using these dependencies |
||||
|
|
||||
|
```json |
||||
|
// npm/ng-packs/packages/identity/package.json |
||||
|
{ |
||||
|
"name": "@abp/ng.identity", |
||||
|
"version": "10.0.0-rc.1", |
||||
|
"homepage": "https://abp.io", |
||||
|
"repository": { |
||||
|
"type": "git", |
||||
|
"url": "https://github.com/abpframework/abp.git" |
||||
|
}, |
||||
|
"dependencies": { |
||||
|
"@abp/ng.components": "~10.0.0-rc.1", |
||||
|
"@abp/ng.permission-management": "~10.0.0-rc.1", |
||||
|
"@abp/ng.theme.shared": "~10.0.0-rc.1", |
||||
|
"tslib": "^2.0.0" |
||||
|
}, |
||||
|
"publishConfig": { |
||||
|
"access": "public" |
||||
|
} |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
As these libraries also have their own dependencies, the identity package needs to consume them in itself. Before the [application builder migration](https://angular.dev/tools/cli/build-system-migration), you could register the path configuration like this |
||||
|
|
||||
|
```json |
||||
|
// angular/tsconfig.json |
||||
|
{ |
||||
|
"compileOnSave": false, |
||||
|
"compilerOptions": { |
||||
|
"paths": { |
||||
|
"@angular/*": ["node_modules/@angular/*"], |
||||
|
"@abp/*": ["node_modules/@abp/*"], |
||||
|
"@swimlane/*": ["node_modules/@swimlane/*"], |
||||
|
"@ngx-validate/core": ["node_modules/@ngx-validate/core"], |
||||
|
"@ng-bootstrap/ng-bootstrap": [ |
||||
|
"node_modules/@ng-bootstrap/ng-bootstrap" |
||||
|
], |
||||
|
"@abp/ng.identity": [ |
||||
|
"../modules/Volo.Abp.Identity/angular/projects/identity/src/public-api.ts" |
||||
|
], |
||||
|
"@abp/ng.identity/config": [ |
||||
|
"../modules/Volo.Abp.Identity/angular/projects/identity/config/src/public-api.ts" |
||||
|
], |
||||
|
"@abp/ng.identity/proxy": [ |
||||
|
"../modules/Volo.Abp.Identity/angular/projects/identity/proxy/src/public-api.ts" |
||||
|
] |
||||
|
} |
||||
|
} |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
However, the latest builder forces more strict rules. So, it does not resolve the paths that reference to the `node_modules` causing a common DI error as mentioned here: |
||||
|
|
||||
|
- https://github.com/angular/angular-cli/issues/31395 |
||||
|
- https://github.com/angular/angular-cli/issues/26901 |
||||
|
- https://github.com/angular/angular-cli/issues/27176 |
||||
|
|
||||
|
In this case, we recommend using a symlink script. You can reach them through this example application: [🔗 Angular Sample Path Reference](https://github.com/sumeyyeKurtulus/AbpPathReferenceExamples) |
||||
|
|
||||
|
These scripts help you share dependencies from the main Angular app to local library projects via symlinks: |
||||
|
|
||||
|
- `symlink-config.ps1` centralizes which library directories to touch (e.g., ../../modules/Volo.Abp.Identity/angular/projects/identity) and which packages to link (e.g., @angular, @abp, rxjs) |
||||
|
- `setup-symlinks.ps1` reads that config and, for each library, creates a `node_modules` folder if needed and symlinks only the listed packages from the `node_modules` of the app to avoid duplicate installs |
||||
|
- `remove-symlinks.ps1` cleans up by deleting those library `node_modules` directories so they can use their own local deps again |
||||
|
- In `angular/package.json`, the `symlinks:setup` and `symlinks:remove` npm scripts simply run those two PowerShell scripts so you can execute them conveniently with your package manager. |
||||
|
|
||||
|
--- |
||||
|
|
||||
|
### Best Practices and Recommendations |
||||
|
|
||||
|
As we have explained each way of path mapping, this part of the article aims to summarize the best practices. Here are the points you need to consider: |
||||
|
|
||||
|
- Prefer **workspace references** for large projects and mono-repos. |
||||
|
- Use **TypeScript path aliases** only for local development convenience. |
||||
|
- Strictly avoid referencing `node_modules` directly; let the Angular builder manage package resolution. |
||||
|
- Maintain **consistent library structures** with clear `package.json` exports for reusable libraries. |
||||
|
- Automate **symlink creation/removal** if needed to reduce manual errors. |
||||
|
|
||||
|
Here is the list of common pitfalls and how you could troubleshoot them: |
||||
|
|
||||
|
- **DI errors after path configurations for typescript config**: Ensure that only one copy of each library is resolved. Avoid duplicate modules by checking `node_modules` and symlinks. |
||||
|
- **IDE not recognizing aliases**: Confirm that `tsconfig.json` or `tsconfig.base.json` includes the correct `paths` configuration and that your IDE is using the correct tsconfig. |
||||
|
- **Build errors with old paths**: Migrate paths pointing to `node_modules` to either workspace references or local library paths. |
||||
|
- **Symlink issues in CI/CD**: Use automated scripts to create/remove symlinks consistently; do not rely on manual linking. |
||||
|
- **Module resolution conflicts**: Check library dependencies for mismatched versions and align them using a package manager workspace strategy. |
||||
|
|
||||
|
As Angular’s build system continues to mature, developers are encouraged to move away from outdated path configurations and manual symlink setups. By embracing workspace references, consistent library exports, and TypeScript path mapping, teams can build scalable, maintainable applications without wrestling with complex import paths or dependency conflicts. With the right configuration, local development becomes faster, cleaner, and far more reliable. |
||||
@ -0,0 +1,88 @@ |
|||||
|
# 5 Things You Should Keep in Mind When Deploying to a Clustered Environment |
||||
|
|
||||
|
Let’s be honest — moving from a single server to a cluster sounds simple on paper. |
||||
|
You just add a few more machines, right? |
||||
|
In practice, it’s the moment when small architectural mistakes start to grow legs. |
||||
|
Below are a few things that experienced engineers usually double-check before pressing that “Deploy” button. |
||||
|
|
||||
|
--- |
||||
|
|
||||
|
## 1️⃣ Managing State the Right Way |
||||
|
|
||||
|
Each request in a cluster might hit a different machine. |
||||
|
If your application keeps user sessions or cache in memory, that data probably won’t exist on the next node. |
||||
|
That’s why many teams decide to push state out of the app itself. |
||||
|
|
||||
|
 |
||||
|
|
||||
|
**A few real-world tips:** |
||||
|
- Keep sessions in **Redis** or something similar instead of local memory. |
||||
|
- Design endpoints so they don’t rely on earlier requests. |
||||
|
- Don’t assume the same server will handle two requests in a row — it rarely does. |
||||
|
|
||||
|
--- |
||||
|
|
||||
|
## 2️⃣ Shared Files and Where to Put Them |
||||
|
|
||||
|
Uploading files to local disk? That’s going to hurt in a cluster. |
||||
|
Other nodes can’t reach those files, and you’ll spend hours wondering why images disappear. |
||||
|
|
||||
|
 |
||||
|
|
||||
|
**Better habits:** |
||||
|
- Push uploads to **S3**, **Azure Blob**, or **Google Cloud Storage**. |
||||
|
- Send logs to a shared location instead of writing to local files. |
||||
|
- Keep environment configs in a central place so each node starts with the same settings. |
||||
|
|
||||
|
--- |
||||
|
|
||||
|
## 3️⃣ Database Connections Aren’t Free |
||||
|
|
||||
|
Every node opens its own database connections. |
||||
|
Ten nodes with twenty connections each — that’s already two hundred open sessions. |
||||
|
The database might not love that. |
||||
|
|
||||
|
 |
||||
|
|
||||
|
**What helps:** |
||||
|
- Put a cap on your connection pools. |
||||
|
- Avoid keeping transactions open for too long. |
||||
|
- Tune indexes and queries before scaling horizontally. |
||||
|
|
||||
|
--- |
||||
|
|
||||
|
## 4️⃣ Logging and Observability Matter More Than You Think |
||||
|
|
||||
|
When something breaks in a distributed system, it’s never obvious which server was responsible. |
||||
|
That’s why observability isn’t optional anymore. |
||||
|
|
||||
|
 |
||||
|
|
||||
|
**Consider this:** |
||||
|
- Stream logs to **ELK**, **Datadog**, or **Grafana Loki**. |
||||
|
- Add a **trace ID** to every incoming request and propagate it across services. |
||||
|
- Watch key metrics with **Prometheus** and visualize them in Grafana dashboards. |
||||
|
|
||||
|
--- |
||||
|
|
||||
|
## 5️⃣ Background Jobs and Message Queues |
||||
|
|
||||
|
If more than one node runs the same job, you might process the same data twice — or delete something by mistake. |
||||
|
You don’t want that kind of excitement in production. |
||||
|
|
||||
|
 |
||||
|
|
||||
|
**A few precautions:** |
||||
|
- Use a **distributed lock** or **leader election** system. |
||||
|
- Make jobs **idempotent**, so running them twice doesn’t break data. |
||||
|
- Centralize queue consumers or use a proper task scheduler. |
||||
|
|
||||
|
--- |
||||
|
|
||||
|
## Wrapping Up |
||||
|
|
||||
|
Deploying to a cluster isn’t only about scaling up — it’s about staying stable when you do. |
||||
|
Systems that handle state, logging, and background work correctly tend to age gracefully. |
||||
|
Everything else eventually learns the hard way. |
||||
|
|
||||
|
> A cluster doesn’t fix design flaws — it magnifies them. |
||||
{kind=link}
|
After Width: | Height: | Size: 118 KiB |
{kind=link}
|
After Width: | Height: | Size: 68 KiB |
{kind=link}
|
After Width: | Height: | Size: 718 KiB |
{kind=link}
|
After Width: | Height: | Size: 75 KiB |
@ -0,0 +1,27 @@ |
|||||
|
# 5 Things You Should Keep in Mind When Deploying to a Clustered Environment |
||||
|
|
||||
|
Let’s be honest — moving from a single server to a cluster sounds simple on paper. |
||||
|
You just add a few more machines, right? |
||||
|
In practice, it’s the moment when small architectural mistakes start to grow legs. |
||||
|
Below are a few things that experienced engineers usually double-check before pressing that “Deploy” button. |
||||
|
|
||||
|
--- |
||||
|
|
||||
|
## 1️⃣ Managing State the Right Way |
||||
|
--- |
||||
|
|
||||
|
## 2️⃣ Shared Files and Where to Put Them |
||||
|
--- |
||||
|
|
||||
|
## 3️⃣ Database Connections Aren’t Free |
||||
|
--- |
||||
|
|
||||
|
## 4️⃣ Logging and Observability Matter More Than You Think |
||||
|
--- |
||||
|
|
||||
|
## 5️⃣ Background Jobs and Message Queues |
||||
|
--- |
||||
|
|
||||
|
 |
||||
|
|
||||
|
👉 Read the full guide here: [5 Things You Should Keep in Mind When Deploying to a Clustered Environment](https://abp.io/community/articles/) |
||||
{kind=link}
|
After Width: | Height: | Size: 67 KiB |
{kind=link}
|
After Width: | Height: | Size: 87 KiB |
{kind=link}
|
After Width: | Height: | Size: 40 KiB |
{kind=link}
|
After Width: | Height: | Size: 352 KiB |
{kind=link}
|
After Width: | Height: | Size: 206 KiB |
{kind=link}
|
After Width: | Height: | Size: 237 KiB |
{kind=link}
|
After Width: | Height: | Size: 52 KiB |
{kind=link}
|
After Width: | Height: | Size: 354 KiB |
{kind=link}
|
After Width: | Height: | Size: 487 KiB |
{kind=link}
|
After Width: | Height: | Size: 1.2 MiB |
{kind=link}
|
After Width: | Height: | Size: 366 KiB |
{kind=link}
|
After Width: | Height: | Size: 256 KiB |
{kind=link}
|
After Width: | Height: | Size: 191 KiB |
{kind=link}
|
After Width: | Height: | Size: 242 KiB |
{kind=link}
|
After Width: | Height: | Size: 190 KiB |
@ -0,0 +1,251 @@ |
|||||
|
# Optimize Your .NET App for Production (Complete Checklist) |
||||
|
|
||||
|
I see way too many .NET apps go to prod like it’s still “F5 on my laptop.” Here’s the checklist I wish someone shoved me years ago. It’s opinionated, pragmatic, copy-pasteable. |
||||
|
|
||||
|
------ |
||||
|
|
||||
|
## 1) Publish Command and CSPROJ Settings |
||||
|
|
||||
|
 |
||||
|
|
||||
|
Never go to production with debug build! See the below command which publishes properly a .NET app for production. |
||||
|
|
||||
|
```bash |
||||
|
dotnet publish -c Release -o out -p:PublishTrimmed=true -p:PublishSingleFile=true -p:ReadyToRun=true |
||||
|
``` |
||||
|
|
||||
|
`csproj` for the optimum production publish: |
||||
|
|
||||
|
```xml |
||||
|
<PropertyGroup> |
||||
|
<PublishReadyToRun>true</PublishReadyToRun> |
||||
|
<PublishTrimmed>true</PublishTrimmed> |
||||
|
<InvariantGlobalization>true</InvariantGlobalization> |
||||
|
<TieredCompilation>true</TieredCompilation> |
||||
|
</PropertyGroup> |
||||
|
``` |
||||
|
|
||||
|
- **PublishTrimmed** It's trimmimg assemblies. What's that!? It removes unused code from your application and its dependencies, hence it reduces the output files. |
||||
|
|
||||
|
- **PublishReadyToRun** When you normally build a .NET app, your C# code is compiled into **IL** (Intrmediate Language). When your app runs, the JIT Compiler turns that IL code into native CPU commands. But this takes much time on startup. When you enable `PublishReadyToRun`, the build process precompiles your IL into native code and it's called AOT (Ahead Of Time). Hence your app starts faster... But the downside is; the output files are now a bit bigger. Another thing; it'll compile only for a specific OS like Windows and will not run on Linux anymore. |
||||
|
|
||||
|
- **Self-contained** When you publish your .NET app this way, it ncludes the .NET runtime inside your app files. It will run even on a machine that doesn’t have .NET installed. The output size gets larger, but the runtime version is exactly what you built with. |
||||
|
|
||||
|
|
||||
|
|
||||
|
------ |
||||
|
|
||||
|
## 2) Kestrel Hosting |
||||
|
|
||||
|
 |
||||
|
|
||||
|
By default, ASP.NET Core app listen only `localhost`, it means it accepts requests only from inside the machine. When you deploy to Docker or Kubernetes, the container’s internal network needs to expose the app to the outside world. To do this you can set it via environment variable as below: |
||||
|
|
||||
|
```bash |
||||
|
ASPNETCORE_URLS=http://0.0.0.0:8080 |
||||
|
``` |
||||
|
|
||||
|
Also if you’re building an internall API or a containerized microservice which is not multilngual, then add also the below setting. it disables operating system's globalization to reduce image size and dependencies.. |
||||
|
|
||||
|
```bash |
||||
|
DOTNET_SYSTEM_GLOBALIZATION_INVARIANT=1 |
||||
|
``` |
||||
|
|
||||
|
Clean `Program.cs` startup! |
||||
|
Here's a minimal `Program.cs` which includes just the essential middleware and settings: |
||||
|
|
||||
|
```csharp |
||||
|
var builder = WebApplication.CreateBuilder(args); |
||||
|
|
||||
|
builder.Logging.ClearProviders(); |
||||
|
builder.Logging.AddConsole(); |
||||
|
|
||||
|
builder.Services.AddResponseCompression(); |
||||
|
builder.Services.AddResponseCaching(); |
||||
|
builder.Services.AddHealthChecks(); |
||||
|
|
||||
|
var app = builder.Build(); |
||||
|
|
||||
|
if (!app.Environment.IsDevelopment()) |
||||
|
{ |
||||
|
app.UseExceptionHandler("/error"); |
||||
|
app.UseHsts(); |
||||
|
} |
||||
|
|
||||
|
app.UseResponseCompression(); |
||||
|
app.UseResponseCaching(); |
||||
|
|
||||
|
app.MapHealthChecks("/health"); |
||||
|
app.MapGet("/error", () => Results.Problem(statusCode: 500)); |
||||
|
|
||||
|
app.Run(); |
||||
|
``` |
||||
|
|
||||
|
|
||||
|
|
||||
|
------ |
||||
|
|
||||
|
## 3) Garbage Collection and ThreadPool |
||||
|
|
||||
|
|
||||
|
|
||||
|
 |
||||
|
|
||||
|
### GC Memory Cleanup Mode |
||||
|
|
||||
|
GC (Garbage Collection) is how .NET automatically frees memory. There are two main modes: |
||||
|
|
||||
|
- **Workstation GC:** good for desktop apps (focuses on responsiveness) |
||||
|
- **Server GC:** good for servers (focuses on throughput) |
||||
|
|
||||
|
The below environment variable is telling the .NET runtime to use the *Server Garbage Collector (Server GC)* instead of the *Workstation GC*. Because our ASP.NET Core app must be optmized for servers not personal computers. |
||||
|
|
||||
|
```bash |
||||
|
COMPlus_gcServer=1 |
||||
|
``` |
||||
|
|
||||
|
### GC Limit Memory Usage |
||||
|
|
||||
|
Use at max 60% of the total available memory for the managed heap (the memory that .NET’s GC controls). So if your container or VM has, let's say 4 GB of RAM, .NET will try to keep the GC heap below 2.4 GB (60% of 4 GB). Especially when you run your app in containers, don’t let the GC assume host memory: |
||||
|
|
||||
|
```bash |
||||
|
COMPlus_GCHeapHardLimitPercent=60 |
||||
|
``` |
||||
|
|
||||
|
### Thread Pool Warm-up |
||||
|
|
||||
|
When your .NET app runs, it uses a thread pool. This is for handling background work like HTTP requests, async tasks, I/O things... By default, the thread pool starts small and grows dynamically as load increases. That’s good for desktop apps but for server apps it's too slow! Because during sudden peek of traffic, the app might waste time creating threads instead of handling requests. So below code keeps at least 200 worker threads and 200 I/O completion threads ready to go even if they’re idle. |
||||
|
|
||||
|
```csharp |
||||
|
ThreadPool.SetMinThreads(200, 200); |
||||
|
``` |
||||
|
|
||||
|
|
||||
|
|
||||
|
------ |
||||
|
|
||||
|
## 4) HTTP Performance |
||||
|
|
||||
|
 |
||||
|
|
||||
|
### HTTP Response Compression |
||||
|
|
||||
|
`AddResponseCompression()` enables HTTP response compression. It shrinks your outgoing responses before sending them to the client. Making smaller payloads for faster responses and uses less bandwidth. Default compression method is `Gzip`. You can also add `Brotli` compression. `Brotli` is great for APIs returning JSON or text. If your CPU is already busy, keep the default `Gzip` method. |
||||
|
|
||||
|
```csharp |
||||
|
builder.Services.AddResponseCompression(options => |
||||
|
{ |
||||
|
options.Providers.Add<BrotliCompressionProvider>(); |
||||
|
options.EnableForHttps = true; |
||||
|
}); |
||||
|
``` |
||||
|
|
||||
|
|
||||
|
|
||||
|
### HTTP Response Caching |
||||
|
|
||||
|
Use caching for GET endpoints where data doesn’t change often (e.g., configs, reference data). `ETags` and `Last-Modified` headers tell browsers or proxies skip downloading data that hasn’t changed. |
||||
|
|
||||
|
- **ETag** = a version token for your resource. |
||||
|
- **Last-Modified** = timestamp of last change. |
||||
|
|
||||
|
If a client sends `If-None-Match: "abc123"` and your resource’s `ETag` hasn’t changed, .NET automatically returns `304 Not Modified`. |
||||
|
|
||||
|
|
||||
|
|
||||
|
### HTTP/2 or HTTP/3 |
||||
|
|
||||
|
These newer protocols make web requests faster and smoother. It's good for microservices or frontends making many API calls. |
||||
|
|
||||
|
- **HTTP/2** : multiplexing (many requests over one TCP connection). |
||||
|
- **HTTP/3** : uses QUIC (UDP) for even lower latency. |
||||
|
|
||||
|
You can enable them on your reverse proxy (Nginx, Caddy, Kestrel)... |
||||
|
.NET supports both out of the box if your environment allows it. |
||||
|
|
||||
|
|
||||
|
|
||||
|
### Minimal Payloads with DTOs |
||||
|
|
||||
|
The best practise here is; Never send/recieve your entire database entity, use DTOs. In the DTOs include only the fields the client actually needs by doing so you will keep the responses smaller and even safer. Also, prefer `System.Text.Json` (now it’s faster than `Newtonsoft.Json`) and for very high-traffic APIs, use source generation to remove reflection overhead. |
||||
|
|
||||
|
```csharp |
||||
|
//define your entity DTO |
||||
|
[JsonSerializable(typeof(MyDto))] |
||||
|
internal partial class MyJsonContext : JsonSerializerContext { } |
||||
|
|
||||
|
//and simply serialize like this |
||||
|
var json = JsonSerializer.Serialize(dto, MyJsonContext.Default.MyDto) |
||||
|
``` |
||||
|
|
||||
|
------ |
||||
|
|
||||
|
## 5) Data Layer (Mostly Where Most Apps Slow Down!) |
||||
|
|
||||
|
 |
||||
|
|
||||
|
### Reuse `DbContext` via Factory (Pooling) |
||||
|
|
||||
|
Creating a new `DbContext` for every query is expensive! Use `IDbContextFactory<TContext>`, it gives you pooled `DbContext` instances from a pool that reuses objects instead of creating them from scratch. |
||||
|
|
||||
|
```csharp |
||||
|
services.AddDbContextFactory<AppDbContext>(options => |
||||
|
options.UseSqlServer(connectionString)); |
||||
|
``` |
||||
|
|
||||
|
Then inject the factory: |
||||
|
|
||||
|
```csharp |
||||
|
using var db = _contextFactory.CreateDbContext(); |
||||
|
``` |
||||
|
|
||||
|
Also, ensure your database server (SQL Server, PostgreSQL....) has **connection pooling enabled**. |
||||
|
|
||||
|
------ |
||||
|
|
||||
|
### N+1 Query Problem |
||||
|
|
||||
|
The N+1 problem occurs when your app runs **one query for the main data**, then **N more queries for related entities**. That kills performance!!! |
||||
|
|
||||
|
**Bad-Practise:** |
||||
|
|
||||
|
```csharp |
||||
|
var users = await context.Users.Include(u => u.Orders).ToListAsync(); |
||||
|
``` |
||||
|
|
||||
|
**Good-Practise:** |
||||
|
Project to DTOs using `.Select()` so EF-Core generates a single optimized SQL query: |
||||
|
|
||||
|
```csharp |
||||
|
var users = await context.Users.Select(u => new UserDto |
||||
|
{ |
||||
|
Id = u.Id, |
||||
|
Name = u.Name, |
||||
|
OrderCount = u.Orders.Count |
||||
|
}).ToListAsync(); |
||||
|
``` |
||||
|
|
||||
|
------ |
||||
|
|
||||
|
### **Indexes** |
||||
|
|
||||
|
Use EF Core logging, SQL Server Profiler, or `EXPLAIN` (Postgres/MySQL) to find slow queries. Add missing indexes **only** where needed. For example [at this page](https://blog.sqlauthority.com/2011/01/03/sql-server-2008-missing-index-script-download/), he wrote an SQL query which lists missing index list (also there's another version at [Microsoft Docs](https://learn.microsoft.com/en-us/sql/relational-databases/system-dynamic-management-views/sys-dm-db-missing-index-details-transact-sql?view=sql-server-ver17)). This perf improvement is mostly applied after running the app for a period of time. |
||||
|
|
||||
|
|
||||
|
|
||||
|
------ |
||||
|
|
||||
|
### Migrations |
||||
|
|
||||
|
In production run migrations manually, never do it on app startup. That way you can review schema changes, back up data and avoid breaking the live DB. |
||||
|
|
||||
|
|
||||
|
|
||||
|
------ |
||||
|
|
||||
|
### Resilience with Polly |
||||
|
|
||||
|
Use [Polly](https://www.pollydocs.org/) for retries, timeouts and circuit breakers for your DB or HTTP calls. Handles short outages gracefully |
||||
|
|
||||
|
*To keep the article short and for the better readability I spitted it into 2 parts 👉 [Continue with the second part here](https://abp.io/community/articles/optimize-your-dotnet-app-for-production-for-any-.net-app-2-78xgncpi)...* |
||||
|
|
||||
@ -0,0 +1,267 @@ |
|||||
|
*If you’ve landed directly on this article, note that it’s part-2 of the series. You can read part-1 here: [Optimize Your .NET App for Production (Part 1)](https://abp.io/community/articles/optimize-your-dotnet-app-for-production-for-any-.net-app-wa24j28e)* |
||||
|
|
||||
|
## 6) Telemetry (Logs, Metrics, Traces) |
||||
|
|
||||
|
 |
||||
|
|
||||
|
The below code adds `OpenTelemetry` to collect app logs, metrics, and traces in .NET. |
||||
|
|
||||
|
```csharp |
||||
|
builder.Services.AddOpenTelemetry() |
||||
|
.UseOtlpExporter() |
||||
|
.WithMetrics(m => m.AddAspNetCoreInstrumentation().AddHttpClientInstrumentation()) |
||||
|
.WithTracing(t => t.AddAspNetCoreInstrumentation().AddHttpClientInstrumentation()); |
||||
|
``` |
||||
|
|
||||
|
- `UseOtlpExporter()` Tells it where to send telemetry. Usually that’s an OTLP collector (like Grafana , Jaeger, Tempo, Azure Monitor). So you can visualize metrics and traces in dashboards. |
||||
|
- `WithMetrics()` means it'll collects metrics. These metrics are Request rate (RPS), Request duration (latency), GC pauses, Exceptions, HTTP client timings. |
||||
|
- `.WithTracing(...)` means it'll collect distributed traces. That's useful when your app calls other APIs or microservices. You can see the full request path from one service to another with timings and bottlenecks. |
||||
|
|
||||
|
### .NET Diagnostic Tools |
||||
|
|
||||
|
When your app is on-air, you should know about the below tools. You know in airplanes there's _black box recorder_ which is used to understand why the airplane crashed. For .NET below are our *black box recorders*. They capture what happened without attaching a debugger. |
||||
|
|
||||
|
| Tool | What It Does | When to Use | |
||||
|
| --------------------- | --------------------------------------- | ---------------------------- | |
||||
|
| **`dotnet-counters`** | Live metrics like CPU, GC, request rate | Monitor running apps | |
||||
|
| **`dotnet-trace`** | CPU sampling & performance traces | Find slow code | |
||||
|
| **`dotnet-gcdump`** | GC heap dumps (allocations) | Diagnose memory issues | |
||||
|
| **`dotnet-dump`** | Full process dumps | Investigate crashes or hangs | |
||||
|
| **`dotnet-monitor`** | HTTP service exposing all the above | Collect telemetry via API | |
||||
|
|
||||
|
|
||||
|
|
||||
|
------ |
||||
|
|
||||
|
## 7) Build & Run .NET App in Docker the Right Way |
||||
|
|
||||
|
 |
||||
|
|
||||
|
A multi-stage build is a Docker technique where you use one image for building your app and another smaller image for running it. Why we do multi-stage build, because the .NET SDK image is big but has all the build tools. The .NET Runtime image is small and optimized for production. You copy only the published output from the build stage into the runtime stage. |
||||
|
|
||||
|
```dockerfile |
||||
|
# build |
||||
|
FROM mcr.microsoft.com/dotnet/sdk:9.0 AS build |
||||
|
WORKDIR /src |
||||
|
COPY . . |
||||
|
RUN dotnet restore |
||||
|
RUN dotnet publish -c Release -o /app/out -p:PublishTrimmed=true -p:PublishSingleFile=true -p:ReadyToRun=true |
||||
|
|
||||
|
# run |
||||
|
FROM mcr.microsoft.com/dotnet/aspnet:9.0 |
||||
|
WORKDIR /app |
||||
|
ENV ASPNETCORE_URLS=http://+:8080 |
||||
|
EXPOSE 8080 |
||||
|
COPY --from=build /app/out . |
||||
|
ENTRYPOINT ["./YourApp"] # or ["dotnet","YourApp.dll"] |
||||
|
``` |
||||
|
|
||||
|
I'll explain what these Docker file commands; |
||||
|
|
||||
|
**Stage1: Build** |
||||
|
|
||||
|
* `FROM mcr.microsoft.com/dotnet/sdk:9.0 AS build` |
||||
|
Uses the .NET SDK image including compilers and tools. The `AS build` name lets you reference this stage later. |
||||
|
|
||||
|
* `WORKDIR /src` |
||||
|
Sets the working directory inside the container. |
||||
|
|
||||
|
* `COPY . .` |
||||
|
Copies your source code into the container. |
||||
|
|
||||
|
* `RUN dotnet restore` |
||||
|
Restores NuGet packages. |
||||
|
|
||||
|
* `RUN dotnet publish ...` |
||||
|
Builds the project in **Release** mode, optimizes it for production, and outputs it to `/app/out`. |
||||
|
The flags; |
||||
|
* `PublishTrimmed=true` -> removes unused code |
||||
|
* `PublishSingleFile=true` -> bundles everything into one file |
||||
|
* `ReadyToRun=true` -> precompiles code for faster startup |
||||
|
|
||||
|
**Stage 2: Run** |
||||
|
|
||||
|
- `FROM mcr.microsoft.com/dotnet/aspnet:9.0` |
||||
|
Uses a lighter runtime image which no compiler, just the runtime. |
||||
|
- `WORKDIR /app` |
||||
|
Where your app will live inside the container. |
||||
|
- `ENV ASPNETCORE_URLS=http://+:8080` |
||||
|
Makes the app listen on port 8080 (and all network interfaces). |
||||
|
- `EXPOSE 8080` |
||||
|
Documents the port your container uses (for Docker/K8s networking). |
||||
|
- `COPY --from=build /app/out .` |
||||
|
Copies the published output from the **build stage** to this final image. |
||||
|
- `ENTRYPOINT ["./YourApp"]` |
||||
|
Defines the command that runs when the container starts. If you published as a single file, it’s `./YourApp`. f not, use `dotnet YourApp.dll`. |
||||
|
|
||||
|
|
||||
|
|
||||
|
------ |
||||
|
|
||||
|
## 8) Security |
||||
|
|
||||
|
 |
||||
|
|
||||
|
### HTTPS Everywhere Even Behind Proxy |
||||
|
|
||||
|
Even if your app runs behind a reverse proxy like Nginx, Cloudflare or a load balancer, always enforce HTTPS. Why? Because internal traffic can still be captured if you don't use SSL and also cookies, HSTS, browser APIs require HTTPS. In .NET, you can easily enforce HTTPS like this: |
||||
|
|
||||
|
```csharp |
||||
|
app.UseHttpsRedirection(); |
||||
|
``` |
||||
|
|
||||
|
|
||||
|
|
||||
|
### Use HSTS in Production |
||||
|
|
||||
|
HSTS (HTTP Strict Transport Security) tells browsers: |
||||
|
|
||||
|
> Always use HTTPS for this domain — don’t even try HTTP again! |
||||
|
|
||||
|
Once you set, browsers cache this rule, so users can’t accidentally hit the insecure version. You can easily enforce this as below: |
||||
|
|
||||
|
```csharp |
||||
|
if (!app.Environment.IsDevelopment()) |
||||
|
{ |
||||
|
app.UseHsts(); |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
When you use HSTS, it sends browser this HTTP header: ` Strict-Transport-Security: max-age=31536000; includeSubDomains`. Browser will remember this setting for 1 year (31,536,000 seconds) that this site must only use HTTPS. And `includeSubDomains` option applies the rule to all subdomains as well (eg: `api.abp.io`, `cdn.abp.io`, `account.abp.io` etc..) |
||||
|
|
||||
|
### Store Secrets on Environment Variables or Secret Stores |
||||
|
|
||||
|
Never store passwords, connection strings, or API keys in your code or Git. Then where should we keep them? |
||||
|
|
||||
|
- Best/practical way is **Environment variables**. You can easily sett an environment variable in a Unix-like system as below: |
||||
|
|
||||
|
- ```bash |
||||
|
export ConnectionStrings__Default="Server=...;User Id=...;Password=..." |
||||
|
``` |
||||
|
|
||||
|
- And you can easily access these environment variables from your .NET app like this: |
||||
|
|
||||
|
- ```csharp |
||||
|
var conn = builder.Configuration.GetConnectionString("Default"); |
||||
|
``` |
||||
|
|
||||
|
Or **Secret stores** like: Azure Key Vault, AWS Secrets Manager, HashiCorp Vault |
||||
|
|
||||
|
|
||||
|
|
||||
|
### Add Rate-Limiting to Public Endpoints |
||||
|
|
||||
|
Don't forget there'll be not naive guys who will use your app! We've many times faced this issue in the past on our public front-facing websites. So protect your public APIs from abuse, bots, and DDoS. Use rate-limiting!!! Stop brute-force attacks, prevent your resources from exhaustion... |
||||
|
|
||||
|
In .NET, there's a built-in rate-limit feature for .NET (System.Threading.RateLimiting): |
||||
|
|
||||
|
```csharp |
||||
|
builder.Services.AddRateLimiter(_ => _ |
||||
|
.AddFixedWindowLimiter("default", options => |
||||
|
{ |
||||
|
options.PermitLimit = 100; |
||||
|
options.Window = TimeSpan.FromMinutes(1); |
||||
|
})); |
||||
|
|
||||
|
app.UseRateLimiter(); |
||||
|
``` |
||||
|
|
||||
|
- Also there's an open-source rate-limiting library -> [github.com/stefanprodan/AspNetCoreRateLimit](https://github.com/stefanprodan/AspNetCoreRateLimit) |
||||
|
- Another one -> [nuget.org/packages/Polly.RateLimiting](https://www.nuget.org/packages/Polly.RateLimiting) |
||||
|
|
||||
|
### Secure Cookies |
||||
|
|
||||
|
Cookies are often good targets for attacks. You must secure them properly otherwise you can face cookie stealing or CSRF attack. |
||||
|
|
||||
|
```csharp |
||||
|
options.Cookie.SecurePolicy = CookieSecurePolicy.Always; |
||||
|
options.Cookie.SameSite = SameSiteMode.Strict; // or Lax |
||||
|
``` |
||||
|
|
||||
|
- **`SecurePolicy = Always`** -> only send cookies over HTTPS |
||||
|
- **`SameSite=Lax/Strict`** -> prevent CSRF (Cross-Site Request Forgery) |
||||
|
- `Strict` = safest |
||||
|
- `Lax` = good balance for login sessions |
||||
|
|
||||
|
|
||||
|
|
||||
|
------ |
||||
|
|
||||
|
## 9) Startup/Cold Start |
||||
|
|
||||
|
 |
||||
|
|
||||
|
### Keep Tiered JIT On |
||||
|
|
||||
|
The **JIT (Just-In-Time) compiler** converts your app’s Intermediate Language (IL) into native CPU instructions when the code runs. _Tiered JIT_ means the runtime uses 2 stages of compilation. Actually this setting is enabled by default in modern .NET. So just keep it on. |
||||
|
|
||||
|
1. **Tier 0 (Quick JIT):** |
||||
|
Fast, low-optimization compile → gets your app running ASAP. |
||||
|
(Used at startup.) |
||||
|
2. **Tier 1 (Optimized JIT):** |
||||
|
Later, the runtime re-compiles *hot* methods (frequently used ones) with deeper optimizations for speed. |
||||
|
|
||||
|
|
||||
|
|
||||
|
### Use PGO (Profile-Guided Optimization) |
||||
|
|
||||
|
PGO lets .NET learn from real usage of your app. It profiles which functions are used most often, then re-optimizes the build for that pattern. You can think of it as the runtime saying: |
||||
|
|
||||
|
> I’ve seen what your app actually does... I’ll rearrange and optimize code paths accordingly. |
||||
|
|
||||
|
In .NET 8+, you don’t have to manually enable PGO (Profile-Guided Optimization). The JIT collects runtime profiling data (e.g. which types are common, branch predictions) and uses it to generate more optimized code later. In .NET 9, PGO has been improved: the JIT uses PGO data for more patterns (like type checks / casts) and makes better decisions. |
||||
|
|
||||
|
|
||||
|
|
||||
|
------ |
||||
|
|
||||
|
## 10) Graceful Shutdown |
||||
|
|
||||
|
 |
||||
|
|
||||
|
When we break up with our lover, we often argue and regret it later. When an application breaks up with an operating system, it should be done well 😘 ... |
||||
|
When your app stops, maybe you deploy a new version or Kubernetes restarts a pod... the OS sends a signal called `SIGTERM` (terminate). |
||||
|
A **graceful shutdown** means handling that signal properly, finishing what’s running, cleaning up, and exiting cleanly (like an adult)! |
||||
|
|
||||
|
```csharp |
||||
|
var app = builder.Build(); |
||||
|
var lifetime = app.Services.GetRequiredService<IHostApplicationLifetime>(); |
||||
|
lifetime.ApplicationStopping.Register(() => |
||||
|
{ |
||||
|
// stop accepting, finish in-flight, flush telemetry |
||||
|
}); |
||||
|
app.Run(); |
||||
|
``` |
||||
|
|
||||
|
On K8s, set `terminationGracePeriodSeconds` and wire **readiness**/startup probes. |
||||
|
|
||||
|
------ |
||||
|
|
||||
|
## 11) Load Test |
||||
|
|
||||
|
 |
||||
|
|
||||
|
Sometimes arguing with our lover is good. We can see her/his face before marrying 😀 Use **k6** or **bombardier** and test with realistic payloads and prod-like limits. Don't be surprise later when your app is running on prod! These topics should be tested: `CPU %` , `Time in GC` , `LOH Allocations` , `ThreadPool Queue Length` and `Socket Exhaustion`. |
||||
|
|
||||
|
### About K6 |
||||
|
|
||||
|
- A modern load testing tool, using Go and JavaScript. |
||||
|
|
||||
|
- 29K stars on GitHub |
||||
|
- GitHub address: https://github.com/grafana/k6 |
||||
|
|
||||
|
### About Bombardier |
||||
|
|
||||
|
- Fast cross-platform HTTP benchmarking tool written in Go. |
||||
|
|
||||
|
- 7K stars on GitHub |
||||
|
- GitHub address: https://github.com/codesenberg/bombardier |
||||
|
|
||||
|
[](https://trends.google.com/trends/explore?cat=31&q=bombardier%20%2B%20benchmarking,k6%20%2B%20benchmarking) |
||||
|
|
||||
|
## Summary |
||||
|
|
||||
|
In summary, I listed 11 items for optimizing a .NET application for production; Covering build configuration, hosting setup, runtime behavior, data access, telemetry, containerization, security, startup performance and reliability under load. By applying the checklist from Part 1 and Part 2 of this series, leveraging techniques like trimmed releases, server GC, minimal payloads, pooled `DbContexts`, OpenTelemetry, multi-stage Docker builds, HTTPS enforcement, and proper shutdown handling—you’ll improve your app’s durability, scalability and maintainability under real-world traffic and production constraints. Each item is a checkpoint and you’ll be able to deliver a robust, high-performing .NET application ready for live users. |
||||
|
|
||||
|
🎉 Want top-tier .NET performance without the headaches? Try [ABP Framework](https://abp.io?utm_source=alper-ebicoglu-performance-article) for best-performance and skip all the hustles of .NET app development. |
||||
|
|
||||
{kind=link}
|
After Width: | Height: | Size: 394 KiB |
{kind=link}
|
After Width: | Height: | Size: 394 KiB |
@ -0,0 +1,356 @@ |
|||||
|
# 💥 Top 10 Exception Handling Mistakes in .NET (and How to Actually Fix Them) |
||||
|
|
||||
|
Every .NET developer has been there it's 3 AM, production just went down, and the logs are flooding in. |
||||
|
You open the error trace, only to find… nothing useful. The stack trace starts halfway through a catch block, or worse it's empty. Somewhere, an innocent-looking `throw ex;` or a swallowed background exception has just cost hours of sleep. |
||||
|
|
||||
|
Exception handling is one of those things that seems simple on the surface but can quietly undermine an entire system if done wrong. Tiny mistakes like catching `Exception`, forgetting an `await`, or rethrowing incorrectly don't just break code; they break observability. They hide root causes, produce misleading logs, and make even well-architected applications feel unpredictable. |
||||
|
|
||||
|
In this article, we'll go through the most common exception handling mistakes developers make in .NET and more importantly, how to fix them. Along the way, you'll see how small choices in your code can mean the difference between a five-minute fix and a full-blown production nightmare. |
||||
|
|
||||
|
---------- |
||||
|
|
||||
|
## 🧨 1. Catching `Exception` (and Everything Else) |
||||
|
|
||||
|
**The mistake:** |
||||
|
|
||||
|
```csharp |
||||
|
try |
||||
|
{ |
||||
|
// Some operation |
||||
|
} |
||||
|
catch (Exception ex) |
||||
|
{ |
||||
|
// Just to be safe |
||||
|
} |
||||
|
|
||||
|
``` |
||||
|
|
||||
|
**Why it's a problem:** |
||||
|
Catching the base `Exception` type hides all context including `OutOfMemoryException`, `StackOverflowException`, and other runtime-level issues that you should never handle manually. It also makes debugging painful since you lose the ability to treat specific failures differently. |
||||
|
|
||||
|
**The right way:** |
||||
|
Catch only what you can handle: |
||||
|
|
||||
|
```csharp |
||||
|
catch (SqlException ex) |
||||
|
{ |
||||
|
// Handle DB issues |
||||
|
} |
||||
|
catch (IOException ex) |
||||
|
{ |
||||
|
// Handle file issues |
||||
|
} |
||||
|
|
||||
|
``` |
||||
|
|
||||
|
If you really must catch all exceptions (e.g., at a system boundary), **log and rethrow**: |
||||
|
|
||||
|
```csharp |
||||
|
catch (Exception ex) |
||||
|
{ |
||||
|
_logger.LogError(ex, "Unexpected error occurred"); |
||||
|
throw; |
||||
|
} |
||||
|
|
||||
|
``` |
||||
|
|
||||
|
> 💡 **ABP Tip:** In ABP-based applications, you rarely need to catch every exception at the controller or service level. |
||||
|
> The framework's built-in `AbpExceptionFilter` already handles unexpected exceptions, logs them, and returns standardized JSON responses automatically keeping your controllers clean and consistent. |
||||
|
|
||||
|
---------- |
||||
|
|
||||
|
## 🕳️ 2. Swallowing Exceptions Silently |
||||
|
|
||||
|
**The mistake:** |
||||
|
|
||||
|
```csharp |
||||
|
try |
||||
|
{ |
||||
|
DoSomething(); |
||||
|
} |
||||
|
catch |
||||
|
{ |
||||
|
// ignore |
||||
|
} |
||||
|
|
||||
|
``` |
||||
|
|
||||
|
**Why it's a problem:** |
||||
|
Silent failures make debugging nearly impossible. You lose stack traces, error context, and sometimes even awareness that something failed at all. |
||||
|
|
||||
|
**The right way:** |
||||
|
Always log or rethrow, unless you have a very specific reason not to: |
||||
|
|
||||
|
```csharp |
||||
|
try |
||||
|
{ |
||||
|
_cache.Remove(key); |
||||
|
} |
||||
|
catch (Exception ex) |
||||
|
{ |
||||
|
_logger.LogWarning(ex, "Failed to clear cache key {Key}", key); |
||||
|
} |
||||
|
|
||||
|
``` |
||||
|
|
||||
|
> 💡 **ABP Tip:** Since ABP automatically logs all unhandled exceptions, it's often better to let the framework handle them. Only catch exceptions when you want to enrich logs or add custom business logic before rethrowing. |
||||
|
|
||||
|
---------- |
||||
|
|
||||
|
## 🌀 3. Using `throw ex;` Instead of `throw;` |
||||
|
|
||||
|
**The mistake:** |
||||
|
|
||||
|
```csharp |
||||
|
catch (Exception ex) |
||||
|
{ |
||||
|
Log(ex); |
||||
|
throw ex; |
||||
|
} |
||||
|
|
||||
|
``` |
||||
|
|
||||
|
**Why it's a problem:** |
||||
|
Using `throw ex;` resets the stack trace you lose where the exception actually occurred. This is one of the biggest causes of misleading production logs. |
||||
|
|
||||
|
**The right way:** |
||||
|
|
||||
|
```csharp |
||||
|
catch (Exception ex) |
||||
|
{ |
||||
|
Log(ex); |
||||
|
throw; // preserves stack trace |
||||
|
} |
||||
|
|
||||
|
``` |
||||
|
|
||||
|
---------- |
||||
|
|
||||
|
## ⚙️ 4. Wrapping Everything in Try/Catch |
||||
|
|
||||
|
**The mistake:** |
||||
|
Developers sometimes wrap _every function_ in try/catch “just to be safe.” |
||||
|
|
||||
|
**Why it's a problem:** |
||||
|
This clutters your code and hides the real source of problems. Exception handling should happen at **system boundaries**, not in every method. |
||||
|
|
||||
|
**The right way:** |
||||
|
Handle exceptions at higher levels (e.g., middleware, controllers, background jobs). Let lower layers throw naturally. |
||||
|
|
||||
|
> 💡 **ABP Tip:** The ABP Framework provides a top-level exception pipeline via filters and middleware. You can focus purely on your business logic ABP automatically translates unhandled exceptions into standardized API responses. |
||||
|
|
||||
|
---------- |
||||
|
|
||||
|
## 📉 5. Using Exceptions for Control Flow |
||||
|
|
||||
|
**The mistake:** |
||||
|
|
||||
|
```csharp |
||||
|
try |
||||
|
{ |
||||
|
var user = GetUserById(id); |
||||
|
} |
||||
|
catch (UserNotFoundException) |
||||
|
{ |
||||
|
user = CreateNewUser(); |
||||
|
} |
||||
|
|
||||
|
``` |
||||
|
|
||||
|
**Why it's a problem:** |
||||
|
Exceptions are expensive and should represent _unexpected_ states, not normal control flow. |
||||
|
|
||||
|
**The right way:** |
||||
|
|
||||
|
```csharp |
||||
|
var user = GetUserByIdOrDefault(id) ?? CreateNewUser(); |
||||
|
|
||||
|
``` |
||||
|
|
||||
|
---------- |
||||
|
|
||||
|
## 🪓 6. Forgetting to Await Async Calls |
||||
|
|
||||
|
**The mistake:** |
||||
|
|
||||
|
```csharp |
||||
|
try |
||||
|
{ |
||||
|
DoSomethingAsync(); // missing await! |
||||
|
} |
||||
|
catch (Exception ex) |
||||
|
{ |
||||
|
... |
||||
|
} |
||||
|
|
||||
|
``` |
||||
|
|
||||
|
**Why it's a problem:** |
||||
|
Without `await`, the exception happens on another thread, outside your `try/catch`. It never gets caught. |
||||
|
|
||||
|
**The right way:** |
||||
|
|
||||
|
```csharp |
||||
|
try |
||||
|
{ |
||||
|
await DoSomethingAsync(); |
||||
|
} |
||||
|
catch (Exception ex) |
||||
|
{ |
||||
|
_logger.LogError(ex, "Error during async operation"); |
||||
|
} |
||||
|
|
||||
|
``` |
||||
|
|
||||
|
---------- |
||||
|
|
||||
|
## 🧵 7. Ignoring Background Task Exceptions |
||||
|
|
||||
|
**The mistake:** |
||||
|
|
||||
|
```csharp |
||||
|
Task.Run(() => SomeWork()); |
||||
|
|
||||
|
``` |
||||
|
|
||||
|
**Why it's a problem:** |
||||
|
Unobserved task exceptions can crash your process or vanish silently, depending on configuration. |
||||
|
|
||||
|
**The right way:** |
||||
|
|
||||
|
```csharp |
||||
|
_ = Task.Run(async () => |
||||
|
{ |
||||
|
try |
||||
|
{ |
||||
|
await SomeWork(); |
||||
|
} |
||||
|
catch (Exception ex) |
||||
|
{ |
||||
|
_logger.LogError(ex, "Background task failed"); |
||||
|
} |
||||
|
}); |
||||
|
|
||||
|
``` |
||||
|
|
||||
|
---------- |
||||
|
|
||||
|
## 📦 8. Throwing Generic Exceptions |
||||
|
|
||||
|
**The mistake:** |
||||
|
|
||||
|
```csharp |
||||
|
throw new Exception("Something went wrong"); |
||||
|
|
||||
|
``` |
||||
|
|
||||
|
**Why it's a problem:** |
||||
|
Generic exceptions carry no semantic meaning. You can't catch or interpret them specifically later. |
||||
|
|
||||
|
**The right way:** |
||||
|
Use more descriptive types: |
||||
|
|
||||
|
```csharp |
||||
|
throw new InvalidOperationException("Order is already processed"); |
||||
|
|
||||
|
``` |
||||
|
|
||||
|
> 💡 **ABP Tip:** In ABP applications, you can throw a `BusinessException` or `UserFriendlyException` instead. |
||||
|
> These support structured data, error codes, localization, and automatic HTTP status mapping: |
||||
|
> |
||||
|
> ```csharp |
||||
|
> throw new BusinessException("App:010046") |
||||
|
> .WithData("UserName", "john"); |
||||
|
> |
||||
|
> ``` |
||||
|
> |
||||
|
> This integrates with ABP's localization system, letting your error messages be translated automatically based on the error code. |
||||
|
|
||||
|
---------- |
||||
|
|
||||
|
## 🪞 9. Losing Inner Exceptions |
||||
|
|
||||
|
**The mistake:** |
||||
|
|
||||
|
```csharp |
||||
|
catch (Exception ex) |
||||
|
{ |
||||
|
throw new CustomException("Failed to process order"); |
||||
|
} |
||||
|
|
||||
|
``` |
||||
|
|
||||
|
**Why it's a problem:** |
||||
|
You lose the inner exception and its stack trace the real reason behind the failure. |
||||
|
|
||||
|
**The right way:** |
||||
|
|
||||
|
```csharp |
||||
|
catch (Exception ex) |
||||
|
{ |
||||
|
throw new CustomException("Failed to process order", ex); |
||||
|
} |
||||
|
|
||||
|
``` |
||||
|
|
||||
|
> 💡 **ABP Tip:** ABP automatically preserves and logs inner exceptions (for example, inside `BusinessException` chains). You don't need to add boilerplate to capture nested errors just throw them properly. |
||||
|
|
||||
|
---------- |
||||
|
|
||||
|
## 🧭 10. Missing Global Exception Handling |
||||
|
|
||||
|
**The mistake:** |
||||
|
Catching exceptions manually in every controller. |
||||
|
|
||||
|
**Why it's a problem:** |
||||
|
It creates duplicated logic, inconsistent responses, and gaps in logging. |
||||
|
|
||||
|
**The right way:** |
||||
|
Use middleware or a global exception filter: |
||||
|
|
||||
|
```csharp |
||||
|
app.UseExceptionHandler("/error"); |
||||
|
|
||||
|
``` |
||||
|
|
||||
|
> 💡 **ABP Tip:** ABP already includes a complete global exception system that: |
||||
|
> |
||||
|
> - Logs exceptions automatically |
||||
|
> |
||||
|
> - Returns a standard `RemoteServiceErrorResponse` JSON object |
||||
|
> |
||||
|
> - Maps exceptions to correct HTTP status codes (e.g., 403 for business rules, 404 for entity not found, 400 for validation) |
||||
|
> |
||||
|
> - Allows customization through `AbpExceptionHttpStatusCodeOptions` |
||||
|
> You can even implement an `ExceptionSubscriber` to react to certain exceptions (e.g., send notifications or trigger audits). |
||||
|
> |
||||
|
|
||||
|
---------- |
||||
|
|
||||
|
## 🧩 Bonus: Validation Is Not an Exception |
||||
|
|
||||
|
**The mistake:** |
||||
|
Throwing exceptions for predictable user input errors. |
||||
|
|
||||
|
**The right way:** |
||||
|
Use proper validation instead: |
||||
|
|
||||
|
```csharp |
||||
|
[Required] |
||||
|
public string UserName { get; set; } |
||||
|
|
||||
|
``` |
||||
|
|
||||
|
> 💡 **ABP Tip:** ABP automatically throws an `AbpValidationException` when DTO validation fails. |
||||
|
> You don't need to handle this manually ABP formats it into a structured JSON response with `validationErrors`. |
||||
|
|
||||
|
---------- |
||||
|
|
||||
|
## 🧠 Final Thoughts |
||||
|
|
||||
|
Exception handling isn't just about preventing crashes it's about making your failures **observable, meaningful, and recoverable**. |
||||
|
When done right, your logs tell a story: _what happened, where, and why_. |
||||
|
When done wrong, you're left staring at a 3 AM mystery. |
||||
|
|
||||
|
By avoiding these common pitfalls and taking advantage of frameworks like ABP that handle the heavy lifting you'll spend less time chasing ghosts and more time building stable, predictable systems. |
||||
|
|
||||
@ -0,0 +1,102 @@ |
|||||
|
# Uncovering ABP’s Hidden Magic: Supercharging ASP.NET Core Development |
||||
|
Experienced back-end developers often approach new frameworks with healthy skepticism. But many who try the ABP Framework quickly notice something different: things “just work” with minimal boilerplate. There’s a good reason ABP can feel magical – it silently handles a host of tedious tasks behind the scenes. In this article, we’ll explore how ABP’s out-of-the-box features and modular architecture dramatically boost productivity. We’ll compare with plain ASP.NET Core where relevant, so you can appreciate what ABP is doing for you under the hood. |
||||
|
|
||||
|
## Beyond the Basics: Why ABP Feels Magical |
||||
|
ABP isn’t a typical library; it’s a full application framework that goes beyond the basics. From the moment you start an ABP project, a lot is happening automatically. Have you ever built an ASP.NET Core app and spent time wiring up cross-cutting concerns like error handling, logging, security tokens, or multi-tenancy? With ABP, much of that comes pre-configured. You might find that you write just your business logic, and ABP has already enabled security, transactions, and even APIs for you by convention. This can be disorienting at first (“Where’s the code that does X?”) until you realize ABP’s design is doing it for you, in line with best practices. |
||||
|
|
||||
|
For example, ABP completely automates CSRF (anti-forgery) protection and it works out-of-the-box without any configuration. In a plain ASP.NET Core project, you’d have to add anti-forgery tokens to your views or enable a global filter and manually include the token in AJAX calls. ABP’s startup template already includes a global antiforgery filter and even sets up the client-side code to send the token on each request, without you writing a line. This kind of “invisible” setup is repeated across many areas. ABP’s philosophy is to take care of the plumbing – like unit of work, data filters, audit logging, etc. – so you can focus on the real code. It feels magical because things that would normally require explicit code or packages in ASP.NET Core are just handled. As we peel back the layers in the next sections, you’ll see how ABP pulls off these tricks. |
||||
|
|
||||
|
## Zero to Hero: Rapid Application Development with ABP |
||||
|
One of the most striking benefits of ABP is how quickly you can go from zero to a fully functional application – it’s a true rapid application development platform. With ASP.NET Core alone, setting up a new project with identity management, localization, an API layer, and a clean architecture can be a day’s work or more. In contrast, ABP’s startup templates give you a solution with all those pieces pre-wired. You can create a new ABP project (using the ABP CLI or ABP Studio) and run it, and you already have: user login and registration, role-based permission management, an admin UI, a REST API layer with Swagger, and a clean domain-driven code structure. It’s essentially a jump-start that takes you from zero to hero in record time. |
||||
|
|
||||
|
Rapid development is further enabled by ABP’s coding model. Define an entity and an application service, and ABP can generate the REST API endpoints for you automatically (via Conventional Controllers). You don’t need to write repetitive controllers that just call the service; ABP’s conventions map your service methods to HTTP verbs and routes by naming convention. For instance, a method name `GetListAsync()` in an `AppService` becomes an HTTP `GET` to `/api/app/your-entity` without extra attributes. The result: you implement application logic once in the application layer, and ABP instantly exposes it as an API (and even provides client proxies for UI). |
||||
|
|
||||
|
The tooling in the ABP ecosystem multiplies this productivity. The ABP Suite tool, for example, allows you to visually design entities and then generate a full-stack CRUD page for your entities in seconds, complete with UI forms, validation, DTOs, application services, and even unit tests. The generated code follows ABP’s best practices (layered architecture, proper authorization checks, etc.), so you’re not creating a maintenance headache. You get a working feature out-of-the-box and can then tweak it to your needs. All these accelerators mean you can deliver features at a higher velocity than ever, turning a blank project into a real application with minimal grunt work. |
||||
|
|
||||
|
## Modular Architecture: Building Like Digital Lego |
||||
|
Perhaps the greatest strength of ABP is its modular architecture. Think of modules as building blocks – “digital Lego” pieces – that you can snap together to compose your application. ABP itself is built on modules (for example, Identity, Audit Logging, Language Management, etc.), and you can develop your own modules as well. This design encourages separation of concerns and reusability. Need a certain functionality? Chances are, ABP has a module for it – just plug it in, and it works seamlessly with the others. |
||||
|
|
||||
|
With plain ASP.NET Core, setting up a modular system requires a lot of upfront design. ABP, however, “is born to be a modular application development structure”, where every feature is compatible with modular development by default. The framework ensures that each module can encapsulate its own domain, application services, database migrations, UI pages, etc., without tight coupling. For example, the ABP Identity module provides all the user and role management functionality (built atop ASP.NET Core Identity), the SaaS module provides multi-tenant management, the Audit Logging module records user activities, and so on. You can include these modules in your project, gaining enterprise-grade functionality in literally one line of configuration. As the official documentation puts it, ABP provides “a lot of re-usable application modules like payment, chat, file management, audit log reporting… All of these modules are easily installed into your solution and directly work.” This is a huge time saver – you’re not reinventing the wheel for common requirements. |
||||
|
|
||||
|
The Lego-like nature also means you can remove or swap pieces without breaking the whole. If a built-in module doesn’t meet your needs, you can extend it or replace it (we’ll talk about customization later). Modules can even be maintained as separate packages, enabling teams to develop features in isolation and share modules across projects. Ultimately, ABP’s modularity gives your architecture a level of flexibility and organization that plain ASP.NET Core doesn’t provide out-of-the-box. It’s a solid foundation for either monolithic applications or microservice systems, as you can start with a modular monolith and later split modules into services if needed. In short, ABP provides the architectural “bricks” – you design the house. |
||||
|
|
||||
|
## Out-of-the-Box Features that Save Weeks of Work |
||||
|
Beyond the big building blocks, ABP comes with a plethora of built-in features that operate behind the scenes to save you time. These are things that, in a non-ABP project, you would likely spend days or weeks implementing and fine-tuning – but ABP gives them to you on Day 1. Here are some of the key hidden gems ABP provides out-of-the-box: |
||||
|
|
||||
|
- CSRF Protection: As mentioned earlier, ABP automatically enables anti-forgery tokens for you. You get robust CSRF/XSRF protection by default – the server issues a token cookie and expects a header on modify requests, all handled by ABP’s infrastructure without manual setup. This means your app is defended against cross-site request forgery with essentially zero effort on your part. |
||||
|
- Automated Data Filtering: ABP uses data filters to transparently apply common query conditions. For example, if an entity implements `ISoftDelete`, it will not be retrieved in queries unless you explicitly ask for deleted data. ABP automatically sets `IsDeleted=true` instead of truly deleting and filters it out on queries, so you don’t accidentally show or modify soft-deleted records. Similarly, if an entity implements `IMultiTenant`, ABP will “silently in the background” filter all queries to the current tenant and fill the `TenantId` on new records – no need to manually add tenant clauses to every repository query. These filters (and others) are on by default and can be toggled when needed, giving you multi-tenancy and soft delete behavior out-of-the-box. |
||||
|
- Concurrency Control: In enterprise apps, it’s important to handle concurrent edits to avoid clobbering data. ABP makes this easy with an optimistic concurrency system. If you implement `IHasConcurrencyStamp` on an entity, ABP will automatically set a GUID stamp on insert and check that stamp on updates to detect conflicts, throwing an exception if the record was changed by someone else. In ASP.NET Core EF you’d set up a RowVersion or concurrency token manually – ABP’s built-in approach is a ready-to-use solution to ensure data consistency. |
||||
|
- Data Seeding: Most applications need initial seed data (like an admin user, initial roles, etc.). ABP provides a modular data seeding system that runs on application startup or during migration. You can implement an `IDataSeedContributor` and ABP will automatically discover and execute it as part of the seeding process. Different modules add their own seed contributors (for example, the Identity module seeds the admin user/role). This system is database-independent and even works in production deployments (the templates include a DbMigrator tool to apply migrations and seed data). It’s more flexible than EF Core’s native seeding and saves you writing custom seeding scripts. |
||||
|
- Audit Logging: ABP has an integrated auditing mechanism that logs details of each web request. By default, an audit log is created for each API call or MVC page hit, recording who did what and when. It captures the URL and HTTP method, execution duration, the user making the call, the parameters passed to application services, any exceptions thrown, and even entity changes saved to the database during the request. All of this is saved automatically (for example, into the AbpAuditLogs table if using EF Core). The startup templates enable auditing by default, so you have an audit trail with no extra coding. In a vanilla ASP.NET Core app, you’d have to implement your own logging to achieve this level of detail. |
||||
|
- Unit of Work & Transaction Management: ABP implements the Unit of Work pattern globally. When you call a repository or an application service method, ABP will automatically start a UOW (database transaction) for you if one isn’t already running. It will commit on success or roll back on error. By convention, all app service methods, controller actions, and repository methods are wrapped in a UOW – so you don’t explicitly call SaveChanges() or begin transactions in most cases. For example, if you create or update multiple entities in an app service method, they either all succeed or all fail as a unit. This behavior is there “for free”, whereas in raw ASP.NET Core you’d be writing try/catch and transaction code around such operations. (ABP even avoids opening transactions on read-only GET requests by default for performance.) |
||||
|
- Global Exception Handling: No need to write a global exception filter – ABP provides one. If an unhandled exception occurs in an API endpoint, ABP’s exception handling system catches it and returns a standardized error response in JSON. It also maps known exception types to appropriate HTTP status codes and can localize error messages. This means your client applications always get a clean, consistent error format (with an error code, message, validation details, etc.) instead of ugly stack traces or HTML error pages. Internally, ABP logs the error details and hides the sensitive info from the client by default. Essentially, you get production-ready error handling without writing it yourself. |
||||
|
- Localization & Multi-Language Support: ABP’s localization system is built on the .NET localization extension but adds convenient enhancements. It automatically determines the user’s language/culture for each request (by checking the browser or tenant settings) and you can define localization resources in JSON files easily. ABP supports database-backed translations via the Language Management module as well. From day one, your app is ready to be translated – even exception messages and validation errors are localization-friendly. The default project template sets up a default resource and uses it for all framework-provided texts, meaning things like error messages or menu items are already localized (and you can add new languages through the UI if you include the module). In short, ABP bakes in multi-lingual capabilities so you don’t have to internationalize your app from scratch. |
||||
|
- Background Jobs: Need to run tasks in the background (e.g. send emails, generate reports) without blocking the user? ABP has a built-in background job infrastructure. You can simply implement a job class and enqueue it via `IBackgroundJobManager`. By default, jobs are persisted and executed, and ABP has providers to integrate with popular systems like Hangfire, RabbitMQ and Quartz if you need scalability. For example, sending an email after a user registers can be offloaded to a background job with one method call. ABP will handle retries on failure and storing the job info. This saves you the effort of configuring a separate job runner or scheduler – it’s part of the framework. |
||||
|
- Security & Defaults: ABP comes with sensible security defaults. It’s integrated with ASP.NET Core Identity, so password policies, lockout on multiple failed logins, and other best practices are in place by default. The framework also adds standard security headers to HTTP responses (against XSS, clickjacking, etc.) through its startup configuration. Additionally, ABP’s permission system is pre-configured: every module brings its own permission definitions, and you can easily check permissions with an attribute or method call. There’s even a built-in Permission Management UI (if you include the module) where you can grant or revoke permissions per role or user at runtime. All these defaults mean a lot of the “boring” but critical security work is done for you. |
||||
|
- Paging & Query Limiting: ABP encourages efficient data access patterns. For list endpoints, the framework DTOs usually include paging parameters (MaxResultCount, SkipCount), and if you don't specify them, ABP will assume default values (often 10). ABP also enforces an upper limit on how many records can be requested in a single call, preventing potential performance issues from overly large queries. This protects your application from accidentally pulling thousands of records in one go. Of course, you can configure or override these limits, but the safe defaults are there to protect your application. |
||||
|
|
||||
|
That’s a long list – and it’s not even exhaustive – but the pattern is clear. ABP spares you from writing a lot of infrastructure and “glue” code. And if you do need multi-tenancy (or any of these advanced features), the time savings grow even more. These out-of-the-box capabilities let you focus on your business logic, since the baseline features are already in place. Next, let’s zoom in on a couple of these areas (like multi-tenancy and security) that typically cause headaches in pure ASP.NET Core but are a breeze with ABP. |
||||
|
|
||||
|
## Seamless Multi-Tenancy: Scaling Without the Headaches |
||||
|
Multi-tenant architecture – supporting multiple isolated customers (tenants) in one application – is notoriously tricky to implement from scratch. You have to partition data per tenant, ensure no cross-tenant data leaks, manage connection strings if using separate databases, and adapt authentication/authorization to be tenant-aware. ABP Framework makes multi-tenancy almost trivial in comparison. |
||||
|
|
||||
|
Out of the box, ABP supports both approaches to multi-tenancy: single database with tenant segregation and separate databases per tenant, or even a hybrid of the two. If you go the single database route, as many SaaS apps do for simplicity, ABP will ensure every entity that implements the tenant interface (`IMultiTenant`) gets a `TenantId` value and is automatically filtered. As we touched on earlier, you don’t have to manually add `.Where(t => t.TenantId == currentTenant.Id)` on every query – ABP’s data filter does that behind the scenes based on the logged-in user’s tenant. If a user from Tenant A tries to access Tenant B’s data by ID, they simply won’t find it, because the filter is in effect on all repositories. Similarly, when saving data, ABP sets the `TenantId` for you. This isolation is enforced at the ORM level by ABP’s infrastructure. |
||||
|
|
||||
|
For multiple databases, ABP’s SaaS (Software-as-a-Service) module handles tenant management. At runtime, the framework can switch the database connection string based on the tenant context. In the ABP startup template, there’s a “tenant management” UI that lets an admin add new tenants and specify their connection strings. If a connection string is provided, ABP will use that database for that tenant’s data. If not, it falls back to the default shared database. Remarkably, from a developer’s perspective, the code you write is the same in both cases – ABP abstracts the difference. In practice, you just write repository queries as usual; ABP will route those to the appropriate place and filter as needed. |
||||
|
|
||||
|
Another pain point that ABP solves is making other subsystems tenant-aware. For example, ASP.NET Core Identity (for user accounts) isn’t multi-tenant by default, and neither is Keycloak, IdentityServer or OpenIddict (for authentication). ABP takes care of configuring these to work in a tenant context. When a user logs in, they do so with a tenant domain or tenant selection, and the identity system knows about the tenant. Permissions in ABP are also tenant-scoped by default – a tenant admin can only manage roles/permissions within their tenant, for instance. ABP’s modules are built to respect tenant boundaries out-of-the-box. |
||||
|
|
||||
|
What does all this mean for you? It means you can offer a multi-tenant SaaS solution without writing the bulk of the isolation logic. Instead of spending weeks on multi-tenancy infrastructure, you essentially flip a switch in ABP (enable multi-tenancy, use the SaaS module) and focus on higher-level concerns. |
||||
|
|
||||
|
## Security That Works Without the Pain |
||||
|
Security is one area you do not want to get wrong. With plain ASP.NET Core, you have great tools (Identity, etc.) at your disposal, but a lot of configuration and integration work to tie them together in a full application. ABP takes the sting out of implementing security by providing a comprehensive, pre-integrated security model. |
||||
|
|
||||
|
To start, ABP’s application templates include the Identity Module, which is a ready-made integration of ASP.NET Core Identity (the membership system) with ABP’s framework. You get user and role entities extended to fit in ABP’s domain model, and a UI for user and role management. All the heavy lifting of setting up identity tables, password hashing, email confirmation, two-factor auth, etc. is done. The moment you run an ABP application, you can log in with the seeded admin account and manage users and roles through a built-in administration page. This would take significant effort to wire up yourself in a new ASP.NET Core app; ABP gives it to you out-of-the-box. |
||||
|
|
||||
|
Permission management is another boon. In an ABP solution, you don’t have to hard-code what each role can do – instead, ABP provides a declarative way to define permissions and a UI to assign those permissions to roles or users. The Permission Management module’s UI allows dynamic granting/revoking of permissions. Under the hood, ABP’s authorization system will automatically check those permissions when you annotate your application services or controllers with [Authorize] and a policy name (the policy maps to a permission). For example, you might declare a permission Inventory.DeleteProducts. In your ProductAppService’s DeleteAsync method, you add [Authorize("Inventory.DeleteProducts")]. ABP will ensure the current user has that permission (through their roles or direct assignment) before allowing the method to execute. If not, it throws a standardized authorization exception. This is standard ASP.NET Core policy-based auth, but ABP streamlines defining and managing the policies by its permission system. The result: secure by default – it’s straightforward to enforce role-based access control throughout your application, and even non-developers (with access to the admin UI) can adjust permissions as requirements evolve. |
||||
|
|
||||
|
We already discussed CSRF protection, but it’s worth reiterating in the security context: ABP saves you from common web vulnerabilities by enabling defenses by default. Anti-forgery tokens are automatic, and output encoding (to prevent XSS) is naturally handled by using Razor Pages or Angular with proper binding (framework features that ABP leverages). ABP also sets up ASP.NET Core’s Data Protection API for things like cookie encryption and CSRF token generation behind the scenes in its startup, so you get a proper cryptographic key management for free. |
||||
|
|
||||
|
Another underappreciated aspect is exception shielding. In development, you want to see detailed errors, but in production you should not reveal internal details (stack traces, etc.) to the client. ABP’s exception filter will output a generic error message to the client while logging the detailed exception on the server. This prevents information leakage that attackers could exploit, without you having to configure custom middleware or filters. |
||||
|
|
||||
|
On the topic of authentication: ABP supports modern authentication scenarios too. If you want to build a microservice or single-page app (SPA) architecture, ABP provides modules for OpenID Connect and OAuth2 protocol implementations. The ABP Commercial version even provides an OpenIddict setup out-of-the-box for issuing JWTs to SPAs or mobile apps. This means you can stand up a secure token service and resource servers with minimal configuration. With ABP, much of the configuration (clients, scopes, grants) is abstracted by the framework. |
||||
|
|
||||
|
In short, ABP’s approach to security is holistic and follows the mantra of secure by default. New ABP developers are often pleasantly surprised that they didn’t have to spend days on user auth or protecting API endpoints – it’s largely handled. Of course, you still design your authorization logic (defining who can do what), but ABP provides the scaffolding to enforce it consistently. The painful parts of security – getting the plumbing right – are taken care of, so you can focus on the policies and rules that matter for your domain. This dramatically lowers the risk of security holes compared to rolling it all yourself. |
||||
|
|
||||
|
## Customization Without Chaos |
||||
|
With all this magic happening automatically, you might wonder: “What if I need to do it differently? Can I customize or override ABP’s behavior?” The answer is a resounding yes. ABP is designed with extension points and configurability in mind, so you can change the defaults without hacking the framework. This is important for keeping your project maintainable – you get ABP’s benefits, but you’re not boxed in when requirements demand a change. |
||||
|
|
||||
|
One way ABP enables customization is through its powerful dependency injection system and the modular structure. Because each feature is delivered via services (interfaces and classes) in DI, you can replace almost any ABP service with your own implementation if needed. For example, if you want to change how the IdentityUserAppService (the service behind user management) works, you can create your own class inheriting or implementing the same interface, and register it with `Dependency(ReplaceServices = true)`. ABP will start using your class in place of the original. This is an elegant way to override behavior without modifying ABP’s source – keeping you on the upgrade path for new versions. ABP’s team intentionally makes most methods virtual to support overriding in derived classes. This means you can subclass an ABP application service or domain service and override just the specific method you need to change, rather than writing a whole service from scratch. |
||||
|
|
||||
|
|
||||
|
Beyond swapping out services, ABP offers configuration options for its features. Virtually every subsystem has an options class you can configure in your module startup. Not liking the 10-item default page size? You can change the default MaxResultCount. Want to disable a filter globally? You can toggle, say, soft-delete filtering off by default using `AbpDataFilterOptions`. Need to turn off auditing for certain operations? Configure `AbpAuditingOptions` to ignore them. These options give you a lot of control to tweak ABP’s behavior. And because they’re central configurations, you aren’t scattering magic numbers or settings throughout your code – it’s a structured approach to customization. |
||||
|
|
||||
|
Another area is UI and theming. ABP’s UI (if you use the integrated UI) is also modular and replaceable. You can override Razor components or pages from a module by simply re-declaring them in your web project. For instance, if you want to modify the login page from the Account module, you can add a Razor page with the same path in your web layer – ABP will use yours instead of the default. The documentation has guidance on how to override views, JavaScript, CSS, etc., in a safe manner for Angular, Blazor, and MVC. The LeptonX theme that ABP uses can be customized via SCSS variables or entirely new theme derivations. The key point is, you’re never stuck with the “out-of-the-box” look or logic if it doesn’t fit your needs. ABP gives you the foundation, and you’re free to build on top of it or change it. |
||||
|
|
||||
|
The best part? These customizations stay clean and organized. ABP's extension patterns prevent your project from becoming a mess of patches. When ABP releases updates, your overrides remain intact – no more copy-pasting framework code or dealing with merge conflicts. You get ABP's smart defaults plus the freedom to customize when needed. |
||||
|
|
||||
|
## Ecosystem Power: ABP’s Tools, Templates, and Integrations |
||||
|
ABP is more than just a runtime framework; it’s surrounded by an ecosystem of tools and libraries that amplify productivity. We’ve touched on a few (like the ABP Suite code generator), but let’s look at the broader ecosystem that comes with ABP. |
||||
|
|
||||
|
- Project Templates: ABP provides multiple startup templates (via the ABP CLI or Studio) for different architectures – from a simple monolithic web app to a layered modular monolith, or even a microservice-oriented solution with multiple projects pre-configured. These templates are not empty skeletons; they include working examples of authentication, a UI theme, navigation, and so on for your own modules. The microservice template, for instance, sets up separate identity, administration, and SaaS services with communication patterns already wired. Using these templates can save you a huge amount of setup time and ensure you follow best practices from the get-go. |
||||
|
- ABP CLI: The command-line tool abp is a developer’s handy companion. With it, you can generate new solutions or modules, add package references, update your ABP version, and even client proxy generations with simple commands. |
||||
|
- ABP Studio: It is a cross-platform desktop environment designed to make working with ABP solutions smoother and more insightful. It provides a unified UI to create, run, monitor, and manage your ABP projects – whether you're building a monolith or a microservice system. With features like a real-time Application Monitor, Solution Runner, and Kubernetes integration, it brings operational visibility and ease-of-use to development workflows. Studio also includes tools for managing modules, packages, and even launching integrated tools like ABP Suite – all from a single place. Think of it as a control center for your ABP solutions. |
||||
|
- ABP Suite: It is a powerful visual tool (included in PRO licenses) that helps you generate full-stack CRUD pages in minutes. Define your entities, their relationships, and hit generate – ABP Suite scaffolds everything from the database model to the HTTP APIs, application services, and UI components. It supports one-to-many and many-to-many relationships, master-detail patterns, and even lets you generate from existing database tables. Developers can customize the generated code using predefined hook points that persist across regenerations. |
||||
|
- 3rd-Party Integrations: Modern applications often need to integrate with messaging systems, distributed caching, search engines, etc. ABP recognizes this and provides integration packages for many common technologies. Want to use RabbitMQ for event bus or background jobs? ABP has you covered. The same goes for others: ABP has modules or packages for Redis caching, Kafka distributed event bus, SignalR real-time hubs, Twilio SMS, Stripe payments, and more. Each integration is done in a way that it feels like a natural extension of the ABP environment (for example, using the same configuration system and dependency injection). This saves you from writing repetitive integration code or dealing with each library’s nuances in every project. |
||||
|
- UI Themes and Multi-UI Support: ABP comes with a modern default theme (LeptonX) for web applications, and it supports Angular, MVC/Razor Pages and Blazor out-of-the-box. If you prefer Angular for frontend, ABP offers an Angular UI package that works with the same backend. There’s also support for mobile via React Native or MAUI templates. The ability to switch UI front-ends (or even support multiple simultaneously, e.g. an Angular SPA and a Blazor server app using the same API) is facilitated by ABP’s API and authentication infrastructure. This dramatically reduces the friction when setting up a new client application – you don’t have to hand-roll API clients or auth flows. |
||||
|
- Community and Samples: While not a tool per se, the ABP community is part of the ecosystem and adds a lot of value. There are official sample projects (like eShopOnAbp, a full microservice reference application) and many community-contributed modules on GitHub. The consistency of ABP’s structure means community modules or examples are easier to understand and plug in. Being in a community where “everyone follows similar coding styles and principles” means code and knowledge are highly transferable. Developers share open source ABP modules (for example, there are community modules for things like blob storage management, setting UI, React frontend support, etc., beyond the official ones). This network effect is an often overlooked part of the ecosystem: as ABP’s adoption grows, so do the resources you can draw on, from Q&A to reusable code. |
||||
|
|
||||
|
In summary, ABP’s ecosystem provides a full-platform experience. It’s not just the core framework, but also the tooling to work with that framework efficiently and the integrations to connect it with the wider tech world. By using ABP, you’re not piecing together disparate tools – you have a coherent set of solutions designed to work in concert. This is the kind of ecosystem that traditionally only large enterprises or opinionated tech stacks provided, but ABP makes it accessible in the .NET open-source space. It supercharges development in a way that goes beyond just writing code faster; it’s about having a robust infrastructure around your code, so you can deliver more value with less guesswork. |
||||
|
|
||||
|
## Developer Happiness: The Hidden Productivity Boost |
||||
|
All these features and time-savers aren’t just about checking off technical boxes – they have a profound effect on developer happiness and productivity. When a framework handles the heavy lifting and enforces good practices, developers can spend more time on interesting problems (and less on boilerplate or bug-hunting). ABP’s “hidden” features – the things that work without you even noticing – contribute to a less stressful development experience. |
||||
|
|
||||
|
Think about the common sources of frustration in back-end development: security holes that come back to bite you, race conditions or transaction bugs, deployment issues because some configuration was missed, writing the same logging or exception handling code in every project… ABP’s approach preempts many of these. There’s confidence in knowing that the framework has built-in solutions for common pitfalls. For instance, you’re less likely to have a data inconsistency bug because ABP’s unit of work ensured all your DB operations were atomic. This confidence means developers can focus on delivering features rather than constantly firefighting or re-architecting core pieces. |
||||
|
|
||||
|
Another aspect of developer happiness is consistency. ABP provides a uniform structure – every module has the same layering (Domain, Application, etc.), every web endpoint returns a standard response, and so on. Once you learn the patterns, you can navigate and contribute to any part of an ABP application with ease. New team members or even outside contributors ramp up faster because the project structure is familiar (it’s the ABP structure). This reduces the bus factor and onboarding time on teams – a source of relief for developers and managers alike. |
||||
|
|
||||
|
Moreover, by taking away a lot of the “yak shaving” (the endless setup tasks), ABP lets you as a developer spend your energy on creative problem-solving and delivering value. It’s simply more fun to develop when you can swiftly implement a feature without being bogged down in plumbing code. The positive feedback loop of having working features quickly (thanks to things like ABP Suite, or just the rapid scaffolding of ABP) can be very motivating. It feels like you have an expert co-pilot who has already wired the security system, laid out the architecture, and packed the toolkit with everything you need – so you can drive the project forward confidently. |
||||
|
|
||||
|
Finally, the community support adds to this happiness. There’s a thriving Discord server and forum where ABP developers help each other. Since ABP standardizes a lot, advice from one person’s experience often applies directly to your scenario. That sense of not being alone when you hit a snag – because others likely encountered and solved it – reduces anxiety and speeds up problem resolution. It’s the kind of developer experience where things “just work,” and when they occasionally don’t, you have a clear path to figure it out (good docs, support, community). In the daily life of a software developer, this can make a huge difference. |
||||
|
|
||||
|
In conclusion, ABP’s multitude of behind-the-scenes features are not about making the framework look impressive on paper – they’re about making you, the developer, more productive and happier in your job. By handling the boring, complex, or repetitive stuff, ABP lets you focus on building great software. It’s like having a teammate who has already done half the work before you even start coding. When you combine that with ABP’s extensibility and strong foundation, you get a framework that not only accelerates development but also encourages you to do things the right way. For experienced engineers and newcomers alike, that can indeed feel a bit like magic. But now that we’ve uncovered the “magic tricks” ABP is doing under the hood, you can fully appreciate how it all comes together – and decide if this framework’s approach aligns with your goals of building applications faster, smarter, and with fewer headaches. Chances are, once you experience the productivity boost of ABP, you won’t want to go back. Happy coding! |
||||
{kind=link}
|
After Width: | Height: | Size: 77 KiB |
{kind=link}
|
After Width: | Height: | Size: 504 KiB |
@ -0,0 +1,98 @@ |
|||||
|
# **Return Code vs Exceptions: Which One is Better?** |
||||
|
|
||||
|
Alright, so this debate pops up every few months on dev subreddits and forums |
||||
|
|
||||
|
> *Should you use return codes or exceptions for error handling?* |
||||
|
|
||||
|
And honestly, there’s no %100 right answer here! Both have pros/cons, and depending on the language or context, one might make more sense than the other. Let’s see... |
||||
|
|
||||
|
------ |
||||
|
|
||||
|
## 1. Return Codes --- Said to be "Old School Way" --- |
||||
|
|
||||
|
Return codes (like `0` for success, `-1` for failure, etc.) are the OG method. You mostly see them everywhere in C and C++. |
||||
|
They’re super explicit, the function literally *returns* the result of the operation. |
||||
|
|
||||
|
### ➕ Advantages of returning codes: |
||||
|
|
||||
|
- You *always* know when something went wrong |
||||
|
- No hidden control flow — what you see is what you get |
||||
|
- Usually faster (no stack unwinding, no exception overhead) |
||||
|
- Easy to use in systems programming, embedded stuff, or performance-critical code |
||||
|
|
||||
|
### ➖ Disadvantages of returning codes: |
||||
|
|
||||
|
- It’s easy to forget to check the return value (and boom, silent failure 😬) |
||||
|
- Makes code noisy... Everry function call followed by `if (result != SUCCESS)` gets annoying |
||||
|
- No stack trace or context unless you manually build one |
||||
|
|
||||
|
**For example:** |
||||
|
|
||||
|
```csharp |
||||
|
try |
||||
|
{ |
||||
|
await SendEmailAsync(); |
||||
|
} |
||||
|
catch (Exception e) |
||||
|
{ |
||||
|
Log.Exception(e.ToString()); |
||||
|
return -1; |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
Looks fine… until you forget one of those `if` conditions somewhere. |
||||
|
|
||||
|
------ |
||||
|
|
||||
|
## 2. Exceptions --- The Fancy & Modern Way --- |
||||
|
|
||||
|
Exceptions came in later, mostly with higher-level languages like Java, C#, and Python. |
||||
|
The idea is that you *throw* an error and handle it *somewhere else*. |
||||
|
|
||||
|
### ➕ Advantages of throwing exceptions: |
||||
|
|
||||
|
- Cleaner code... You can focus on the happy path and handle errors separately |
||||
|
- Can carry detailed info (stack traces, messages, inner exceptions...) |
||||
|
- Easier to handle complex error propagation |
||||
|
|
||||
|
### ➖ Disadvantages of throwing exceptions: |
||||
|
|
||||
|
- Hidden control flow — you don’t always see what might throw |
||||
|
- Performance hit (esp. in tight loops or low-level systems) |
||||
|
- Overused in some codebases (“everything throws everything”) |
||||
|
|
||||
|
**Example:** |
||||
|
|
||||
|
```csharp |
||||
|
try |
||||
|
{ |
||||
|
await SendEmailAsync(); |
||||
|
} |
||||
|
catch (Exception e) |
||||
|
{ |
||||
|
Log.Exception(e.ToString()); |
||||
|
throw e; |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
Way cleaner, but if `SendEmailAsync()` is deep in your call stack and it fails, it can be tricky to know exactly what went wrong unless you log properly. |
||||
|
|
||||
|
------ |
||||
|
|
||||
|
### And Which One’s Better? ⚖️ |
||||
|
|
||||
|
Depends on what you’re building. |
||||
|
|
||||
|
- **Low-level systems, drivers, real-time stuff 👉 Return codes.** Performance and control matter more. |
||||
|
- **Application-level, business logic, or high-level APIs 👉 Exceptions.** Cleaner and easier to maintain. |
||||
|
|
||||
|
And honestly, mixing both sometimes makes sense. |
||||
|
For example, you can use return codes internally and exceptions at the boundary of your API to surface meaningful errors to the user. |
||||
|
|
||||
|
------ |
||||
|
|
||||
|
### Conclusion |
||||
|
|
||||
|
Return codes = simple, explicit, but messy.t |
||||
|
Exceptions = clean, powerful, but can bite you. |
||||
|
Use what fits your project and your team’s sanity level 😅. |
||||
{kind=link}
|
After Width: | Height: | Size: 5.1 KiB |
{kind=link}
|
After Width: | Height: | Size: 52 KiB |
{kind=link}
|
After Width: | Height: | Size: 107 KiB |
@ -0,0 +1,112 @@ |
|||||
|
# UI & UX Trends That Will Shape 2026 |
||||
|
|
||||
|
Cinematic, gamified, high-wow-factor websites with scroll-to-play videos or scroll-to-tell stories are wonderful to experience, but you won't find these trends in this article. If you're interested in design trends directly related to the software world, such as **performance**, **accessibility**, **understandability**, and **efficiency**, grab a cup of coffee and enjoy. |
||||
|
|
||||
|
As we approach the end of 2025, I'd like to share with you the most important user interface and user experience design trends that have become more of a **toolkit** than a trend, and that continue to evolve and become a part of our lives. I predict we'll see a lot of them in 2026\. |
||||
|
|
||||
|
## 1\. Simplicity and Speed |
||||
|
|
||||
|
Designing understandable and readable applications is becoming far more important than designing in line with trends and fashion. In the software and business world, preferences are shifting more and more toward the **right design** over the cool design. As designers developing a product whose direct target audience is software developers, we design our products for the designers' enjoyment, but for the **end user's ease of use**. |
||||
|
|
||||
|
Users no longer care so much about the flashiness of a website. True converts are primarily interested in your product, service, or content. What truly matters to them is how easily and quickly they can access the information they're looking for. |
||||
|
|
||||
|
More users, more sales, better promotion, and a higher conversion rate... The elements that serve these goals are optimized solutions and thoughtful details in our designs, more than visual displays. |
||||
|
|
||||
|
If the "loading" icon appears too often on your digital product, you might not be doing it right. If you fail to optimize speed, the temporary effect of visual displays won't be enough to convert potential users into customers. Remember, the moment people start waiting, you've lost at least half of them. |
||||
|
|
||||
|
## 2\. Dark Mode \- Still, and Forever |
||||
|
 |
||||
|
|
||||
|
Dark Mode is no longer an option; it's a **standard**. It's become a necessity, not a choice, especially for users who spend hours staring at screens and are accustomed to dark themes in code editors and terminals. However, the approach to dark mode isn't simply about inverting colors; it's much deeper than that. The key is managing contrast and depth. |
||||
|
|
||||
|
The layer hierarchy established in a light-colored design doesn't lose its impact when switched to dark mode. The colors, shadows, highlights, and contrasting elements used to create an **easily perceivable hierarchy** should be carefully considered for each mode. Our [LeptonX theme](https://leptontheme.com/)'s Light, Dark, Semi-dark, and System modes offer valuable insights you might want to explore. |
||||
|
|
||||
|
You might also want to take a look at the dark and light modes we designed with these elements in mind in [ABP Studio](https://abp.io/get-started) and the [ABP.io Documents page](https://abp.io/docs/latest/). |
||||
|
|
||||
|
## 3\. Bento Grid \- A Timeless Trend |
||||
|
 |
||||
|
|
||||
|
People don't read your website; they **scan** it. |
||||
|
|
||||
|
Bento Grid, an indispensable trend for designers looking to manage their attention, looks set to remain a staple in 2026, just as it was in 2025\. No designer should ignore the fact that many tech giants, especially Apple and Samsung, are still using bento grids on their websites. The bento grid appears not only on websites but also in operating systems, VR headset interfaces, game console interfaces, and game designs. |
||||
|
|
||||
|
The golden rule is **contrast** and **balance**. |
||||
|
|
||||
|
The attractiveness and effectiveness of bento designs depend on certain factors you should consider when implementing them. If you ignore these rules, even with a proven method like bento, you can still alienate users. |
||||
|
|
||||
|
The bento grid is one of the best ways to display different types of content inclusively. When used correctly, it's also a great way to manipulate reading order, guiding the user's eye. Improper contrast and hierarchy can also create a negative experience. Designers should use this to guide the reader's eye: "Read here first, then read here." |
||||
|
|
||||
|
When creating a bento, you inherently have to sacrifice some of your "whitespace." This design has many elements for the user to focus on, and it actually strays from our first point, "Simplicity". Bento design, whose boundaries are drawn from the outset and independent of content, requires care not to include more or less than what is necessary. Too much content makes it boring; too little content makes it very close to meaningless. |
||||
|
|
||||
|
Bento grids should aim for a balanced design by using both simple text and sophisticated visuals. This visual can be an illustration, a video that starts playing when hovered over, a static image, or a large title. Only one or two cards on the screen at a time should have attention. |
||||
|
|
||||
|
## 4\. Larger Fonts, High Readability |
||||
|
 |
||||
|
|
||||
|
Large fonts have been a trend for several years, and it seems web designers are becoming more and more bold. The increasing preference for larger fonts every year is a sign that this trend will continue into 2026\. This trend is about more than just using large font sizes in headlines. |
||||
|
|
||||
|
Creating a cohesive typographic scale and proper line height and letter spacing are critical elements to consider when creating this trend. As the font size increases, line height should decrease, and the space between letters should be narrower. |
||||
|
|
||||
|
The browser default font size, which we used to see in body text and paragraphs and has now become standard, is 16 pixels. In the last few years, we've started seeing body font sizes of 17 or 18 pixels more frequently. The increasing importance of readability every year makes this more common. Font sizes in rem values, rather than px, provide the most efficient results. |
||||
|
|
||||
|
## 5\. Micro Animations |
||||
|
|
||||
|
Unless you're a web design agency designing a website to impress potential clients, you should avoid excessive changes, including excessive image changes during scrolling, and scroll direction changes. There's still room for oversized images and scroll animations. But be sure to create the visuals yourself. |
||||
|
|
||||
|
The trend I'm talking about here is **micro animations**, not macro ones. Small movements, not large ones. |
||||
|
|
||||
|
The animation approach of 2025 is **functional** and **performance-sensitive**. |
||||
|
|
||||
|
Microanimations exist to provide immediate feedback to the user. Instant feedback, like a button's shadow increasing when hovered over, a button's slight collapse when clicked, or a "Save" icon changing to a "Confirm" icon when saving data, keeps your designs alive. |
||||
|
|
||||
|
We see the real impact of the micro-animation trend in static, non-action visuals. The use of non-button elements in your designs, accentuated by micro-movements such as scrolling or hovering, seems poised to continue to create macro effects in 2026\. |
||||
|
|
||||
|
## 6\. Real Images and Human-like Touches |
||||
|
|
||||
|
People quickly spot a fake. It's very difficult to convince a user who visits your website for the first time and doesn't trust you. **First impressions** matter. |
||||
|
|
||||
|
Real photographs, actual product screenshots, and brand-specific illustrations will continue to be among the elements we want to see in **trust-focused** designs in 2026\. |
||||
|
|
||||
|
In addition to flawless work done by AI, vivid, real-life visuals, accompanied by deliberate imperfections, hand-drawn details, or designed products that convey the message, "A human made this site\!", will continue to feel warmer and more welcoming. |
||||
|
|
||||
|
The human touch is evident not only in the visuals but also in your **content and text**. |
||||
|
|
||||
|
In 2026, you'll need more **human-like touches** that will make your design stand out among the thousands of similar websites rapidly generated by AI. |
||||
|
|
||||
|
## 7\. Accessibility \- No Longer an Option, But a Legal and Ethical Obligation |
||||
|
|
||||
|
Accessibility, once considered a nice-to-do thing in recent years, is now becoming a **necessity** in 2026 and beyond. Global regulations like the European Accessibility Act require all digital products to comply with WCAG standards. |
||||
|
|
||||
|
All design and software improvements you make to ensure end users can fully perform their tasks in your products, regardless of their temporary or permanent disabilities, should be viewed as ethical and commercial requirements, not as a requirement to comply with these standards. |
||||
|
|
||||
|
The foundation of accessibility in design is to use semantic HTML for screen readers, provide full keyboard control of all interactive elements, and clearly communicate the roles of complex components to the development team. |
||||
|
|
||||
|
## 8\. Intentional Friction |
||||
|
|
||||
|
Steve Krug, the father of UX design, started the trend of designing everything at a hyper-usable level with his book "Don't Make Me Think." As web designers, we've embraced this idea so much that all we care about is getting the user to their destination in the shortest possible scenario and as quickly as possible. This has required so many understandability measures that, after a while, it's starting to feel like fooling the user. |
||||
|
|
||||
|
In recent years, designers have started looking for ways to make things a little more challenging, rather than just getting the user to the result. |
||||
|
|
||||
|
When the end user visits your website, tries to understand exactly what it is at first glance, struggles a bit, and, after a little effort, becomes familiar with how your world works, they'll be more inclined to consider themselves a part of it. |
||||
|
|
||||
|
This has nothing to do with anti-usability. This philosophy is called Intentional Friction. |
||||
|
|
||||
|
This isn't a flaw; it's the pinnacle of error prevention. It's a step to prevent errors from occurring on autopilot and respects the user's ability to understand complex systems. Examples include reviewing the order summary or manually typing the project name when deleting a project on GitHub. |
||||
|
|
||||
|
## Bonus: Where Does Artificial Intelligence Fit In? |
||||
|
|
||||
|
Artificial intelligence will be an infrastructure in 2026, not a trend. |
||||
|
|
||||
|
As designers, we should leverage AI not to paint us a picture, but to make workflows more intelligent. In my opinion, this is the best use case for AI. |
||||
|
|
||||
|
AI can learn user behavior and adapt the interface accordingly. Real-time A/B testing can save us time by conducting a real-time content review. The ability to actively use AI in any area that allows you to accelerate your progress will take you a step further in your career. |
||||
|
|
||||
|
Since your users are always human, **don't be too eager** to incorporate AI-generated visuals into your design. Unless you're creating and selling a ready-made theme, you should **avoid** AI-generated visuals, random bento grids, and randomly generated content. |
||||
|
|
||||
|
You should definitely incorporate AI into your work for new content, new ideas, personal and professional development, and insights that will take your design a step further. But just as you don't design your website for designers to like, the same applies to AI. Humans, not robots, will experience your website. **AI-assisted**, not AI-generated, designs with a human touch are the trend I most expect seeing in 2026\. |
||||
|
|
||||
|
## Conclusion |
||||
|
|
||||
|
In the end, it's all fundamentally about respect for the user and their time. In 2026, our success as designers and developers will be measured not by how "cool" we are, but by how "efficient" and "reliable" a world we build for our users. |
||||
|
|
||||
|
Thank you for your time. |
||||
{kind=link}
|
After Width: | Height: | Size: 56 KiB |
{kind=link}
|
After Width: | Height: | Size: 54 KiB |
{kind=link}
|
After Width: | Height: | Size: 26 KiB |
{kind=link}
|
After Width: | Height: | Size: 10 KiB |
{kind=link}
|
After Width: | Height: | Size: 37 KiB |
@ -0,0 +1,592 @@ |
|||||
|
# What is That Domain Service in DDD for .NET Developers? |
||||
|
|
||||
|
When you start applying **Domain-Driven Design (DDD)** in your .NET projects, you'll quickly meet some core building blocks: **Entities**, **Value Objects**, **Aggregates**, and finally… **Domain Services**. |
||||
|
|
||||
|
But what exactly *is* a Domain Service, and when should you use one? |
||||
|
|
||||
|
Let's break it down with practical examples and ABP Framework implementation patterns. |
||||
|
|
||||
|
--- |
||||
|
|
||||
|
 |
||||
|
|
||||
|
## The Core Idea of Domain Services |
||||
|
|
||||
|
A **Domain Service** represents **a domain concept that doesn't naturally belong to a single Entity or Value Object**, but still belongs to the **domain layer** - *not* to the application or infrastructure. |
||||
|
|
||||
|
In short: |
||||
|
|
||||
|
> If your business logic doesn't fit into a single Entity, but still expresses a business rule, that's a good candidate for a Domain Service. |
||||
|
|
||||
|
|
||||
|
|
||||
|
--- |
||||
|
|
||||
|
## Example: Money Transfer Between Accounts |
||||
|
|
||||
|
Imagine a simple **banking system** where you can transfer money between accounts. |
||||
|
|
||||
|
```csharp |
||||
|
public class Account : AggregateRoot<Guid> |
||||
|
{ |
||||
|
public decimal Balance { get; private set; } |
||||
|
|
||||
|
// Domain model should be created in a valid state. |
||||
|
public Account(decimal openingBalance = 0m) |
||||
|
{ |
||||
|
if (openingBalance < 0) |
||||
|
throw new BusinessException("Opening balance cannot be negative."); |
||||
|
Balance = openingBalance; |
||||
|
} |
||||
|
|
||||
|
public void Withdraw(decimal amount) |
||||
|
{ |
||||
|
if (amount <= 0) |
||||
|
throw new BusinessException("Withdrawal amount must be positive."); |
||||
|
if (Balance < amount) |
||||
|
throw new BusinessException("Insufficient balance."); |
||||
|
Balance -= amount; |
||||
|
} |
||||
|
|
||||
|
public void Deposit(decimal amount) |
||||
|
{ |
||||
|
if (amount <= 0) |
||||
|
throw new BusinessException("Deposit amount must be positive."); |
||||
|
Balance += amount; |
||||
|
} |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
> In a richer domain you might introduce a `Money` value object (amount + currency + rounding rules) instead of a raw `decimal` for stronger invariants. |
||||
|
|
||||
|
--- |
||||
|
|
||||
|
## Implementing a Domain Service |
||||
|
|
||||
|
 |
||||
|
|
||||
|
```csharp |
||||
|
public class MoneyTransferManager : DomainService |
||||
|
{ |
||||
|
public void Transfer(Account from, Account to, decimal amount) |
||||
|
{ |
||||
|
if (from is null) throw new ArgumentNullException(nameof(from)); |
||||
|
if (to is null) throw new ArgumentNullException(nameof(to)); |
||||
|
if (ReferenceEquals(from, to)) |
||||
|
throw new BusinessException("Cannot transfer to the same account."); |
||||
|
if (amount <= 0) |
||||
|
throw new BusinessException("Transfer amount must be positive."); |
||||
|
|
||||
|
from.Withdraw(amount); |
||||
|
to.Deposit(amount); |
||||
|
} |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
> **Naming Convention**: ABP suggests using the `Manager` or `Service` suffix for domain services. We typically use `Manager` suffix (e.g., `IssueManager`, `OrderManager`). |
||||
|
|
||||
|
> **Note**: This is a synchronous domain operation. The domain service focuses purely on business rules without infrastructure concerns like database access or event publishing. For cross-cutting concerns, use Application Service layer or domain events. |
||||
|
|
||||
|
--- |
||||
|
|
||||
|
## Domain Service vs. Application Service |
||||
|
|
||||
|
Here's a quick comparison: |
||||
|
|
||||
|
 |
||||
|
|
||||
|
| Layer | Responsibility | Example | |
||||
|
| ----------------------- | -------------------------------------------------------------------------------- | ---------------------------- | |
||||
|
| **Domain Service** | Pure business rule spanning entities/aggregates | `MoneyTransferManager` | |
||||
|
| **Application Service** | Orchestrates use cases, handles repositories, transactions, external systems | `BankAppService` | |
||||
|
|
||||
|
--- |
||||
|
|
||||
|
## The Application Service Layer |
||||
|
|
||||
|
An **Application Service** orchestrates the domain logic and handles infrastructure concerns: |
||||
|
|
||||
|
 |
||||
|
|
||||
|
```csharp |
||||
|
public class BankAppService : ApplicationService |
||||
|
{ |
||||
|
private readonly IRepository<Account, Guid> _accountRepository; |
||||
|
private readonly MoneyTransferManager _moneyTransferManager; |
||||
|
|
||||
|
public BankAppService( |
||||
|
IRepository<Account, Guid> accountRepository, |
||||
|
MoneyTransferManager moneyTransferManager) |
||||
|
{ |
||||
|
_accountRepository = accountRepository; |
||||
|
_moneyTransferManager = moneyTransferManager; |
||||
|
} |
||||
|
|
||||
|
public async Task TransferAsync(Guid fromId, Guid toId, decimal amount) |
||||
|
{ |
||||
|
var from = await _accountRepository.GetAsync(fromId); |
||||
|
var to = await _accountRepository.GetAsync(toId); |
||||
|
|
||||
|
_moneyTransferManager.Transfer(from, to, amount); |
||||
|
|
||||
|
await _accountRepository.UpdateAsync(from); |
||||
|
await _accountRepository.UpdateAsync(to); |
||||
|
} |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
> **Note**: Domain services are automatically registered to Dependency Injection with a **Transient** lifetime when inheriting from `DomainService`. |
||||
|
|
||||
|
--- |
||||
|
|
||||
|
## Benefits of ABP's DomainService Base Class |
||||
|
|
||||
|
The `DomainService` base class gives you access to: |
||||
|
|
||||
|
- **Localization** (`IStringLocalizer L`) - Multi-language support for error messages |
||||
|
- **Logging** (`ILogger Logger`) - Built-in logger for tracking operations |
||||
|
- **Local Event Bus** (`ILocalEventBus LocalEventBus`) - Publish local domain events |
||||
|
- **Distributed Event Bus** (`IDistributedEventBus DistributedEventBus`) - Publish distributed events |
||||
|
- **GUID Generator** (`IGuidGenerator GuidGenerator`) - Sequential GUID generation for better database performance |
||||
|
- **Clock** (`IClock Clock`) - Abstraction for date/time operations |
||||
|
|
||||
|
### Example with ABP Features |
||||
|
|
||||
|
> **Important**: While domain services *can* publish domain events using the event bus, they should remain focused on business rules. Consider whether event publishing belongs in the domain service or the application service based on your consistency boundaries. |
||||
|
|
||||
|
```csharp |
||||
|
public class MoneyTransferredEvent |
||||
|
{ |
||||
|
public Guid FromAccountId { get; set; } |
||||
|
public Guid ToAccountId { get; set; } |
||||
|
public decimal Amount { get; set; } |
||||
|
} |
||||
|
|
||||
|
public class MoneyTransferManager : DomainService |
||||
|
{ |
||||
|
public async Task TransferAsync(Account from, Account to, decimal amount) |
||||
|
{ |
||||
|
if (from is null) throw new ArgumentNullException(nameof(from)); |
||||
|
if (to is null) throw new ArgumentNullException(nameof(to)); |
||||
|
if (ReferenceEquals(from, to)) |
||||
|
throw new BusinessException(L["SameAccountTransferNotAllowed"]); |
||||
|
if (amount <= 0) |
||||
|
throw new BusinessException(L["InvalidTransferAmount"]); |
||||
|
|
||||
|
// Log the operation |
||||
|
Logger.LogInformation( |
||||
|
"Transferring {Amount} from {From} to {To}", amount, from.Id, to.Id); |
||||
|
|
||||
|
from.Withdraw(amount); |
||||
|
to.Deposit(amount); |
||||
|
|
||||
|
// Publish local event for further policies (limits, notifications, audit, etc.) |
||||
|
await LocalEventBus.PublishAsync( |
||||
|
new MoneyTransferredEvent |
||||
|
{ |
||||
|
FromAccountId = from.Id, |
||||
|
ToAccountId = to.Id, |
||||
|
Amount = amount |
||||
|
} |
||||
|
); |
||||
|
} |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
> **Local Events**: By default, event handlers are executed within the same Unit of Work. If an event handler throws an exception, the database transaction is rolled back, ensuring consistency. |
||||
|
|
||||
|
--- |
||||
|
|
||||
|
## Best Practices |
||||
|
|
||||
|
### 1. Keep Domain Services Pure and Focused on Business Rules |
||||
|
|
||||
|
Domain services should only contain business logic. They should not be responsible for application-level concerns like database transactions, authorization, or fetching entities from a repository. |
||||
|
|
||||
|
```csharp |
||||
|
// Good ✅ Pure rule: receives aggregates already loaded. |
||||
|
public class MoneyTransferManager : DomainService |
||||
|
{ |
||||
|
public void Transfer(Account from, Account to, decimal amount) |
||||
|
{ |
||||
|
// Business rules and coordination |
||||
|
from.Withdraw(amount); |
||||
|
to.Deposit(amount); |
||||
|
} |
||||
|
} |
||||
|
|
||||
|
// Bad ❌ Mixing application and domain concerns. |
||||
|
// This logic belongs in an Application Service. |
||||
|
public class MoneyTransferManager : DomainService |
||||
|
{ |
||||
|
private readonly IRepository<Account, Guid> _accountRepository; |
||||
|
|
||||
|
public MoneyTransferManager(IRepository<Account, Guid> accountRepository) |
||||
|
{ |
||||
|
_accountRepository = accountRepository; |
||||
|
} |
||||
|
|
||||
|
public async Task TransferAsync(Guid fromId, Guid toId, decimal amount) |
||||
|
{ |
||||
|
// Don't fetch entities inside a domain service. |
||||
|
var from = await _accountRepository.GetAsync(fromId); |
||||
|
var to = await _accountRepository.GetAsync(toId); |
||||
|
|
||||
|
from.Withdraw(amount); |
||||
|
to.Deposit(amount); |
||||
|
} |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
### 2. Leverage Entity Methods First |
||||
|
|
||||
|
Always prefer encapsulating business logic within an entity's methods when the logic belongs to a single aggregate. A domain service should only be used when a business rule spans multiple aggregates. |
||||
|
|
||||
|
```csharp |
||||
|
// Good ✅ - Internal state change belongs in the entity |
||||
|
public class Account : AggregateRoot<Guid> |
||||
|
{ |
||||
|
public decimal Balance { get; private set; } |
||||
|
|
||||
|
public void Withdraw(decimal amount) |
||||
|
{ |
||||
|
if (Balance < amount) |
||||
|
throw new BusinessException("Insufficient balance"); |
||||
|
Balance -= amount; |
||||
|
} |
||||
|
} |
||||
|
|
||||
|
// Use Domain Service only when logic spans multiple aggregates |
||||
|
public class MoneyTransferManager : DomainService |
||||
|
{ |
||||
|
public void Transfer(Account from, Account to, decimal amount) |
||||
|
{ |
||||
|
from.Withdraw(amount); // Delegates to entity |
||||
|
to.Deposit(amount); // Delegates to entity |
||||
|
} |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
### 3. Prefer Domain Services over Anemic Entities |
||||
|
|
||||
|
Avoid placing business logic that coordinates multiple entities directly into an application service. This leads to an "Anemic Domain Model," where entities are just data bags and the business logic is scattered in application services. |
||||
|
|
||||
|
```csharp |
||||
|
// Bad ❌ - Business logic is in the Application Service (Anemic Domain) |
||||
|
public class BankAppService : ApplicationService |
||||
|
{ |
||||
|
public async Task TransferAsync(Guid fromId, Guid toId, decimal amount) |
||||
|
{ |
||||
|
var from = await _accountRepository.GetAsync(fromId); |
||||
|
var to = await _accountRepository.GetAsync(toId); |
||||
|
|
||||
|
// This is domain logic and should be in a Domain Service |
||||
|
if (ReferenceEquals(from, to)) |
||||
|
throw new BusinessException("Cannot transfer to the same account."); |
||||
|
if (amount <= 0) |
||||
|
throw new BusinessException("Transfer amount must be positive."); |
||||
|
|
||||
|
from.Withdraw(amount); |
||||
|
to.Deposit(amount); |
||||
|
} |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
### 4. Use Meaningful Names |
||||
|
|
||||
|
ABP recommends naming domain services with a `Manager` or `Service` suffix based on the business concept they represent. |
||||
|
|
||||
|
```csharp |
||||
|
// Good ✅ |
||||
|
MoneyTransferManager |
||||
|
OrderManager |
||||
|
IssueManager |
||||
|
InventoryAllocationService |
||||
|
|
||||
|
// Bad ❌ |
||||
|
AccountHelper |
||||
|
OrderProcessor |
||||
|
``` |
||||
|
|
||||
|
--- |
||||
|
|
||||
|
## Advanced Example: Order Processing with Inventory Check |
||||
|
|
||||
|
Here's a more complex scenario showing domain service interaction with domain abstractions: |
||||
|
|
||||
|
```csharp |
||||
|
// Domain abstraction - defines contract but implementation is in infrastructure |
||||
|
public interface IInventoryChecker : IDomainService |
||||
|
{ |
||||
|
Task<bool> IsAvailableAsync(Guid productId, int quantity); |
||||
|
} |
||||
|
|
||||
|
public class OrderManager : DomainService |
||||
|
{ |
||||
|
private readonly IInventoryChecker _inventoryChecker; |
||||
|
|
||||
|
public OrderManager(IInventoryChecker inventoryChecker) |
||||
|
{ |
||||
|
_inventoryChecker = inventoryChecker; |
||||
|
} |
||||
|
|
||||
|
// Validates and coordinates order processing with inventory |
||||
|
public async Task ProcessAsync(Order order, Inventory inventory) |
||||
|
{ |
||||
|
// First pass: validate availability using domain abstraction |
||||
|
foreach (var item in order.Items) |
||||
|
{ |
||||
|
if (!await _inventoryChecker.IsAvailableAsync(item.ProductId, item.Quantity)) |
||||
|
{ |
||||
|
throw new BusinessException( |
||||
|
L["InsufficientInventory", item.ProductId]); |
||||
|
} |
||||
|
} |
||||
|
|
||||
|
// Second pass: perform reservations |
||||
|
foreach (var item in order.Items) |
||||
|
{ |
||||
|
inventory.Reserve(item.ProductId, item.Quantity); |
||||
|
} |
||||
|
|
||||
|
order.SetStatus(OrderStatus.Processing); |
||||
|
} |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
> **Domain Abstractions**: The `IInventoryChecker` interface is a domain service contract. Its implementation can be in the infrastructure layer, but the contract belongs to the domain. This keeps the domain layer independent of infrastructure details while still allowing complex validations. |
||||
|
|
||||
|
> **Caution**: Always perform validation and action atomically within a single transaction to avoid race conditions (TOCTOU - Time Of Check Time Of Use). |
||||
|
|
||||
|
> **Transaction Boundaries**: When a domain service coordinates multiple aggregates, ensure the Application Service wraps the operation in a Unit of Work to maintain consistency. ABP's `[UnitOfWork]` attribute or Application Services' built-in UoW handling ensures this automatically. |
||||
|
|
||||
|
--- |
||||
|
|
||||
|
## Common Pitfalls and How to Avoid Them |
||||
|
|
||||
|
### 1. Bloated Domain Services |
||||
|
Don't let domain services become "god objects" that do everything. Keep them focused on a single business concept. |
||||
|
|
||||
|
```csharp |
||||
|
// Bad ❌ - Too many responsibilities |
||||
|
public class AccountManager : DomainService |
||||
|
{ |
||||
|
public void Transfer(Account from, Account to, decimal amount) { } |
||||
|
public void CalculateInterest(Account account) { } |
||||
|
public void GenerateStatement(Account account) { } |
||||
|
public void ValidateAddress(Account account) { } |
||||
|
public void SendNotification(Account account) { } |
||||
|
} |
||||
|
|
||||
|
// Good ✅ - Split by business concept |
||||
|
public class MoneyTransferManager : DomainService |
||||
|
{ |
||||
|
public void Transfer(Account from, Account to, decimal amount) { } |
||||
|
} |
||||
|
|
||||
|
public class InterestCalculationManager : DomainService |
||||
|
{ |
||||
|
public void Calculate(Account account) { } |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
### 2. Circular Dependencies Between Aggregates |
||||
|
When domain services coordinate multiple aggregates, be careful about creating circular dependencies. |
||||
|
|
||||
|
```csharp |
||||
|
// Consider using Domain Events instead of direct coupling |
||||
|
public class OrderManager : DomainService |
||||
|
{ |
||||
|
public async Task ProcessAsync(Order order) |
||||
|
{ |
||||
|
order.SetStatus(OrderStatus.Processing); |
||||
|
|
||||
|
// Instead of directly modifying Customer aggregate here, |
||||
|
// publish an event that CustomerManager can handle |
||||
|
await LocalEventBus.PublishAsync(new OrderProcessedEvent |
||||
|
{ |
||||
|
OrderId = order.Id, |
||||
|
CustomerId = order.CustomerId |
||||
|
}); |
||||
|
} |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
### 3. Confusing Domain Service with Domain Event Handlers |
||||
|
Domain services orchestrate business operations. Domain event handlers react to state changes. Don't mix them. |
||||
|
|
||||
|
```csharp |
||||
|
// Domain Service - Orchestrates business logic |
||||
|
public class MoneyTransferManager : DomainService |
||||
|
{ |
||||
|
public async Task TransferAsync(Account from, Account to, decimal amount) |
||||
|
{ |
||||
|
from.Withdraw(amount); |
||||
|
to.Deposit(amount); |
||||
|
await LocalEventBus.PublishAsync( |
||||
|
new MoneyTransferredEvent |
||||
|
{ |
||||
|
FromAccountId = from.Id, |
||||
|
ToAccountId = to.Id, |
||||
|
Amount = amount |
||||
|
} |
||||
|
); |
||||
|
} |
||||
|
} |
||||
|
|
||||
|
// Domain Event Handler - Reacts to domain events |
||||
|
public class MoneyTransferredEventHandler : |
||||
|
ILocalEventHandler<MoneyTransferredEvent>, |
||||
|
ITransientDependency |
||||
|
{ |
||||
|
public async Task HandleEventAsync(MoneyTransferredEvent eventData) |
||||
|
{ |
||||
|
// Send notification, update analytics, etc. |
||||
|
} |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
--- |
||||
|
|
||||
|
## Testing Domain Services |
||||
|
|
||||
|
Domain services are easy to test because they have minimal dependencies: |
||||
|
|
||||
|
```csharp |
||||
|
public class MoneyTransferManager_Tests |
||||
|
{ |
||||
|
[Fact] |
||||
|
public void Should_Transfer_Money_Between_Accounts() |
||||
|
{ |
||||
|
// Arrange |
||||
|
var fromAccount = new Account(1000m); |
||||
|
var toAccount = new Account(500m); |
||||
|
var manager = new MoneyTransferManager(); |
||||
|
|
||||
|
// Act |
||||
|
manager.Transfer(fromAccount, toAccount, 200m); |
||||
|
|
||||
|
// Assert |
||||
|
fromAccount.Balance.ShouldBe(800m); |
||||
|
toAccount.Balance.ShouldBe(700m); |
||||
|
} |
||||
|
|
||||
|
[Fact] |
||||
|
public void Should_Throw_When_Insufficient_Balance() |
||||
|
{ |
||||
|
var fromAccount = new Account(100m); |
||||
|
var toAccount = new Account(500m); |
||||
|
var manager = new MoneyTransferManager(); |
||||
|
|
||||
|
Should.Throw<BusinessException>(() => |
||||
|
manager.Transfer(fromAccount, toAccount, 200m)); |
||||
|
} |
||||
|
|
||||
|
[Fact] |
||||
|
public void Should_Throw_When_Amount_Is_NonPositive() |
||||
|
{ |
||||
|
var fromAccount = new Account(100m); |
||||
|
var toAccount = new Account(100m); |
||||
|
var manager = new MoneyTransferManager(); |
||||
|
|
||||
|
Should.Throw<BusinessException>(() => |
||||
|
manager.Transfer(fromAccount, toAccount, 0m)); |
||||
|
Should.Throw<BusinessException>(() => |
||||
|
manager.Transfer(fromAccount, toAccount, -5m)); |
||||
|
} |
||||
|
|
||||
|
[Fact] |
||||
|
public void Should_Throw_When_Same_Account() |
||||
|
{ |
||||
|
var account = new Account(100m); |
||||
|
var manager = new MoneyTransferManager(); |
||||
|
|
||||
|
Should.Throw<BusinessException>(() => |
||||
|
manager.Transfer(account, account, 10m)); |
||||
|
} |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
### Integration Testing with ABP Test Infrastructure |
||||
|
|
||||
|
```csharp |
||||
|
public class MoneyTransferManager_IntegrationTests : BankingDomainTestBase |
||||
|
{ |
||||
|
private readonly MoneyTransferManager _transferManager; |
||||
|
private readonly IRepository<Account, Guid> _accountRepository; |
||||
|
|
||||
|
public MoneyTransferManager_IntegrationTests() |
||||
|
{ |
||||
|
_transferManager = GetRequiredService<MoneyTransferManager>(); |
||||
|
_accountRepository = GetRequiredService<IRepository<Account, Guid>>(); |
||||
|
} |
||||
|
|
||||
|
[Fact] |
||||
|
public async Task Should_Transfer_And_Persist_Changes() |
||||
|
{ |
||||
|
// Arrange |
||||
|
var fromAccount = new Account(1000m); |
||||
|
var toAccount = new Account(500m); |
||||
|
|
||||
|
await _accountRepository.InsertAsync(fromAccount); |
||||
|
await _accountRepository.InsertAsync(toAccount); |
||||
|
await UnitOfWorkManager.Current.SaveChangesAsync(); |
||||
|
|
||||
|
// Act |
||||
|
await _transferManager.TransferAsync(fromAccount, toAccount, 200m); |
||||
|
await UnitOfWorkManager.Current.SaveChangesAsync(); |
||||
|
|
||||
|
// Assert |
||||
|
var updatedFrom = await _accountRepository.GetAsync(fromAccount.Id); |
||||
|
var updatedTo = await _accountRepository.GetAsync(toAccount.Id); |
||||
|
|
||||
|
updatedFrom.Balance.ShouldBe(800m); |
||||
|
updatedTo.Balance.ShouldBe(700m); |
||||
|
} |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
--- |
||||
|
|
||||
|
## When NOT to Use a Domain Service |
||||
|
|
||||
|
Not every operation needs a domain service. Avoid over-engineering: |
||||
|
|
||||
|
1. **Simple CRUD Operations**: Use Application Services directly |
||||
|
2. **Single Aggregate Operations**: Use Entity methods |
||||
|
3. **Infrastructure Concerns**: Use Infrastructure Services |
||||
|
4. **Application Workflow**: Use Application Services |
||||
|
|
||||
|
```csharp |
||||
|
// Don't create a domain service for this ❌ |
||||
|
public class AccountBalanceReader : DomainService |
||||
|
{ |
||||
|
public decimal GetBalance(Account account) => account.Balance; |
||||
|
} |
||||
|
|
||||
|
// Just use the property directly ✅ |
||||
|
var balance = account.Balance; |
||||
|
``` |
||||
|
|
||||
|
--- |
||||
|
|
||||
|
## Summary |
||||
|
- **Domain Services** are domain-level, not application-level |
||||
|
- They encapsulate **business logic that doesn't belong to a single entity** |
||||
|
- They keep your **entities clean** and **business logic consistent** |
||||
|
- In ABP, inherit from `DomainService` to get built-in features |
||||
|
- Keep them **focused**, **pure**, and **testable** |
||||
|
|
||||
|
--- |
||||
|
|
||||
|
## Final Thoughts |
||||
|
|
||||
|
Next time you're writing a business rule that doesn't clearly belong to an entity, ask yourself: |
||||
|
|
||||
|
> "Is this a Domain Service?" |
||||
|
|
||||
|
If it's pure domain logic that coordinates multiple entities or implements a business rule, **put it in the domain layer** - your future self (and your team) will thank you. |
||||
|
|
||||
|
Domain Services are a powerful tool in your DDD toolkit. Use them wisely to keep your domain model clean, expressive, and maintainable. |
||||
|
|
||||
|
--- |
||||
@ -0,0 +1 @@ |
|||||
|
Learn what Domain Services are in Domain-Driven Design and when to use them in .NET projects. This practical guide covers the difference between Domain and Application Services, features real-world examples including money transfers and order processing, and shows how ABP Framework's DomainService base class simplifies implementation with built-in localization, logging, and event publishing. |
||||
@ -0,0 +1,156 @@ |
|||||
|
# Announcing Server-Side Rendering (SSR) Support for ABP Framework Angular Applications |
||||
|
|
||||
|
We are pleased to announce that **Server-Side Rendering (SSR)** has become available for ABP Framework Angular applications! This highly requested feature brings major gains in performance, SEO, and user experience to your Angular applications based on ABP Framework. |
||||
|
|
||||
|
## What is Server-Side Rendering (SSR)? |
||||
|
|
||||
|
Server-Side Rendering refers to an approach which renders your Angular application on the server as opposed to the browser. The server creates the complete HTML for a page and sends it to the client, which can then show the page to the user. This poses many advantages over traditional client-side rendering. |
||||
|
|
||||
|
## Why SSR Matters for ABP Angular Applications |
||||
|
|
||||
|
### Improved Performance |
||||
|
- **Quicker visualization of the first contentful paint (FCP)**: Because prerendered HTML is sent over from the server, users will see content quicker. |
||||
|
- **Better perceived performance**: Even on slower devices, the page will be displaying something sooner. |
||||
|
- **Less JavaScript parsing time**: For example, the initial page load will not require parsing and executing a large bundle of JavaScript. |
||||
|
|
||||
|
### Enhanced SEO |
||||
|
- **Improved indexing by search engines**: Search engine bots are able to crawl and index your content quicker. |
||||
|
- **Improved rankings in search**: The quicker the content loads and the easier it is to access, the better your SEO score. |
||||
|
- **Preview when sharing on social channels**: Rich previews with the appropriate meta tags are generated when sharing links on social platforms. |
||||
|
|
||||
|
### Better User Experience |
||||
|
- **Support for low bandwidth**: Users with slower Internet connections will have a better experience |
||||
|
- **Progressive enhancement**: Users can start accessing the content before JavaScript has loaded |
||||
|
- **Better accessibility**: Screen readers and other assistive technologies can access the content immediately |
||||
|
|
||||
|
## Getting Started with SSR |
||||
|
|
||||
|
### Adding SSR to an Existing Project |
||||
|
|
||||
|
You can easily add SSR support to your existing ABP Angular application using the Angular CLI with ABP schematics: |
||||
|
|
||||
|
> Adds SSR configuration to your project |
||||
|
```bash |
||||
|
ng generate @abp/ng.schematics:ssr-add |
||||
|
``` |
||||
|
> Short form |
||||
|
```bash |
||||
|
ng g @abp/ng.schematics:ssr-add |
||||
|
``` |
||||
|
If you have multiple projects in your workspace, you can specify which project to add SSR to: |
||||
|
|
||||
|
```bash |
||||
|
ng g @abp/ng.schematics:ssr-add --project=my-project |
||||
|
``` |
||||
|
|
||||
|
If you want to skip the automatic installation of dependencies: |
||||
|
|
||||
|
```bash |
||||
|
ng g @abp/ng.schematics:ssr-add --skip-install |
||||
|
``` |
||||
|
|
||||
|
## What Gets Configured |
||||
|
|
||||
|
When you add SSR to your ABP Angular project, the schematic automatically: |
||||
|
|
||||
|
1. **Installs necessary dependencies**: Adds `@angular/ssr` and related packages |
||||
|
2. **Creates Server Configuration**: Creates `server.ts` and related files |
||||
|
3. **Updates Project Structure**: |
||||
|
- Creates `main.server.ts` to bootstrap the server |
||||
|
- Adds `app.config.server.ts` for standalone apps (or `app.module.server.ts` for NgModule apps) |
||||
|
- Configures server routes in `app.routes.server.ts` |
||||
|
4. **Updates Build Configuration**: updates `angular.json` to include: |
||||
|
- a `serve-ssr` target for local SSR development |
||||
|
- a `prerender` target for static site generation |
||||
|
- Proper output paths for browser and server bundles |
||||
|
|
||||
|
## Supported Configurations |
||||
|
|
||||
|
The ABP SSR schematic supports both modern and legacy Angular build configurations: |
||||
|
|
||||
|
### Application Builder (Suggested) |
||||
|
- The new `@angular-devkit/build-angular:application` builder |
||||
|
- Optimized for Angular 17+ apps |
||||
|
- Enhanced performance and smaller bundle sizes |
||||
|
|
||||
|
### Server Builder (Legacy) |
||||
|
- The original `@angular-devkit/build-angular:server` builder |
||||
|
- Designed for legacy Angular applications |
||||
|
- Compatible with legacy applications |
||||
|
|
||||
|
## Running Your SSR Application |
||||
|
|
||||
|
After adding SSR to your project, you can run your application in SSR mode: |
||||
|
|
||||
|
```bash |
||||
|
# Development mode with SSR |
||||
|
ng serve |
||||
|
|
||||
|
# Or specifically target SSR development server |
||||
|
npm run serve:ssr |
||||
|
|
||||
|
# Build for production |
||||
|
npm run build:ssr |
||||
|
|
||||
|
# Preview production build |
||||
|
npm run serve:ssr:production |
||||
|
``` |
||||
|
|
||||
|
## Important Considerations |
||||
|
|
||||
|
### Browser-Only APIs |
||||
|
Some browser APIs are not available on the server. Use platform checks to conditionally execute code: |
||||
|
|
||||
|
```typescript |
||||
|
import { isPlatformBrowser } from '@angular/common'; |
||||
|
import { PLATFORM_ID, inject } from '@angular/core'; |
||||
|
|
||||
|
export class MyComponent { |
||||
|
private platformId = inject(PLATFORM_ID); |
||||
|
|
||||
|
ngOnInit() { |
||||
|
if (isPlatformBrowser(this.platformId)) { |
||||
|
// Code that uses browser-only APIs |
||||
|
console.log('Running in browser'); |
||||
|
localStorage.setItem('key', 'value'); |
||||
|
} |
||||
|
} |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
### Storage APIs |
||||
|
`localStorage` and `sessionStorage` are not accessible on the server. Consider using: |
||||
|
- Cookies for server-accessible data. |
||||
|
- The state transfer API for hydration. |
||||
|
- ABP's built-in storage abstractions. |
||||
|
|
||||
|
### Third-Party Libraries |
||||
|
Please ensure that any third-party libraries you use are compatible with SSR. These libraries can require: |
||||
|
- Dynamic imports for browser-only code. |
||||
|
- Platform-specific service providers. |
||||
|
- Custom Angular Universal integration. |
||||
|
|
||||
|
## ABP Framework Integration |
||||
|
|
||||
|
The SSR implementation is natively integrated with all of the ABP Framework features: |
||||
|
|
||||
|
- **Authentication & Authorization**: The OAuth/OpenID Connect flow functions seamlessly with ABP |
||||
|
- **Multi-tenancy**: Fully supports tenant resolution and switching |
||||
|
- **Localization**: Server-side rendering respects the locale |
||||
|
- **Permission Management**: Permission checks work on both server and client |
||||
|
- **Configuration**: The ABP configuration system is SSR-ready |
||||
|
## Performance Tips |
||||
|
|
||||
|
1. **Utilize State Transfer**: Send data from server to client to eliminate redundant HTTP requests |
||||
|
2. **Optimize Images**: Proper image loading strategies, such as lazy loading and responsive images. |
||||
|
3. **Cache API Responses**: At the server, implement proper caching strategies. |
||||
|
4. **Monitor Bundle Size**: Keep your server bundle optimized |
||||
|
5. **Use Prerendering**: The prerender target should be used for static content. |
||||
|
|
||||
|
## Conclusion |
||||
|
|
||||
|
Server-side rendering can be a very effective feature in improving your ABP Angular application's performance, SEO, and user experience. Our new SSR schematic will make it easier than ever to add SSR to your project. |
||||
|
|
||||
|
Try it today and let us know what you think! |
||||
|
|
||||
|
--- |
||||
{kind=link}
|
After Width: | Height: | Size: 72 KiB |
{kind=link}
|
After Width: | Height: | Size: 4.6 KiB |
@ -0,0 +1,354 @@ |
|||||
|
# Building an API Key Management System with ABP Framework |
||||
|
|
||||
|
API keys are one of the most common authentication methods for APIs, especially for machine-to-machine communication. In this article, I'll explain what API key authentication is, when to use it, and how to implement a complete API key management system using ABP Framework. |
||||
|
|
||||
|
## What is API Key Authentication? |
||||
|
|
||||
|
An API key is a unique identifier used to authenticate requests to an API. Unlike user credentials (username/password) or OAuth tokens, API keys are designed for: |
||||
|
|
||||
|
- **Programmatic access** - Scripts, CLI tools, and automated processes |
||||
|
- **Service-to-service communication** - Microservices authenticating with each other |
||||
|
- **Third-party integrations** - External systems accessing your API |
||||
|
- **IoT devices** - Embedded systems with limited authentication capabilities |
||||
|
- **Mobile/Desktop apps** - Native applications that need persistent authentication |
||||
|
|
||||
|
## Why Use API Keys? |
||||
|
|
||||
|
While modern authentication methods like OAuth2 and JWT are excellent for user authentication, API keys offer distinct advantages in certain scenarios: |
||||
|
|
||||
|
**Simplicity**: No complex OAuth flows or token refresh mechanisms. Just include the key in your request header. |
||||
|
|
||||
|
**Long-lived**: Unlike JWT tokens that expire in minutes/hours, API keys can remain valid for months or years, making them ideal for automated systems. |
||||
|
|
||||
|
**Revocable**: You can instantly revoke a compromised key without affecting user credentials. |
||||
|
|
||||
|
**Granular Control**: Different keys for different purposes (read-only, admin, specific services). |
||||
|
|
||||
|
## Real-World Use Cases |
||||
|
|
||||
|
Here are some practical scenarios where API key authentication shines: |
||||
|
|
||||
|
### 1. Mobile Applications |
||||
|
Your mobile app needs to call your backend APIs. Instead of storing user credentials or managing token refresh flows, use an API key. |
||||
|
|
||||
|
```csharp |
||||
|
// Mobile app configuration |
||||
|
var apiClient = new ApiClient("https://api.yourapp.com"); |
||||
|
apiClient.SetApiKey("sk_mobile_prod_abc123..."); |
||||
|
``` |
||||
|
|
||||
|
### 2. Microservice Communication |
||||
|
Service A needs to call Service B's protected endpoints. |
||||
|
|
||||
|
```csharp |
||||
|
// Order Service calling Inventory Service |
||||
|
var request = new HttpRequestMessage(HttpMethod.Get, "https://inventory-service/api/products"); |
||||
|
request.Headers.Add("X-Api-Key", _configuration["InventoryService:ApiKey"]); |
||||
|
``` |
||||
|
|
||||
|
### 3. Third-Party Integrations |
||||
|
You're providing APIs to external partners or customers. |
||||
|
|
||||
|
```bash |
||||
|
# Customer's integration script |
||||
|
curl -H "X-Api-Key: pk_partner_xyz789..." \ |
||||
|
https://api.yourplatform.com/api/orders |
||||
|
``` |
||||
|
|
||||
|
## Implementing API Key Management in ABP Framework |
||||
|
|
||||
|
Now let's see how to build a complete API key management system using ABP Framework. I've created an open-source implementation that you can use in your projects. |
||||
|
|
||||
|
### Project Overview |
||||
|
|
||||
|
The implementation consists of: |
||||
|
|
||||
|
- **User-based API keys** - Each key belongs to a specific user |
||||
|
- **Permission delegation** - Keys inherit user permissions with optional restrictions |
||||
|
- **Secure storage** - Keys are hashed with SHA-256 |
||||
|
- **Prefix-based lookup** - Fast key resolution with caching |
||||
|
- **Web UI** - Manage keys through a user-friendly interface |
||||
|
- **Multi-tenancy support** - Full ABP multi-tenancy compatibility |
||||
|
|
||||
|
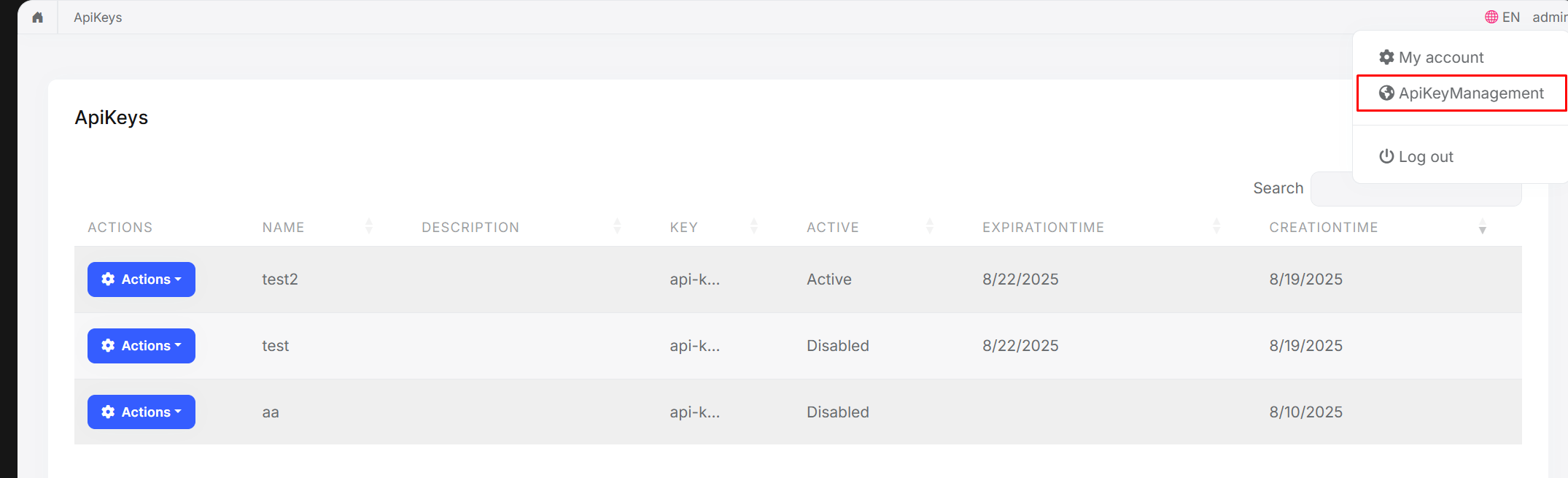 |
||||
|
|
||||
|
### Architecture Overview |
||||
|
|
||||
|
The solution follows ABP's modular architecture with four main layers: |
||||
|
|
||||
|
``` |
||||
|
┌─────────────────────────────────────────────┐ |
||||
|
│ Web Layer (UI) │ |
||||
|
│ • Razor Pages for CRUD operations │ |
||||
|
│ • JavaScript for client interactions │ |
||||
|
└─────────────────────────────────────────────┘ |
||||
|
↓ |
||||
|
┌─────────────────────────────────────────────┐ |
||||
|
│ AspNetCore Layer (Middleware) │ |
||||
|
│ • Authentication Handler │ |
||||
|
│ • API Key Resolver (Header/Query) │ |
||||
|
└─────────────────────────────────────────────┘ |
||||
|
↓ |
||||
|
┌─────────────────────────────────────────────┐ |
||||
|
│ Application Layer (Business Logic) │ |
||||
|
│ • ApiKeyAppService (CRUD operations) │ |
||||
|
│ • DTO mappings and validations │ |
||||
|
└─────────────────────────────────────────────┘ |
||||
|
↓ |
||||
|
┌─────────────────────────────────────────────┐ |
||||
|
│ Domain Layer (Core Business) │ |
||||
|
│ • ApiKey Entity & Manager │ |
||||
|
│ • IApiKeyRepository │ |
||||
|
│ • Domain services & events │ |
||||
|
└─────────────────────────────────────────────┘ |
||||
|
``` |
||||
|
|
||||
|
### Key Components |
||||
|
|
||||
|
#### 1. Domain Layer - The Core Entity |
||||
|
|
||||
|
```csharp |
||||
|
public class ApiKey : FullAuditedAggregateRoot<Guid>, IMultiTenant |
||||
|
{ |
||||
|
public virtual Guid? TenantId { get; protected set; } |
||||
|
public virtual Guid UserId { get; protected set; } |
||||
|
public virtual string Name { get; protected set; } |
||||
|
public virtual string Prefix { get; protected set; } |
||||
|
public virtual string KeyHash { get; protected set; } |
||||
|
public virtual DateTime? ExpiresAt { get; protected set; } |
||||
|
public virtual bool IsActive { get; protected set; } |
||||
|
|
||||
|
// Key format: {prefix}_{key} |
||||
|
// Only the hash is stored, never the actual key |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
**Key Design Decisions:** |
||||
|
|
||||
|
- **Prefix-based lookup**: Keys have format `prefix_actualkey`. The prefix is indexed for fast database lookups. |
||||
|
- **SHA-256 hashing**: The actual key is hashed and never stored in plain text. |
||||
|
- **User association**: Each key belongs to a user, inheriting their permissions. |
||||
|
- **Soft delete**: Deleted keys are marked as deleted but not removed from database for audit purposes. |
||||
|
|
||||
|
#### 2. Authentication Flow |
||||
|
|
||||
|
Here's how authentication works when a request arrives: |
||||
|
|
||||
|
 |
||||
|
|
||||
|
```csharp |
||||
|
// 1. Extract API key from request |
||||
|
var apiKey = httpContext.Request.Headers["X-Api-Key"].FirstOrDefault(); |
||||
|
if (string.IsNullOrEmpty(apiKey)) return AuthenticateResult.NoResult(); |
||||
|
|
||||
|
// 2. Split prefix and key |
||||
|
var parts = apiKey.Split('_', 2); |
||||
|
var prefix = parts[0]; |
||||
|
var key = parts[1]; |
||||
|
|
||||
|
// 3. Find key by prefix (cached) |
||||
|
var apiKeyEntity = await _apiKeyRepository.FindByPrefixAsync(prefix); |
||||
|
if (apiKeyEntity == null) return AuthenticateResult.Fail("Invalid API key"); |
||||
|
|
||||
|
// 4. Verify hash |
||||
|
var keyHash = HashHelper.ComputeSha256(key); |
||||
|
if (apiKeyEntity.KeyHash != keyHash) |
||||
|
return AuthenticateResult.Fail("Invalid API key"); |
||||
|
|
||||
|
// 5. Check expiration and active status |
||||
|
if (apiKeyEntity.ExpiresAt < DateTime.UtcNow || !apiKeyEntity.IsActive) |
||||
|
return AuthenticateResult.Fail("API key expired or inactive"); |
||||
|
|
||||
|
// 6. Create claims principal with user identity |
||||
|
var claims = new List<Claim> |
||||
|
{ |
||||
|
new Claim(AbpClaimTypes.UserId, apiKeyEntity.UserId.ToString()), |
||||
|
new Claim(AbpClaimTypes.TenantId, apiKeyEntity.TenantId?.ToString() ?? ""), |
||||
|
new Claim("ApiKeyId", apiKeyEntity.Id.ToString()) |
||||
|
}; |
||||
|
|
||||
|
return AuthenticateResult.Success(ticket); |
||||
|
``` |
||||
|
|
||||
|
#### 3. Creating and Managing API Keys |
||||
|
|
||||
|
**Creating a new key:** |
||||
|
|
||||
|
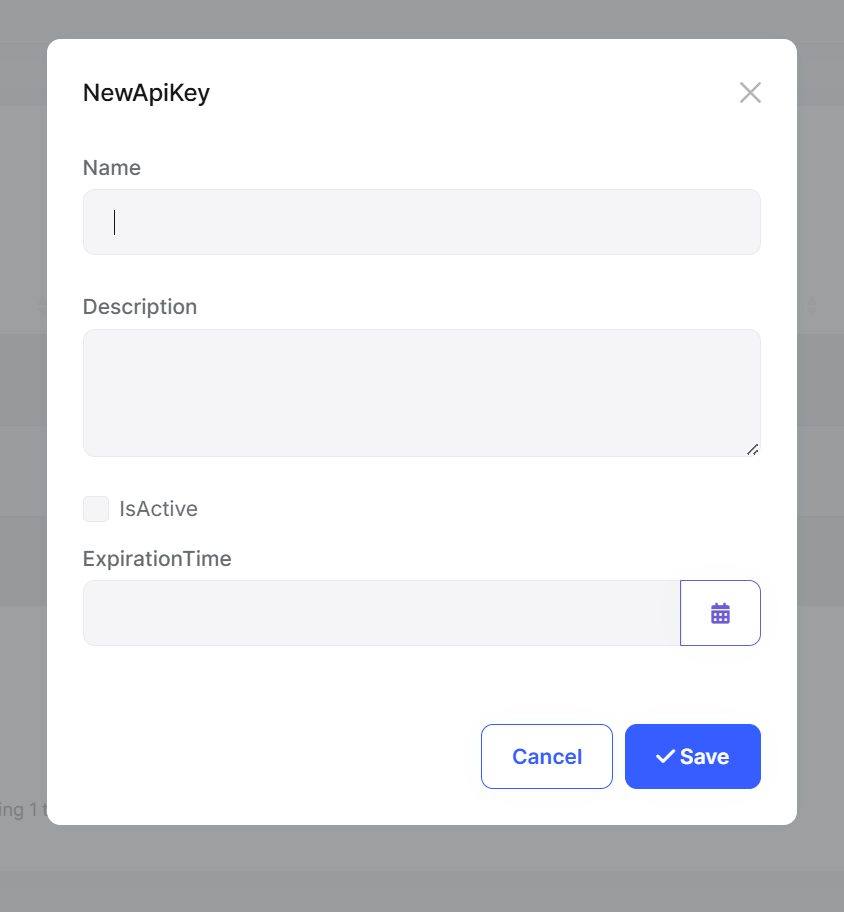 |
||||
|
|
||||
|
```csharp |
||||
|
public class ApiKeyManager : DomainService |
||||
|
{ |
||||
|
public async Task<(ApiKey, string)> CreateAsync( |
||||
|
Guid userId, |
||||
|
string name, |
||||
|
DateTime? expiresAt = null) |
||||
|
{ |
||||
|
// Generate unique prefix |
||||
|
var prefix = await GenerateUniquePrefixAsync(); |
||||
|
|
||||
|
// Generate secure random key |
||||
|
var key = GenerateSecureRandomString(32); |
||||
|
|
||||
|
// Hash the key for storage |
||||
|
var keyHash = HashHelper.ComputeSha256(key); |
||||
|
|
||||
|
var apiKey = new ApiKey( |
||||
|
GuidGenerator.Create(), |
||||
|
userId, |
||||
|
name, |
||||
|
prefix, |
||||
|
keyHash, |
||||
|
expiresAt, |
||||
|
CurrentTenant.Id |
||||
|
); |
||||
|
|
||||
|
await _apiKeyRepository.InsertAsync(apiKey); |
||||
|
|
||||
|
// Return both entity and the full key (prefix_key) |
||||
|
// This is the ONLY time the actual key is visible |
||||
|
return (apiKey, $"{prefix}_{key}"); |
||||
|
} |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
**Important**: The actual key is returned only once during creation. After that, only the hash is stored. |
||||
|
|
||||
|
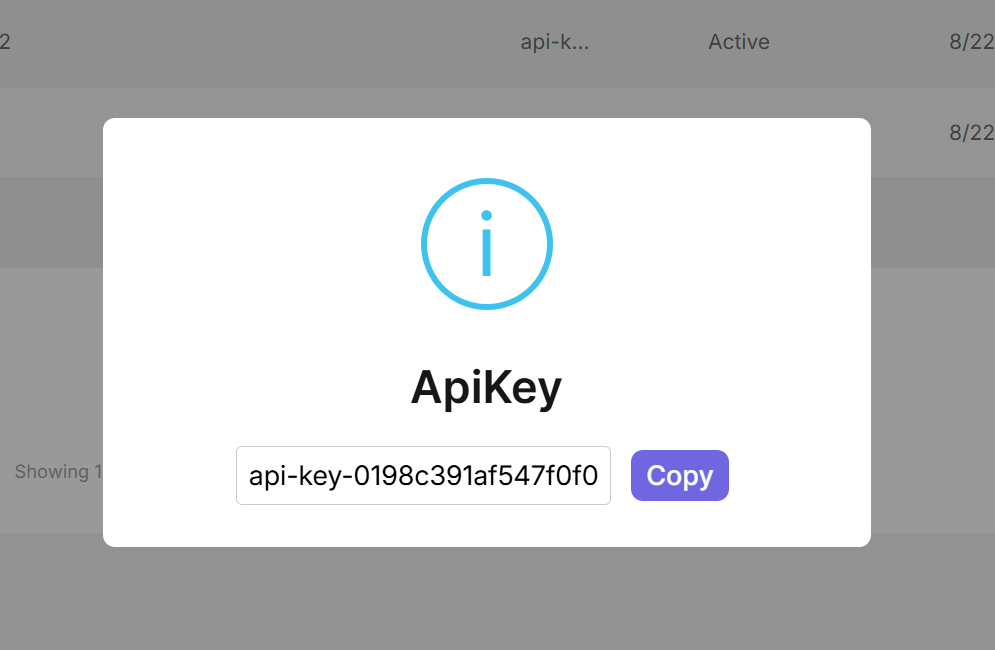 |
||||
|
|
||||
|
### Using API Keys in Your Application |
||||
|
|
||||
|
Once created, clients can use the API key to authenticate: |
||||
|
|
||||
|
**HTTP Header (Recommended):** |
||||
|
```bash |
||||
|
curl -H "X-Api-Key: sk_prod_abc123def456..." \ |
||||
|
https://api.example.com/api/products |
||||
|
``` |
||||
|
|
||||
|
**JavaScript:** |
||||
|
```javascript |
||||
|
const response = await fetch('https://api.example.com/api/products', { |
||||
|
headers: { |
||||
|
'X-Api-Key': 'sk_prod_abc123def456...' |
||||
|
} |
||||
|
}); |
||||
|
``` |
||||
|
|
||||
|
**C# HttpClient:** |
||||
|
```csharp |
||||
|
var client = new HttpClient(); |
||||
|
client.DefaultRequestHeaders.Add("X-Api-Key", "sk_prod_abc123def456..."); |
||||
|
var response = await client.GetAsync("https://api.example.com/api/products"); |
||||
|
``` |
||||
|
|
||||
|
**Python:** |
||||
|
```python |
||||
|
import requests |
||||
|
|
||||
|
headers = {'X-Api-Key': 'sk_prod_abc123def456...'} |
||||
|
response = requests.get('https://api.example.com/api/products', headers=headers) |
||||
|
``` |
||||
|
|
||||
|
### Permission Management |
||||
|
|
||||
|
API keys inherit the user's permissions, but you can further restrict them: |
||||
|
|
||||
|
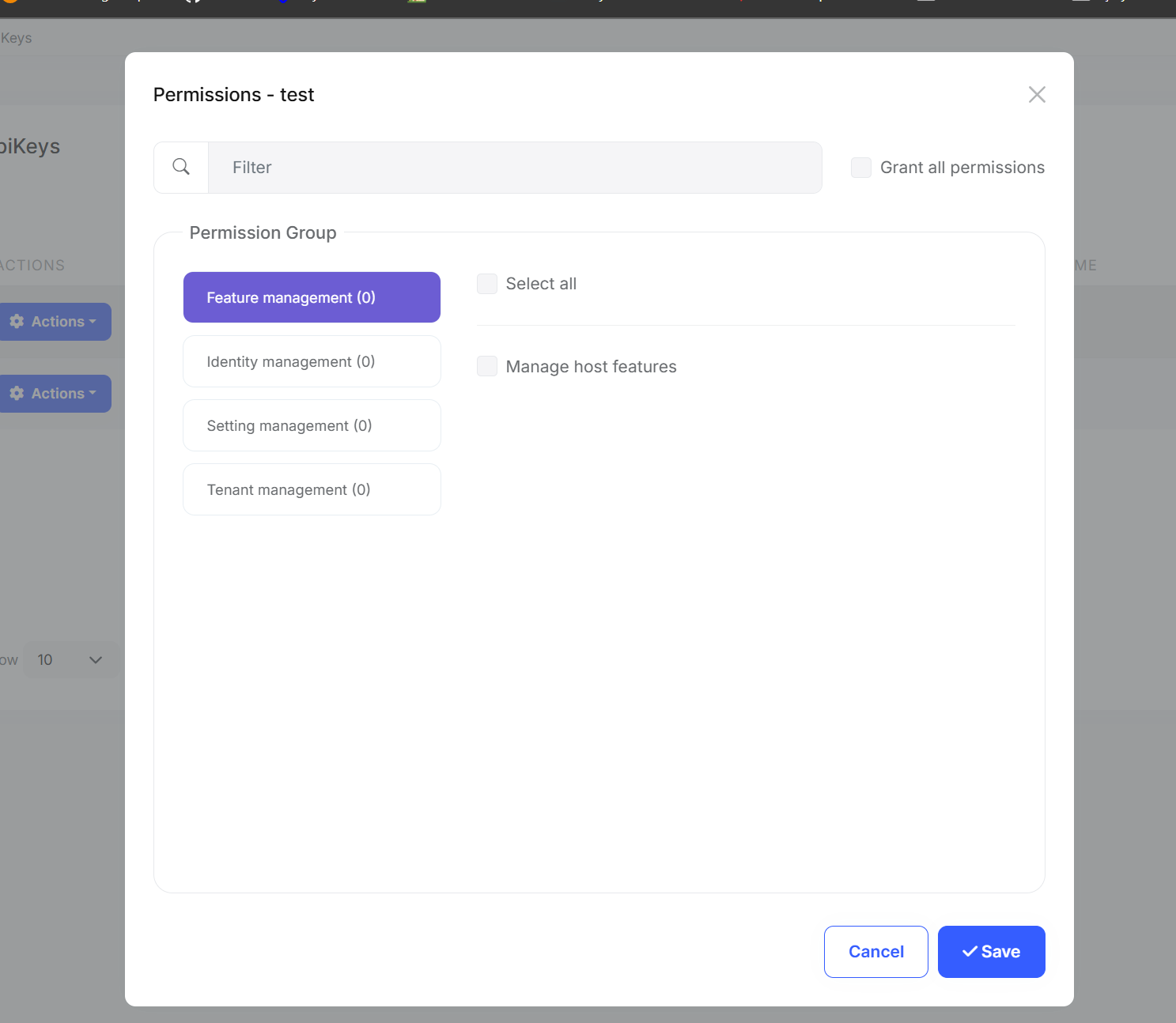 |
||||
|
|
||||
|
This allows scenarios like: |
||||
|
- Read-only API key for reporting tools |
||||
|
- Limited scope keys for third-party integrations |
||||
|
- Service-specific keys with minimal permissions |
||||
|
|
||||
|
```csharp |
||||
|
// Check if current request is authenticated via API key |
||||
|
if (CurrentUser.FindClaim("ApiKeyId") != null) |
||||
|
{ |
||||
|
var apiKeyId = CurrentUser.FindClaim("ApiKeyId").Value; |
||||
|
// Additional API key specific logic |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
## Performance Considerations |
||||
|
|
||||
|
The implementation uses several optimizations: |
||||
|
|
||||
|
**1. Prefix-based indexing**: Database lookups are done by prefix (indexed column), not the full key hash. |
||||
|
|
||||
|
**2. Distributed caching**: API keys are cached after first lookup, dramatically reducing database queries. |
||||
|
|
||||
|
```csharp |
||||
|
// Cache configuration |
||||
|
Configure<AbpDistributedCacheOptions>(options => |
||||
|
{ |
||||
|
options.KeyPrefix = "ApiKey:"; |
||||
|
}); |
||||
|
``` |
||||
|
|
||||
|
**3. Cache invalidation**: When a key is modified or deleted, cache is automatically invalidated. |
||||
|
|
||||
|
**Typical Performance:** |
||||
|
- Cached lookup: **< 5ms** |
||||
|
- Database lookup: **< 50ms** |
||||
|
- Cache hit rate: **~95%** |
||||
|
|
||||
|
## Security Best Practices |
||||
|
|
||||
|
When implementing API key authentication, follow these guidelines: |
||||
|
|
||||
|
✅ **Always use HTTPS** - Never send API keys over unencrypted connections |
||||
|
|
||||
|
✅ **Use different keys per environment** - Separate keys for dev, staging, production |
||||
|
|
||||
|
❌ **Don't log the full key** - Only log the prefix for debugging |
||||
|
|
||||
|
## Getting Started |
||||
|
|
||||
|
The complete source code is available on GitHub: |
||||
|
|
||||
|
**Repository**: [github.com/salihozkara/AbpApikeyManagement](https://github.com/salihozkara/AbpApikeyManagement) |
||||
|
|
||||
|
To integrate it into your ABP project: |
||||
|
|
||||
|
1. Clone or download the repository |
||||
|
2. Add project references to your solution |
||||
|
3. Add module dependencies to your modules |
||||
|
4. Run EF Core migrations to create the database tables |
||||
|
5. Navigate to `/ApiKeyManagement` to start managing keys |
||||
|
|
||||
|
```csharp |
||||
|
// In your Web module |
||||
|
[DependsOn(typeof(ApiKeyManagementWebModule))] |
||||
|
public class YourWebModule : AbpModule |
||||
|
{ |
||||
|
// ... |
||||
|
} |
||||
|
|
||||
|
// In your HttpApi.Host module |
||||
|
[DependsOn(typeof(ApiKeyManagementHttpApiModule))] |
||||
|
public class YourHttpApiHostModule : AbpModule |
||||
|
{ |
||||
|
// ... |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
## Conclusion |
||||
|
|
||||
|
API key authentication remains a crucial part of modern API security, especially for machine-to-machine communication. While it shouldn't replace user authentication methods like OAuth2 for user-facing applications, it's perfect for: |
||||
|
|
||||
|
- Automated scripts and tools |
||||
|
- Service-to-service communication |
||||
|
- Third-party integrations |
||||
|
- Long-lived access without token refresh complexity |
||||
|
|
||||
|
The implementation shown here demonstrates how ABP Framework's modular architecture, DDD principles, and built-in features (multi-tenancy, caching, permissions) can be leveraged to build a production-ready API key management system. |
||||
|
|
||||
|
The solution is open-source and ready to be integrated into your ABP projects. Feel free to explore the code, suggest improvements, or adapt it to your specific needs. |
||||
|
|
||||
|
**Resources:** |
||||
|
- GitHub Repository: [salihozkara/AbpApikeyManagement](https://github.com/salihozkara/AbpApikeyManagement) |
||||
|
- ABP Framework: [abp.io](https://abp.io) |
||||
|
- ABP Documentation: [docs.abp.io](https://abp.io/docs/latest) |
||||
|
|
||||
|
Happy coding! 🚀 |
||||
@ -0,0 +1 @@ |
|||||
|
Learn how to implement API key authentication in ABP Framework applications. This comprehensive guide covers what API keys are, when to use them over OAuth2/JWT, real-world use cases for mobile apps and microservices, and a complete implementation with user-based key management, SHA-256 hashing, permission delegation, and built-in UI. |
||||
{kind=link}
|
After Width: | Height: | Size: 752 KiB |
@ -0,0 +1,322 @@ |
|||||
|
# Signal-Based Forms in Angular 21: Why You’ll Never Miss Reactive Forms Again |
||||
|
|
||||
|
Angular 21 introduces one of the most exciting developments in the modern edition of Angular: **Signal-Based Forms**. Built directly on the reactive foundation of Angular signals, this new experimental API provides a cleaner, more intuitive, strongly typed, and ergonomic approach for managing form state—without the heavy boilerplate of Reactive Forms. |
||||
|
|
||||
|
> ⚠️ **Important:** Signal Forms are *experimental*. |
||||
|
> Their API can change. Avoid using them in critical production scenarios unless you understand the risks. |
||||
|
|
||||
|
Despite this, Signal Forms clearly represent Angular’s future direction. |
||||
|
--- |
||||
|
|
||||
|
## Why Signal Forms? |
||||
|
|
||||
|
Traditionally in Angular, building forms has involved several concerns: |
||||
|
|
||||
|
- Tracking values |
||||
|
- Managing UI interaction states (touched, dirty) |
||||
|
- Handling validation |
||||
|
- Keeping UI and model in sync |
||||
|
|
||||
|
Reactive Forms solved many challenges but introduced their own: |
||||
|
|
||||
|
- Verbosity FormBuilder API |
||||
|
- Required subscriptions (valueChanges) |
||||
|
- Manual cleaning |
||||
|
- Difficult nested forms |
||||
|
- Weak type-safety |
||||
|
|
||||
|
**Signal Forms solve these problems through:** |
||||
|
|
||||
|
1." Automatic synchronization |
||||
|
2." Full type safety |
||||
|
3." Schema-based validation |
||||
|
4." Fine-grained reactivity |
||||
|
5." Drastically reduced boilerplate |
||||
|
6." Natural integration with Angular Signals |
||||
|
|
||||
|
--- |
||||
|
|
||||
|
### 1. Form Models — The Core of Signal Forms |
||||
|
|
||||
|
A **form model** is simply a writable signal holding the structure of your form data. |
||||
|
|
||||
|
```ts |
||||
|
import { Component, signal } from '@angular/core'; |
||||
|
import { form, Field } from '@angular/forms/signals'; |
||||
|
|
||||
|
@Component({ |
||||
|
selector: 'app-login', |
||||
|
imports: [Field], |
||||
|
template: ` |
||||
|
<input type="email" [field]="loginForm.email" /> |
||||
|
<input type="password" [field]="loginForm.password" /> |
||||
|
`, |
||||
|
}) |
||||
|
export class LoginComponent { |
||||
|
loginModel = signal({ |
||||
|
email: '', |
||||
|
password: '', |
||||
|
}); |
||||
|
|
||||
|
loginForm = form(this.loginModel); |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
Calling `form(model)` creates a **Field Tree** that maps directly to your model. |
||||
|
|
||||
|
--- |
||||
|
|
||||
|
### 2. Achieving Full Type Safety |
||||
|
|
||||
|
Although TypeScript can infer types from object literals, defining explicit interfaces provides maximum safety and better IDE support. |
||||
|
|
||||
|
```ts |
||||
|
interface LoginData { |
||||
|
email: string; |
||||
|
password: string; |
||||
|
} |
||||
|
|
||||
|
loginModel = signal<LoginData>({ |
||||
|
email: '', |
||||
|
password: '', |
||||
|
}); |
||||
|
|
||||
|
loginForm = form(loginModel); |
||||
|
``` |
||||
|
|
||||
|
Now: |
||||
|
|
||||
|
- `loginForm.email` → `FieldTree<string>` |
||||
|
- Accessing invalid fields like `loginForm.username` results in compile-time errors |
||||
|
|
||||
|
This level of type safety surpasses Reactive Forms. |
||||
|
|
||||
|
--- |
||||
|
|
||||
|
### 3. Reading Form Values |
||||
|
|
||||
|
#### Read from the model (entire form): |
||||
|
|
||||
|
```ts |
||||
|
onSubmit() { |
||||
|
const data = this.loginModel(); |
||||
|
console.log(data.email, data.password); |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
#### Read from an individual field: |
||||
|
|
||||
|
```html |
||||
|
<p>Current email: {{ loginForm.email().value() }}</p> |
||||
|
``` |
||||
|
|
||||
|
Each field exposes: |
||||
|
|
||||
|
- `value()` |
||||
|
- `valid()` |
||||
|
- `errors()` |
||||
|
- `dirty()` |
||||
|
- `touched()` |
||||
|
|
||||
|
All as signals. |
||||
|
|
||||
|
--- |
||||
|
|
||||
|
### 4. Updating Form Models Programmatically |
||||
|
|
||||
|
Signal Forms allow three update methods. |
||||
|
|
||||
|
#### 1. Replace the entire model |
||||
|
|
||||
|
```ts |
||||
|
this.userModel.set({ |
||||
|
name: 'Alice', |
||||
|
email: 'alice@example.com', |
||||
|
}); |
||||
|
``` |
||||
|
|
||||
|
#### 2. Patch specific fields |
||||
|
|
||||
|
```ts |
||||
|
this.userModel.update(prev => ({ |
||||
|
...prev, |
||||
|
email: newEmail, |
||||
|
})); |
||||
|
``` |
||||
|
|
||||
|
#### 3. Update a single field |
||||
|
|
||||
|
```ts |
||||
|
this.userForm.email().value.set(''); |
||||
|
``` |
||||
|
|
||||
|
This eliminates the need for: |
||||
|
|
||||
|
- `patchValue()` |
||||
|
- `setValue()` |
||||
|
- `formGroup.get('field')` |
||||
|
|
||||
|
--- |
||||
|
|
||||
|
### 5. Automatic Two-Way Binding With `[field]` |
||||
|
|
||||
|
The `[field]` directive enables perfect two-way data binding: |
||||
|
|
||||
|
```html |
||||
|
<input [field]="userForm.name" /> |
||||
|
``` |
||||
|
|
||||
|
#### How it works: |
||||
|
|
||||
|
- **User input → Field state → Model** |
||||
|
- **Model updates → Field state → Input UI** |
||||
|
|
||||
|
No subscriptions. |
||||
|
No event handlers. |
||||
|
No boilerplate. |
||||
|
|
||||
|
Reactive Forms could never achieve this cleanly. |
||||
|
|
||||
|
--- |
||||
|
|
||||
|
### 6. Nested Models and Arrays |
||||
|
|
||||
|
Models can contain nested object structures: |
||||
|
|
||||
|
```ts |
||||
|
userModel = signal({ |
||||
|
name: '', |
||||
|
address: { |
||||
|
street: '', |
||||
|
city: '', |
||||
|
}, |
||||
|
}); |
||||
|
``` |
||||
|
|
||||
|
Access fields easily: |
||||
|
|
||||
|
```html |
||||
|
<input [field]="userForm.address.street" /> |
||||
|
``` |
||||
|
|
||||
|
Arrays are also supported: |
||||
|
|
||||
|
```ts |
||||
|
orderModel = signal({ |
||||
|
items: [ |
||||
|
{ product: '', quantity: 1, price: 0 } |
||||
|
] |
||||
|
}); |
||||
|
``` |
||||
|
|
||||
|
Field state persists even when array items move, thanks to identity tracking. |
||||
|
|
||||
|
--- |
||||
|
|
||||
|
### 7. Schema-Based Validation |
||||
|
|
||||
|
Validation is clean and centralized: |
||||
|
|
||||
|
```ts |
||||
|
import { required, email } from '@angular/forms/signals'; |
||||
|
|
||||
|
const model = signal({ email: '' }); |
||||
|
|
||||
|
const formRef = form(model, { |
||||
|
email: [required(), email()], |
||||
|
}); |
||||
|
``` |
||||
|
|
||||
|
Field validation state is reactive: |
||||
|
|
||||
|
```ts |
||||
|
formRef.email().valid() |
||||
|
formRef.email().errors() |
||||
|
formRef.email().touched() |
||||
|
``` |
||||
|
|
||||
|
Validation no longer scatters across components. |
||||
|
|
||||
|
--- |
||||
|
|
||||
|
### 8. When Should You Use Signal Forms? |
||||
|
|
||||
|
#### New Angular 21+ apps |
||||
|
Signal-first architecture is the new standard. |
||||
|
|
||||
|
#### Teams wanting stronger type safety |
||||
|
Every field is exactly typed. |
||||
|
|
||||
|
#### Devs tired of Reactive Form boilerplate |
||||
|
Signal Forms drastically simplify code. |
||||
|
|
||||
|
#### Complex UI with computed reactive form state |
||||
|
Signals integrate perfectly. |
||||
|
|
||||
|
#### ❌ Avoid if: |
||||
|
- You need long-term stability |
||||
|
- You rely on mature Reactive Forms features |
||||
|
- Your app must avoid experimental APIs |
||||
|
|
||||
|
--- |
||||
|
|
||||
|
### 9. Reactive Forms vs Signal Forms |
||||
|
|
||||
|
| Feature | Reactive Forms | Signal Forms | |
||||
|
|--------|----------------|--------------| |
||||
|
| Boilerplate | High | Very low | |
||||
|
| Type-safety | Weak | Strong | |
||||
|
| Two-way binding | Manual | Automatic | |
||||
|
| Validation | Scattered | Centralized schema | |
||||
|
| Nested forms | Verbose | Natural | |
||||
|
| Subscriptions | Required | None | |
||||
|
| Change detection | Zone-heavy | Fine-grained | |
||||
|
|
||||
|
Signal Forms feel like the "modern Angular mode," while Reactive Forms increasingly feel legacy. |
||||
|
|
||||
|
--- |
||||
|
|
||||
|
### 10. Full Example: Login Form |
||||
|
|
||||
|
```ts |
||||
|
@Component({ |
||||
|
selector: 'app-login', |
||||
|
imports: [Field], |
||||
|
template: ` |
||||
|
<form (ngSubmit)="submit()"> |
||||
|
<input type="email" [field]="form.email" /> |
||||
|
<input type="password" [field]="form.password" /> |
||||
|
<button>Login</button> |
||||
|
</form> |
||||
|
`, |
||||
|
}) |
||||
|
export class LoginComponent { |
||||
|
model = signal({ email: '', password: '' }); |
||||
|
form = form(this.model); |
||||
|
|
||||
|
submit() { |
||||
|
console.log(this.model()); |
||||
|
} |
||||
|
} |
||||
|
``` |
||||
|
|
||||
|
Minimal. Reactive. Completely type-safe. |
||||
|
|
||||
|
--- |
||||
|
|
||||
|
## **Conclusion** |
||||
|
|
||||
|
Signal Forms in Angular 21 represent a big step forward: |
||||
|
|
||||
|
- Cleaner API |
||||
|
- Stronger type safety |
||||
|
- Automatic two-way binding |
||||
|
- Centralized validation |
||||
|
- Fine-grained reactivity |
||||
|
- Dramatically better developer experience |
||||
|
|
||||
|
|
||||
|
Although these are experimental, they clearly show the future of Angular's form ecosystem. |
||||
|
Once you get into using Signal Forms, you may never want to use Reactive Forms again. |
||||
|
|
||||
|
--- |
||||
@ -0,0 +1,25 @@ |
|||||
|
**ABP Black Friday Deals are Almost Here\!** |
||||
|
|
||||
|
The season of huge savings is back\! We are happy to announce **ABP Black Friday Campaign**, packed with exclusive deals that you simply won't want to miss. Whether you are ready to start building with ABP or looking to expand your existing license, this is your chance to maximize your savings\! |
||||
|
|
||||
|
**Campaign Dates: Mark Your Calendar** |
||||
|
|
||||
|
Black Friday campaign is live for one week only\! Our deals run from: **November 24th \- December 1st.** |
||||
|
|
||||
|
Don't miss this limited-time opportunity to **save up to $3,000** and take your software development to the next level. |
||||
|
|
||||
|
**What's Included in the ABP Black Friday Campaign?** |
||||
|
|
||||
|
Here’s why this campaign is the best time to buy or upgrade: |
||||
|
|
||||
|
* Open to Everyone: This campaign is available for both new and existing customers. |
||||
|
* Stack Your Savings: You can combine this Black Friday offer with our multi-year discounts for the greatest possible value. |
||||
|
* Flexible Upgrades: Planning to upgrade to a higher package? Now is the perfect time to make that move at a lower cost. |
||||
|
* More Developer Seats? No Problem\! Additional developer seats are also eligible under this campaign, allowing you to grow your team effortlessly and affordably. |
||||
|
|
||||
|
**Save Money Now\!** |
||||
|
|
||||
|
This campaign is your best opportunity all year to unlock advanced features, scale your team, or upgrade your plan while **saving up to $3,000.** Secure your savings before the campaign ends on December 1st\! |
||||
|
|
||||
|
[**Visit Pricing Page to Explore Offers\!**](https://abp.io/pricing) |
||||
|
|
||||
@ -0,0 +1,149 @@ |
|||||
|
# What’s New in .NET 10 Libraries and Runtime? |
||||
|
|
||||
|
With .NET 10, Microsoft continues to evolve the platform toward higher performance, stronger security, and modern developer ergonomics. This release brings substantial updates across both the **.NET Libraries** and the **.NET Runtime**, making everyday development faster, safer, and more efficient. |
||||
|
|
||||
|
|
||||
|
|
||||
|
------ |
||||
|
|
||||
|
## .NET Libraries Improvements |
||||
|
|
||||
|
### 1. Post-Quantum Cryptography |
||||
|
|
||||
|
.NET 10 introduces support for new **quantum-resistant algorithms**, ML-KEM, ML-DSA, and SLH-DSA, through the `System.Security.Cryptography` namespace. |
||||
|
These are available when running on compatible OS versions (OpenSSL 3.5+ or Windows CNG). |
||||
|
|
||||
|
**Why it matters:** This future-proofs .NET apps against next-generation security threats, keeping them aligned with emerging FIPS standards and PQC readiness. |
||||
|
|
||||
|
|
||||
|
|
||||
|
------ |
||||
|
|
||||
|
### 2. Numeric Ordering for String Comparison |
||||
|
|
||||
|
The `StringComparer` and `HashSet` classes now support **numeric-aware string comparison** via `CompareOptions.NumericOrdering`. |
||||
|
This allows natural sorting of strings like `v2`, `v10`, `v100`. |
||||
|
|
||||
|
**Why it matters:** Cleaner and more intuitive sorting for version names, product codes, and other mixed string-number data. |
||||
|
|
||||
|
|
||||
|
|
||||
|
------ |
||||
|
|
||||
|
### 3. String Normalization for Spans |
||||
|
|
||||
|
Normalization APIs now support `Span<char>` and `ReadOnlySpan<char>`, enabling text normalization without creating new string objects. |
||||
|
|
||||
|
**Why it matters:** Lower memory allocations in text-heavy scenarios, perfect for parsers, libraries, and streaming data pipelines. |
||||
|
|
||||
|
|
||||
|
|
||||
|
------ |
||||
|
|
||||
|
### 4. UTF-8 Support for Hex String Conversion |
||||
|
|
||||
|
The `Convert` class now allows **direct UTF-8 to hex conversions**, eliminating the need for intermediate string allocations. |
||||
|
|
||||
|
**Why it matters:** Faster serialization and deserialization, especially useful in networking, cryptography, and binary protocols. |
||||
|
|
||||
|
|
||||
|
|
||||
|
------ |
||||
|
|
||||
|
### 5. Async ZIP APIs |
||||
|
|
||||
|
ZIP handling now fully supports asynchronous operations, from creation and extraction to updates, with cancellation support. |
||||
|
|
||||
|
**Why it matters:** Ideal for real-time applications, WebSocket I/O, and microservices that handle compressed data streams. |
||||
|
|
||||
|
|
||||
|
|
||||
|
------ |
||||
|
|
||||
|
### 6. ZipArchive Performance Boost |
||||
|
|
||||
|
ZIP operations are now faster and more memory-efficient thanks to parallel extraction and reduced memory pressure. |
||||
|
|
||||
|
**Why it matters:** Perfect for file-heavy workloads like installers, packaging tools, and CI/CD utilities. |
||||
|
|
||||
|
------ |
||||
|
|
||||
|
|
||||
|
|
||||
|
### 7. TLS 1.3 Support on macOS |
||||
|
|
||||
|
.NET 10 brings **TLS 1.3 client support** to macOS using Apple’s `Network.framework`, integrated with `SslStream` and `HttpClient`. |
||||
|
|
||||
|
**Why it matters:** Consistent, faster, and more secure HTTPS connections across Windows, Linux, and macOS. |
||||
|
|
||||
|
|
||||
|
|
||||
|
------ |
||||
|
|
||||
|
### 8. Telemetry Schema URLs |
||||
|
|
||||
|
`ActivitySource` and `Meter` now support **telemetry schema URLs**, aligning with OpenTelemetry standards. |
||||
|
|
||||
|
**Why it matters:** Simplifies integration with observability platforms like Grafana, Prometheus, and Application Insights. |
||||
|
|
||||
|
|
||||
|
|
||||
|
------ |
||||
|
|
||||
|
### 9. OrderedDictionary Performance Improvements |
||||
|
|
||||
|
New overloads for `TryAdd` and `TryGetValue` improve performance by returning entry indexes directly. |
||||
|
|
||||
|
**Why it matters:** Up to 20% faster JSON updates and more efficient dictionary operations, particularly in `JsonObject`. |
||||
|
|
||||
|
|
||||
|
|
||||
|
------ |
||||
|
|
||||
|
## .NET Runtime Improvements |
||||
|
|
||||
|
|
||||
|
|
||||
|
### 1. JIT Compiler Enhancements |
||||
|
|
||||
|
- **Faster Struct Handling:** The JIT now passes structs directly via CPU registers, reducing memory operations. |
||||
|
*→ Result: Faster execution and tighter loops.* |
||||
|
|
||||
|
- **Array Interface Devirtualization:** Loops like `foreach` over arrays are now almost as fast as `for` loops. |
||||
|
*→ Result: Fewer abstraction costs and better inlining.* |
||||
|
|
||||
|
- **Improved Code Layout:** A new 3-opt heuristic arranges “hot” code paths closer in memory. |
||||
|
*→ Result: Better branch prediction and CPU cache performance.* |
||||
|
|
||||
|
- **Smarter Inlining:** The JIT can now inline more method types (even with `try-finally`), guided by runtime profiling. |
||||
|
*→ Result: Reduced overhead for frequently called methods.* |
||||
|
|
||||
|
|
||||
|
|
||||
|
------ |
||||
|
|
||||
|
### 2. Stack Allocation Improvements |
||||
|
|
||||
|
.NET 10 extends stack allocation to **small arrays of both value and reference types**, with **escape analysis** ensuring safe allocation. |
||||
|
|
||||
|
**Why it matters:** Fewer heap allocations mean less GC work and faster execution, especially in high-frequency or temporary operations. |
||||
|
|
||||
|
|
||||
|
|
||||
|
------ |
||||
|
|
||||
|
### 3. ARM64 Write-Barrier Optimization |
||||
|
|
||||
|
The garbage collector’s write-barrier logic is now optimized for ARM64, cutting unnecessary memory scans. |
||||
|
|
||||
|
**Why it matters:** Up to **20% shorter GC pauses** and better overall performance on ARM-based devices and servers. |
||||
|
|
||||
|
|
||||
|
|
||||
|
|
||||
|
|
||||
|
## Summary |
||||
|
|
||||
|
.NET 10 doubles down on **performance, efficiency, and modern standards**. From quantum-ready cryptography to smarter memory management and diagnostics, this release makes .NET more ready than ever for the next generation of applications. |
||||
|
|
||||
|
Whether you’re building enterprise APIs, distributed systems, or cloud-native tools, upgrading to .NET 10 means faster code, safer systems, and better developer experience. |
||||
@ -0,0 +1,158 @@ |
|||||
|
# My First Look and Experience with Google AntiGravity |
||||
|
|
||||
|
## Is Google AntiGravity Going to Replace Your Main Code Editor? |
||||
|
|
||||
|
Today, I tried the new code-editor AntiGravity by Google. *"It's beyond a code-editor*" by Google 🙄 |
||||
|
When I first launch it, I see the UI is almost same as Cursor. They're both based on Visual Studio Code. |
||||
|
That's why it was not hard to find what I'm looking for. |
||||
|
|
||||
|
First of all, the main difference as I see from the Cursor is; when I type a prompt in the agent section **AntiGravity first creates a Task List** (like a road-map) and whenever it finishes a task, it checks the corresponding task. Actually Cursor has a similar functionality but AntiGravity took it one step further. |
||||
|
|
||||
|
Second thing which was good to me; AntiGravity uses [Nano Banana 🍌](https://gemini.google/tr/overview/image-generation/). This is Google's AI image generation model... Why it's important because when you create an app, you don't need to search for graphics, deal with image licenses. **AntiGravity generates images automatically and no license is required!** |
||||
|
|
||||
|
Third exciting feature for me; **AntiGravity is integrated with Google Chrome and can communicate with the running website**. When I first run my web project, it installed a browser extension which can see and interact with my website. It can see the results, click somewhere else on the page, scroll, fill up the forms, amazing 😵 |
||||
|
|
||||
|
Another feature I loved is that **you can enter a new prompt even while AntiGravity is still generating a response** 🧐. It instantly prioritizes the latest input and adjusts the ongoing process if needed. But in Cursor, if you add a prompt before the cursor finishes, it simply queues it and runs it later 😔. |
||||
|
|
||||
|
And lastly, **AntiGravity is working very good with Gemini 3**. |
||||
|
|
||||
|
Well, everything was not so perfect 😥 When I tried AntiGravity, couple of times it stucked AI generation and Agent stopped. I faced errors like this 👇 |
||||
|
|
||||
|
 |
||||
|
|
||||
|
|
||||
|
|
||||
|
## Debugging .NET Projects via AntiGravity |
||||
|
|
||||
|
⚠ There's a crucial development issue with AntiGravity (and also for Cursor, Windsurf etc...) 🤕 you **cannot debug your .NET application with AntiGravity 🥺.** *This is Microsoft's policy!* Microsoft doesn't allow debugging for 3rd party IDEs and shows the below error... That's why I cannot say it's a downside of AntiGravity. You need to use Microsft's original VS Code, Visual Studio or Rider for debugging. But wait a while there's a workaround for this, I'll let you know in the next section. |
||||
|
|
||||
|
|
||||
|
|
||||
|
 |
||||
|
|
||||
|
### What does this error mean? |
||||
|
|
||||
|
AntiGravity, Cursor, Windsurf etc... are using Visual Studio Code and the C# extension for VS Code includes the Microsoft .NET Core Debugger "*vsdbg*". |
||||
|
VS Code is open-source but "*vsdbg*" is not open-source! It's working only with Visual Studio Code, Visual Studio and Visual Studio for Mac. This is clearly stated at [Microsoft's this link](https://github.com/dotnet/vscode-csharp/blob/main/docs/debugger/Microsoft-.NET-Core-Debugger-licensing-and-Microsoft-Visual-Studio-Code.md). |
||||
|
|
||||
|
### Ok! How to resolve debugging issue with AntiGravity? and Cursor and Windsurf... |
||||
|
|
||||
|
There's a free C# debugger extension for Visual Studio Code based IDEs that supports AntiGravity, Cursor and Windsurf. The extension name is **C#**. |
||||
|
You can download this free C# debugger extension at 👉 [open-vsx.org/extension/muhammad-sammy/csharp/](https://open-vsx.org/extension/muhammad-sammy/csharp/). |
||||
|
For AntiGravity open Extension window (*Ctrl + Shift + X*) and search for `C#`, there you'll see this extension. |
||||
|
|
||||
|
 |
||||
|
|
||||
|
After installing, I restarted AntiGravity and now I can see the red circle which allows me to add breakpoint on C# code. |
||||
|
|
||||
|
 |
||||
|
|
||||
|
### Another Extension For Debugging .NET Apps on VS Code |
||||
|
|
||||
|
Recently I heard about DotRush extension from the folks. As they say DotRush works slightly faster and support Razor pages (.cshtml files). |
||||
|
Here's the link for DotRush https://github.com/JaneySprings/DotRush |
||||
|
|
||||
|
### Finding Website Running Port |
||||
|
|
||||
|
When you run the web project via C# debugger extension, normally it's not using the `launch.json` therefore the website port is not the one when you start from Visual Studio / Rider... So what's my website's port which I just run now? Normally for ASP.NET Core **the default port is 5000**. You can try navigating to http://localhost:5000/. |
||||
|
Alternatively you can write the below code in `Program.cs` which prints the full address of your website in the logs. |
||||
|
If you do the steps which I showed you, you can debug your C# application via AntiGravity and other VS Code derivatives. |
||||
|
|
||||
|
 |
||||
|
|
||||
|
## How Much is AntiGravity? 💲 |
||||
|
|
||||
|
Currently there's only individual plan is available for personal accounts and that's free 👏! The contents of Team and Enterprise plans and prices are not announced yet. But **Gemini 3 is not free**! I used it with my company's Google Workspace account which we normally pay for Gemini. |
||||
|
|
||||
|
 |
||||
|
|
||||
|
## More About AntiGravity |
||||
|
|
||||
|
There have been many AI assisted IDEs like [Windsurf](https://windsurf.com/), [Cursor](https://cursor.com/), [Zed](https://zed.dev/), [Replit](https://replit.com/) and [Fleet](https://www.jetbrains.com/fleet/). But this time it's different, this is backed by Google. |
||||
|
As you see from the below image AntiGravity, uses a standard grid layout as others based on VS Code editor. |
||||
|
It's very similar to Cursor, Visual Studio, Rider. |
||||
|
|
||||
|
 |
||||
|
|
||||
|
## Supported LLMs 🧠 |
||||
|
|
||||
|
Antigravity offers the below models which supports reasoning: Gemini 3 Pro, Claude Sonnet 4.5, GPT-OSS |
||||
|
|
||||
|
 |
||||
|
|
||||
|
Antigravity uses other models for supportive tasks in the background: |
||||
|
|
||||
|
- **Nano banana**: This is used to generate images. |
||||
|
- **Gemini 2.5 Pro UI Checkpoint**: It's for the browser subagent to trigger browser action such as clicking, scrolling, or filling in input. |
||||
|
- **Gemini 2.5 Flash**: For checkpointing and context summarization, this is used. |
||||
|
- **Gemini 2.5 Flash Lite**: And when it's need to make a semantic search in your code-base, this is used. |
||||
|
|
||||
|
## AntiGravity Can See Your Website |
||||
|
|
||||
|
This makes a big difference from traditional IDEs. AntiGravity's browser agent is taking screenshots of your pages when it needs to check. This is achieved by a Chrome Extension as a tool to the agent, and you can also prompt the agent to take a screenshot of a page. It can iterate on website designs and implementations, it can perform UI Testing, it can monitor dashboards, it can automate routine tasks like rerunning CI. |
||||
|
This is the link for the extension 👉 [chromewebstore.google.com/detail/antigravity-browser-exten/eeijfnjmjelapkebgockoeaadonbchdd](https://chromewebstore.google.com/detail/antigravity-browser-exten/eeijfnjmjelapkebgockoeaadonbchdd). AntiGravity will install this extension automatically on the first run. |
||||
|
|
||||
|
 |
||||
|
|
||||
|
 |
||||
|
|
||||
|
## MCP Integration |
||||
|
|
||||
|
### When Do We Need MCP in a Code Editor? |
||||
|
|
||||
|
Simply if we want to connect to a 3rd party service to complete our task we need MCP. So AntiGravity can connect to your DB and write proper SQL queries or it can pull in recent build logs from Netlify or Heroku. Also you can ask AntiGravity to to connect GitHub for finding the best authentication pattern. |
||||
|
|
||||
|
### AntiGravity Supports These MCP Servers |
||||
|
|
||||
|
Airweave, AlloyDB for PostgreSQL, Atlassian, BigQuery, Cloud SQL for PostgreSQL, Cloud SQL for MySQL, Cloud SQL for SQL Server, Dart, Dataplex, Figma Dev Mode MCP, Firebase, GitHub, Harness, Heroku, Linear, Locofy, Looker, MCP Toolbox for Databases, MongoDB, Neon, Netlify, Notion, PayPal, Perplexity Ask, Pinecone, Prisma, Redis, Sequential Thinking, SonarQube, Spanner, Stripe and Supabase. |
||||
|
|
||||
|
 |
||||
|
|
||||
|
## Agent Settings ⚙️ |
||||
|
|
||||
|
The major settings of Agent are: |
||||
|
|
||||
|
- **Agent Auto Fix Lints**: I enabled this setting because I want the Agent automatically fixes its own mistakes for invalid syntax, bad formatting, unused variables, unreachable code or following coding standards... It makes extra tool calls that's why little bit expensive 🥴. |
||||
|
- **Auto Execution**: Sometimes Agent tries to build application or writing test code and running it, in these cases it executes command. I choose "Turbo" 🤜 With this option, Agent always runs the terminal command and controls my browser. |
||||
|
- **Review Policy**: How much control you are giving to agent 🙎. I choose "Always Proceed" 👌 because I mostly trust AI 😀. The Agent will never ask for review. |
||||
|
|
||||
|
 |
||||
|
|
||||
|
## Differences Between Cursor and AntiGravity |
||||
|
|
||||
|
While Cursor was the champion of AI code editors, **Antigravity brings a different philosophy**. |
||||
|
|
||||
|
### 1. "Agent-First 🤖" vs "You-First 🤠" |
||||
|
|
||||
|
- **Cursor:** It acts like an assistant; it predicts your next move, auto-completes your thoughts, and helps you refactor while you type. You are still the driver; Cursor just drives the car at 200 km/h. |
||||
|
- **Antigravity:** Antigravity is built to let you manage coding tasks. It is "Agent-First." You don't just type code; you assign tasks to autonomous agents (e.g., "Fix the bug in the login flow and verify it in the browser"). It behaves more like a junior developer that you supervise. |
||||
|
|
||||
|
### 2. The Interface |
||||
|
|
||||
|
- **Cursor:** Looks and feels exactly like **VS Code**. If you know VS Code, you know Cursor. |
||||
|
|
||||
|
- **Antigravity:** Introduces 2 major layouts: |
||||
|
- **Editor View:** Similar to a standard IDE |
||||
|
- **Manager View:** A dashboard where you see multiple "Agents" working in parallel. You can watch them plan, execute, and test tasks asynchronously. |
||||
|
|
||||
|
### 3. Verification & Trust |
||||
|
|
||||
|
- **Cursor:** You verify by reading the code diffs it suggests. |
||||
|
- **Antigravity:** Introduces **Artifacts**... Since the agents work autonomously, they generate proof-of-work documents, screenshots of the app running, browser logs and execution plans. So you can verify what they did without necessarily reading every line of code immediately. |
||||
|
|
||||
|
### 4. Capabilities |
||||
|
|
||||
|
- **Cursor:** Best-in-class **Autocomplete** ("Tab" feature) and **Composer** (multi-file editing). It excels at "Vibe Coding". It's getting into a flow state where the AI writes the boilerplate and you direct the logic. |
||||
|
- **Antigravity:** Is good at **Autonomous Execution**. It has a built-in browser and terminal that the *Agent* controls. The Agent can write code, run the server, open the browser, see the error, and fix it 😎 |
||||
|
|
||||
|
### 5. AI Models (Brains 🧠) |
||||
|
|
||||
|
- **Cursor:** Model Agnostic. You can switch between **Claude 3.5 Sonnet** *-mostly the community uses this-*, GPT-4o, and others. |
||||
|
- **Antigravity:** Built deeply around **Gemini 3 Pro**. It leverages Gemini's massive context window (1M+ tokens) to understand huge mono repos without needing as much "RAG" as Cursor. |
||||
|
|
||||
|
|
||||
|
|
||||
|
## Try It Yourself Now 🤝 |
||||
|
|
||||
|
If you are ready to experience the new AI code editor by Google, download and use 👇 |
||||
|
[**Launch Google AntiGravity**](https://antigravity.google/) |
||||
{kind=link}
|
After Width: | Height: | Size: 70 KiB |
{kind=link}
|
After Width: | Height: | Size: 183 KiB |
{kind=link}
|
After Width: | Height: | Size: 62 KiB |
{kind=link}
|
After Width: | Height: | Size: 1.1 MiB |
{kind=link}
|
After Width: | Height: | Size: 90 KiB |
{kind=link}
|
After Width: | Height: | Size: 13 KiB |
{kind=link}
|
After Width: | Height: | Size: 102 KiB |
{kind=link}
|
After Width: | Height: | Size: 293 KiB |
{kind=link}
|
After Width: | Height: | Size: 76 KiB |
{kind=link}
|
After Width: | Height: | Size: 46 KiB |
{kind=link}
|
After Width: | Height: | Size: 13 KiB |
{kind=link}
|
After Width: | Height: | Size: 13 KiB |
{kind=link}
|
After Width: | Height: | Size: 275 KiB |
{kind=link}
|
After Width: | Height: | Size: 49 KiB |
{kind=link}
|
After Width: | Height: | Size: 154 KiB |
{kind=link}
|
After Width: | Height: | Size: 5.4 KiB |
{kind=link}
|
After Width: | Height: | Size: 6.3 KiB |
{kind=link}
|
After Width: | Height: | Size: 6.0 KiB |
{kind=link}
|
After Width: | Height: | Size: 4.8 KiB |
{kind=link}
|
After Width: | Height: | Size: 7.2 KiB |
{kind=link}
|
After Width: | Height: | Size: 3.1 KiB |